1 入门
本章节将带领大家安装部署MEMS,并运行第一个应用。
1.1 产品介绍
微能量管理系统(‘Micro’ Energy Manage System, MEMS),可适配储能、光伏、燃机等多种能源的全生命周期的运营管理,结合个性化应用场景,实现多能综合优化调度;适配市面主流设备,具备即插即用能力;实现海量数据存储,支持多维管控方式。相比于同类产品,其具有强大的技术优势:
-
灵活适配的软件定义架构,降低定制化改造成本。针对传统多能系统(电、热、冷、气)因设备异构、场景多元导致的重复编程与定制开发问题,MEMS构建了软件定义的信息物理模型,将复杂的能源调控逻辑解构为可配置的DataFrame流(DataFrame Flow, DFF)计算图。在面对不同用能场景或设备变更时,无需修改底层程序代码,仅通过调整配置参数与计算节点组合即可完成系统重构,显著提升了对多场景业务的适应性与部署效率。
-
统一的数据与计算范式,消除异构系统壁垒。将电网、热网、信息系统及业务数据统一抽象为多维数据结构,实现了信息流与能量流的同构化处理。打通了不同能源介质之间的数据壁垒,确保了物理设备状态与上层业务逻辑在同一框架下的无缝映射与协同。
-
内置高阶数学求解能力,降低运行分析与调控门槛。针对多能流计算、优化调度等环节对复杂数学求解器的依赖问题,MEMS通过内置了混合整数规划、智能算法模型等,实现了计算引擎与问题建模的解耦。用户仅需关注业务逻辑描述,无需具备深层算法开发能力,即可便捷获取高精度能流计算结果与优化调控策略。
-
多机制驱动的响应逻辑,提升系统自治与协同水平。MEMS支持周期驱动、事件驱动及数据源变化驱动等多触发机制,满足了多能系统中状态变量强关联、响应时效要求高的特点,保障了能源系统在动态环境下的实时感知、精准分析与主动调节能力。
随着分布式新能源占比的不断提升和用户侧需求的日益多样化,传统微电网EMS在软硬件集成、部署效率、策略开发、边缘决策等诸多方面暴露出不足。MEMS能够有效解决传统微电网EMS在应用上的不足。MEMS是一种将数据采集与监视、分析、调度、控制、管理等功能集成于单一设备的微电网能量管理系统,基于全链路组态技术,呈现自定义业务流、嵌入式架构、低代码策略、可视化交互四大突出特点,支持快速部署与高效运行,适用于多场景微电网。
MEMS实现的能量管理全链路组态是一种通过无代码或低代码方式实现全过程功能配置的技术手段,可有效提高系统开发效率、降低部署成本。MEMS全链路组态架构包括业务组态、设备组态、测点组态、控制组态与图形组态5个核心模块,分别对应自定义业务流、设备管理、状态感知、策略执行、用户交互5大功能环节,覆盖微电网能量管理全过程,形成数据流、业务流、控制流一体化逻辑闭环。
- 业务组态:基于DFF实现通用化的业务流建模,支持通过DFF配置实现基础数据处理、张量运算、线性/非线性方程组求解、线性/非线性规划、混合整数线性规划、人工智能计算在内的各类算法,可实现负荷预测、电网络分析、潮流计算、状态估计等各类业务逻辑。
- 设备组态:支持接入边缘侧低代码控制器并进行管理;支持自定义设备属性,通过将设备与属性关联从而定义设备属性,实现设备和属性定义的逻辑分离,避免了属性重复定义,保证不同设备共有属性含义一致性,提升设备台账管理清晰度、通用性和可扩展性。
- 测点组态:将量测数据与计算变量配置为标准测点,统一格式并通过嵌入式NoSQL数据库快速读写,直接与硬件交互,适用于嵌入式场景。
- 控制组态:基于混成控制理论,通过边活动网络组合事件与动作构建控制策略,并以事件驱动方式执行、以自动微分技术优化求解,内置混合整数线性规划、非线性规划优化求解器,能够支持复杂控制策略执行,支持策略图形化建模与在线动态调整。
- 图形组态:基于Web前端实现拖拽式可视化配置,支持系统监控、策略执行展示与报表生成,提供个性化功能定制接口,降低二次开发难度。
MEMS除了具备完整的能量管理系统功能,特别还具备通用化的业务配置能力,支持在轻量级嵌入式硬件中部署,真正实现了即插即用的嵌入式EMS技术,是目前市面上唯一微电网能量管理可批量粘贴复制推广的产品化方案,可适用于微电网、储能电站、光伏电站、虚拟电厂等各类能量管理场景。
相关信息
- bilibili产品主页:极简物控
- 抖音官方账号:极简物控(67222285201)
- 微信公众号:极简物控
- QQ技术交流群:极简物控官方技术交流群(560683174)
产品定制请联系淘宝客服或QQ群管理员。
1.2 运行第一个MEMS应用
将您的MEMS与监控设备置于同一局域网内。
在浏览器中输入MEMS设备的IP地址,您会看到以下界面,请稍等片刻以供MEMS加载相关服务。
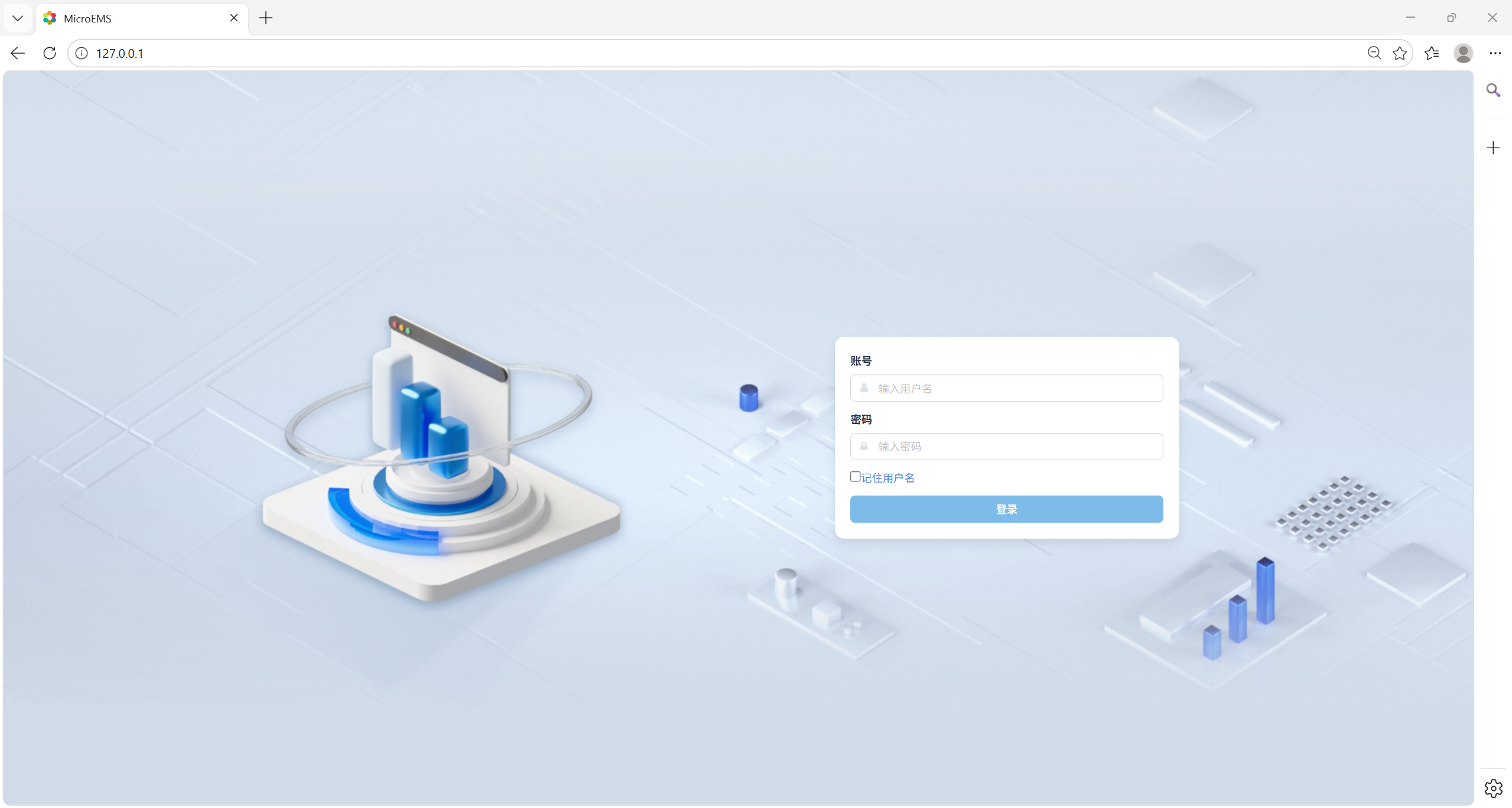
输入用户名密码进入MEMS概览界面。鼠标置于界面右上角账户名处,在显示的下拉菜单中点击编辑模式,进入编辑模式。
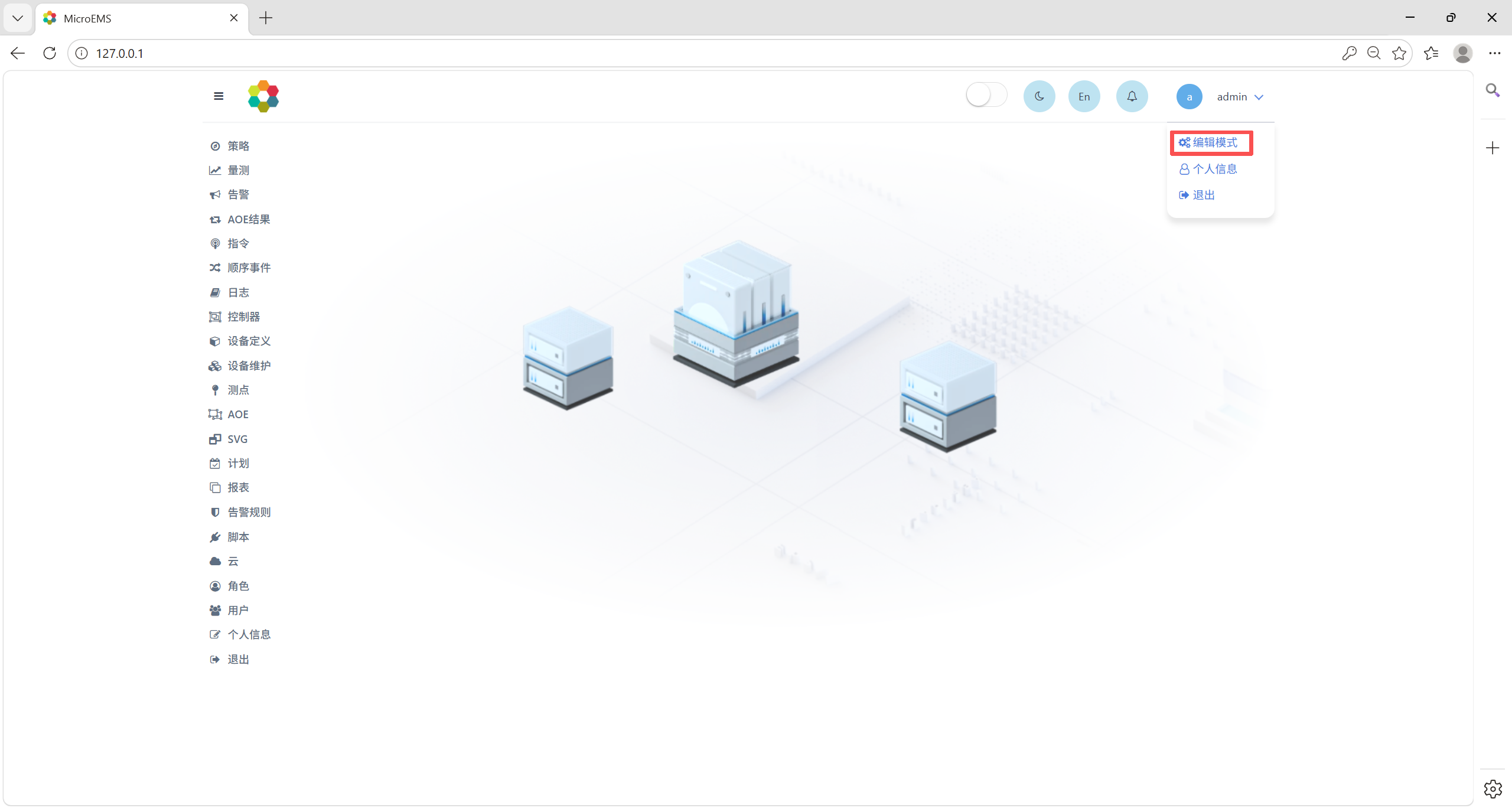
在编辑模式下,点击左侧菜单中设置项-报表,进入DFF配置页面,单击上传文件,即可上传配置文件添加文件。MEMS允许用户上传多个配置文件。同理可上传测点、AOE、SVG、计划、告警规则、脚本等配置文件。
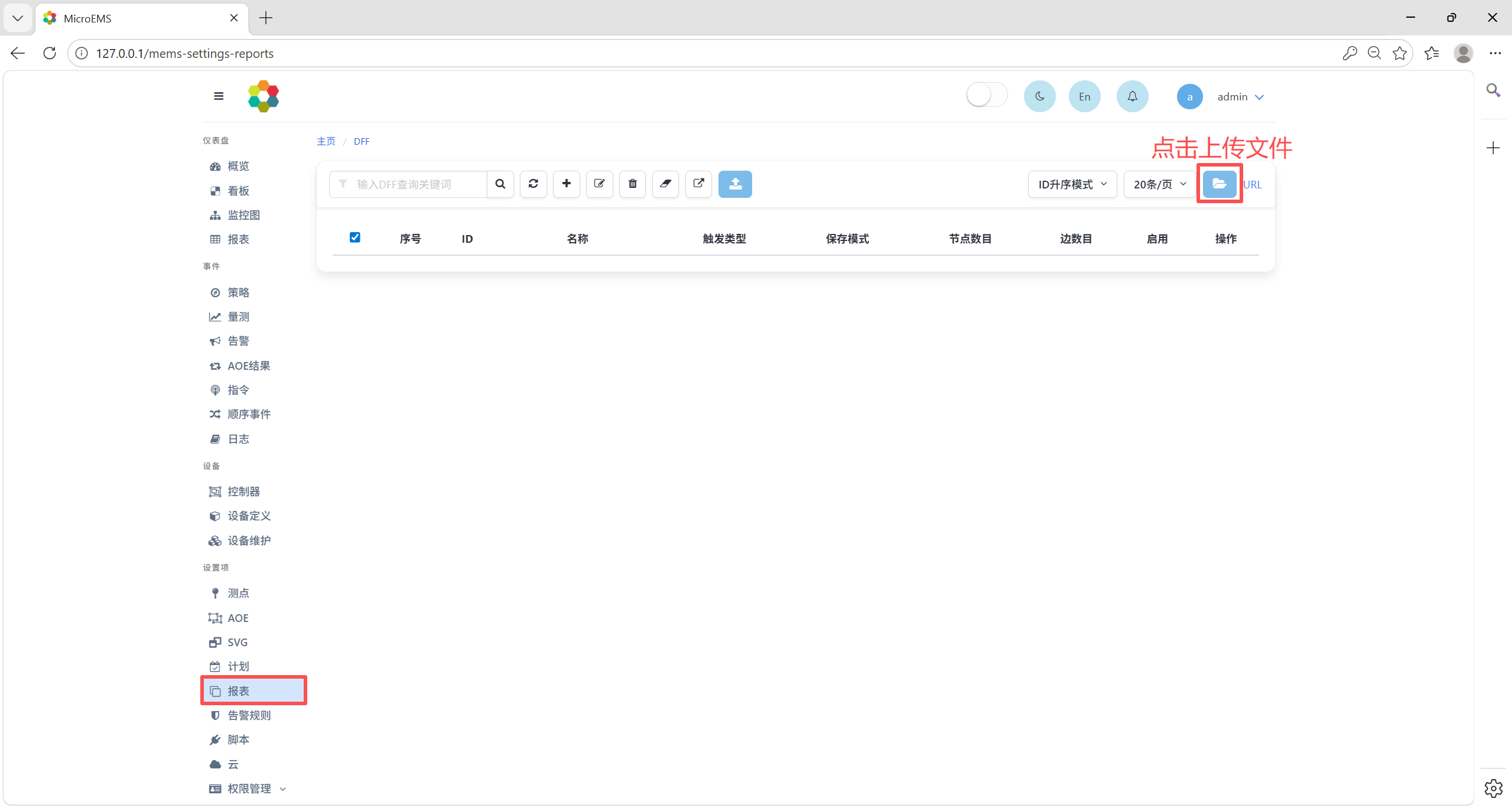
上传示例’test_dff’报表文件,报表页面中将增加一条DFF记录。然后点击左侧菜单中事件-策略,进入策略监控页面。
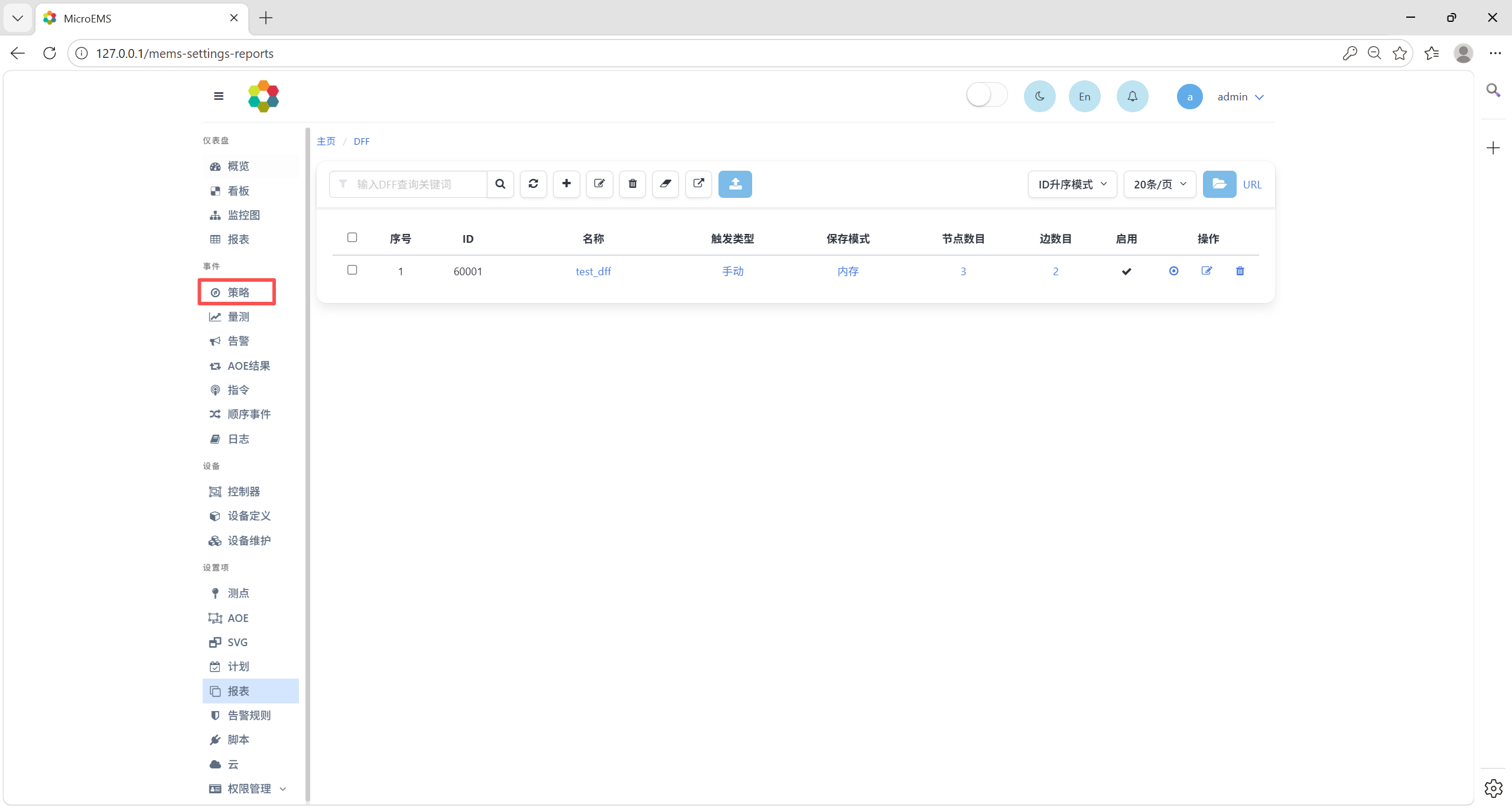
点击系统信息和DFFs按钮,显示系统信息和DFF信息。
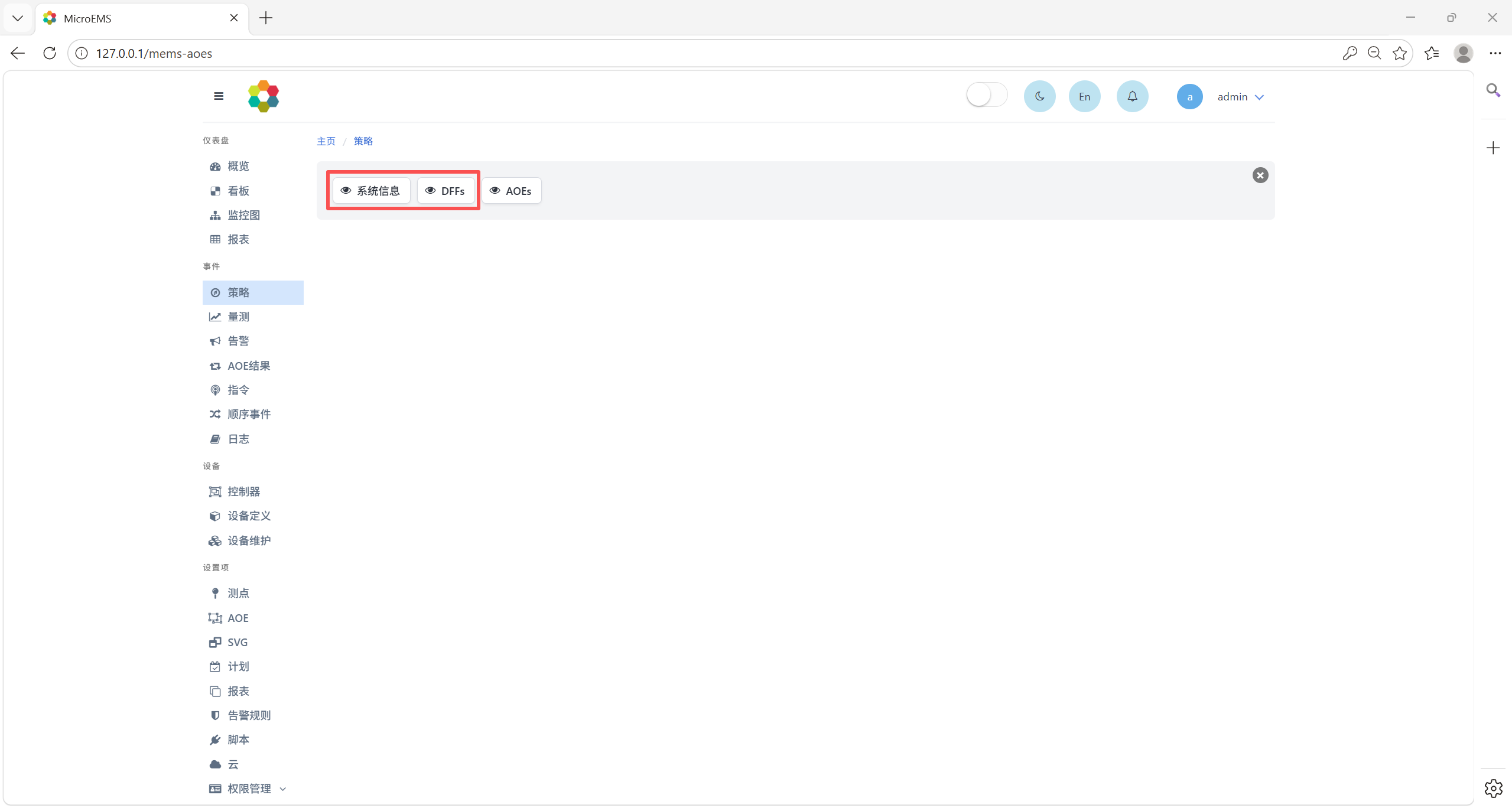
先点击重置按钮,再点击启动按钮。
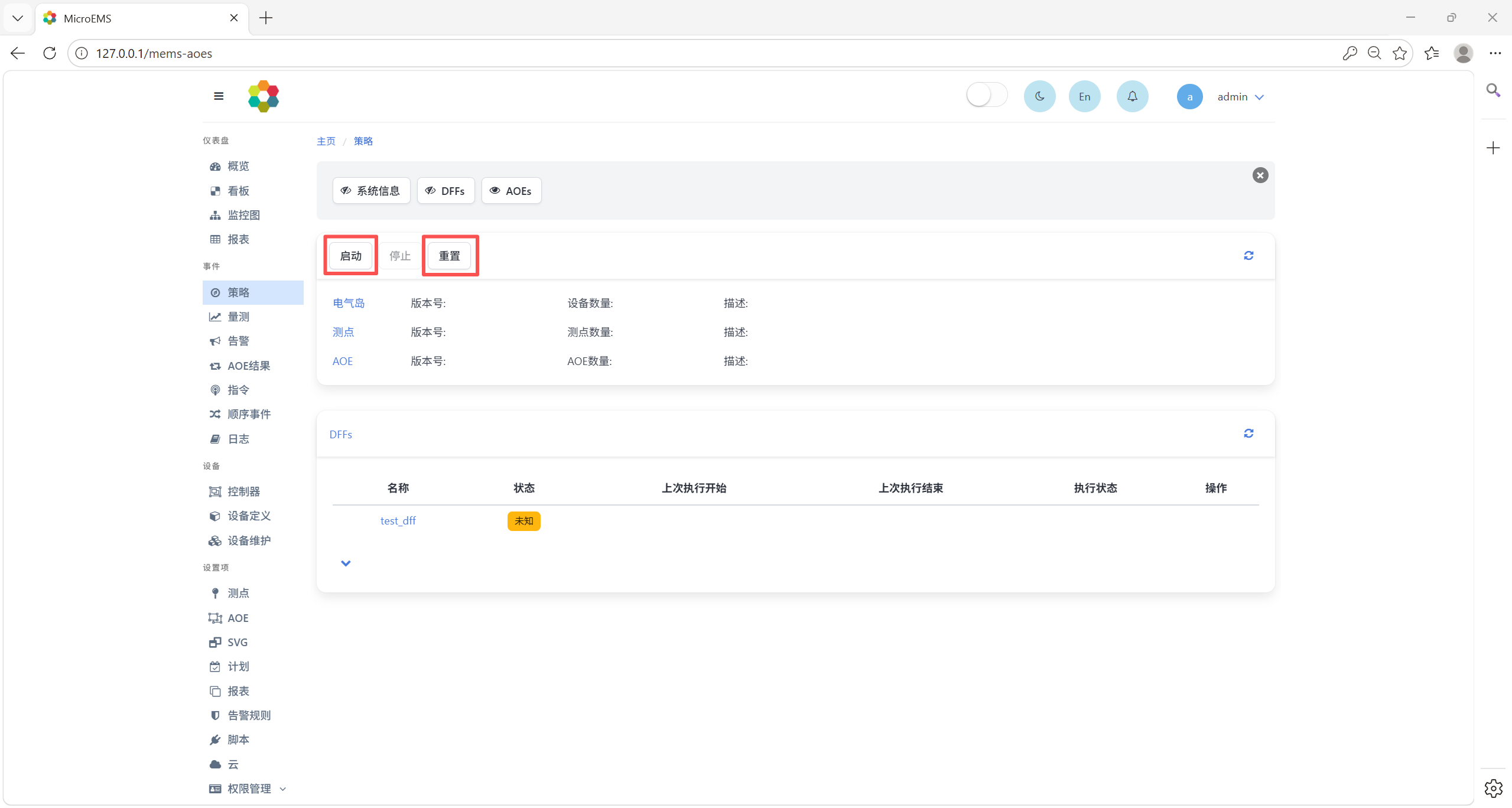
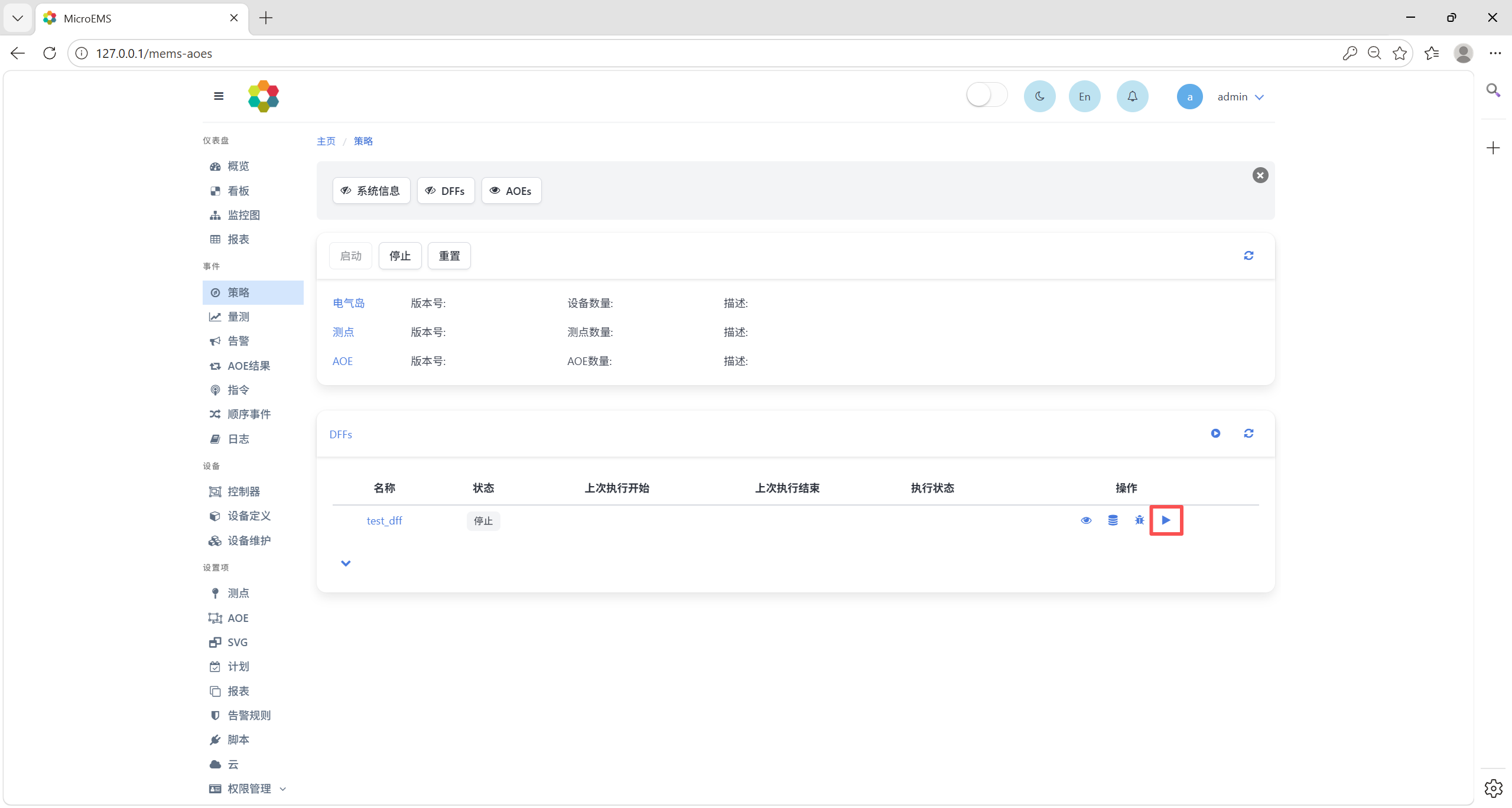
然后点击DFF运行按钮,运行DFF。
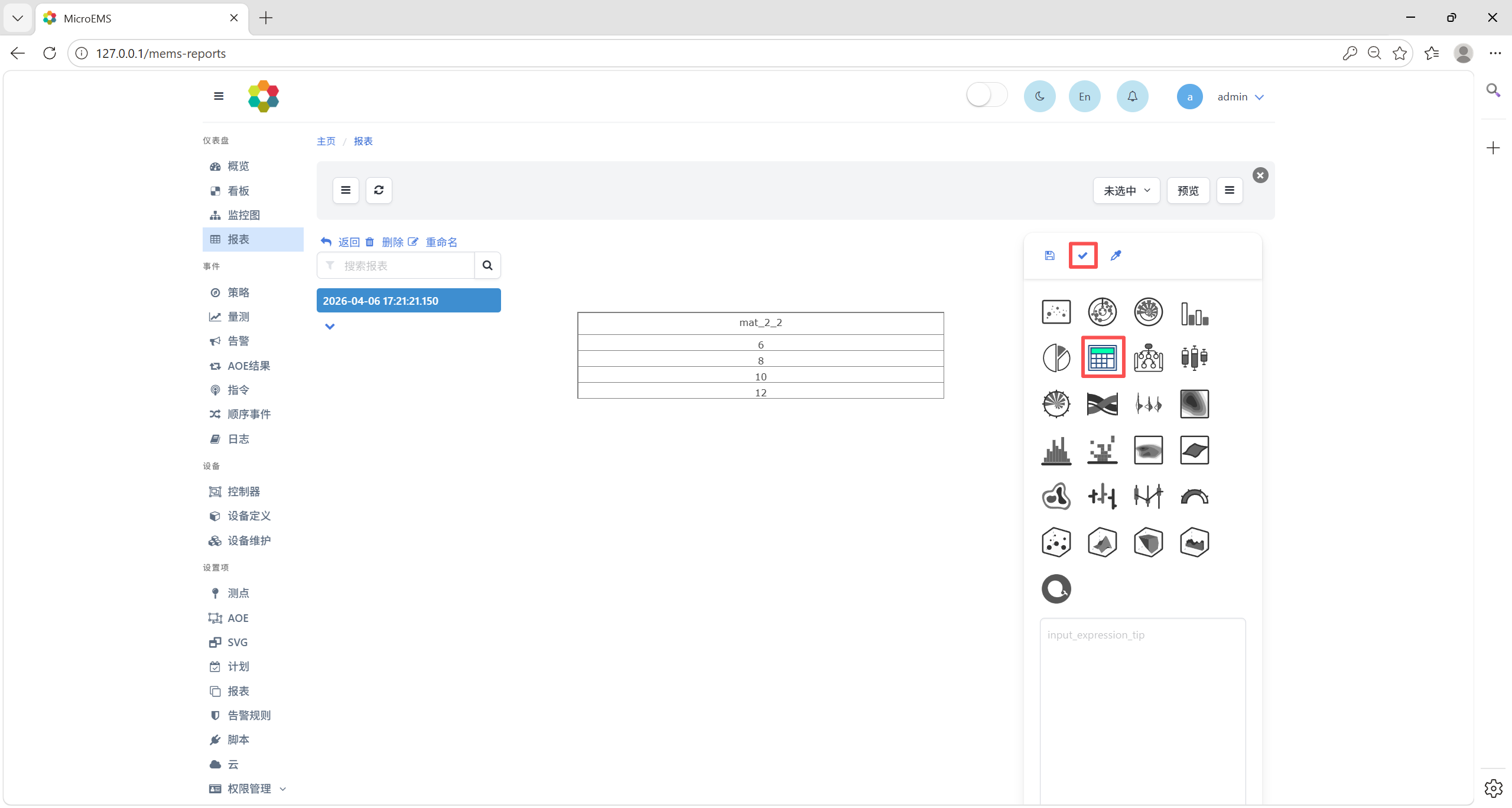
可在仪表盘-报表中查看DFF运行结果,选择Table模板展示DFF输出结果,如下图所示。
1.3 监控你的MEMS运行
输入用户名密码进入MEMS概览界面。鼠标置于界面右上角账户名处,在显示的下拉菜单中点击浏览模式,进入浏览模式,以监控MEMS运行。
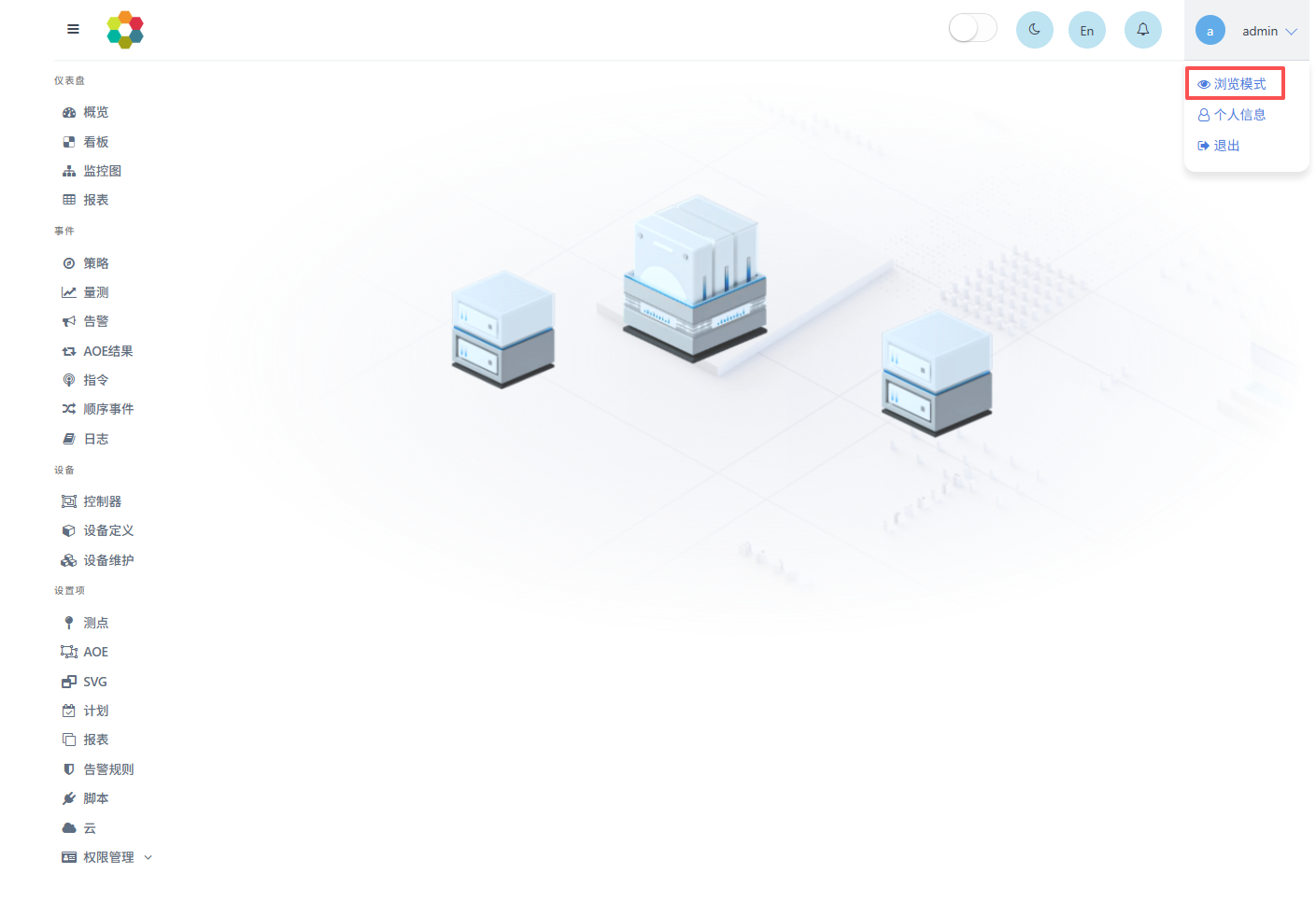
在浏览模式下,点击左侧菜单中策略,进入策略监控页面。策略监控界面可以选择是否显示系统信息、DFFs、AOEs三个子模块。系统信息:可以控制MEMS的启停与重置,并显示电气岛、测点和AOE基本信息;DFFs:该模块显示DFF运行状态、执行时间等信息,点击DFF名称可以查看其具体配置内容,点击执行状态可以查看其执行结果,在操作栏可以进行启停、调试等操作;AOEs:该模块显示AOE运行状态、执行时间等信息,点击AOE名称可以查看其具体配置内容,在操作栏可以进行启停操作。
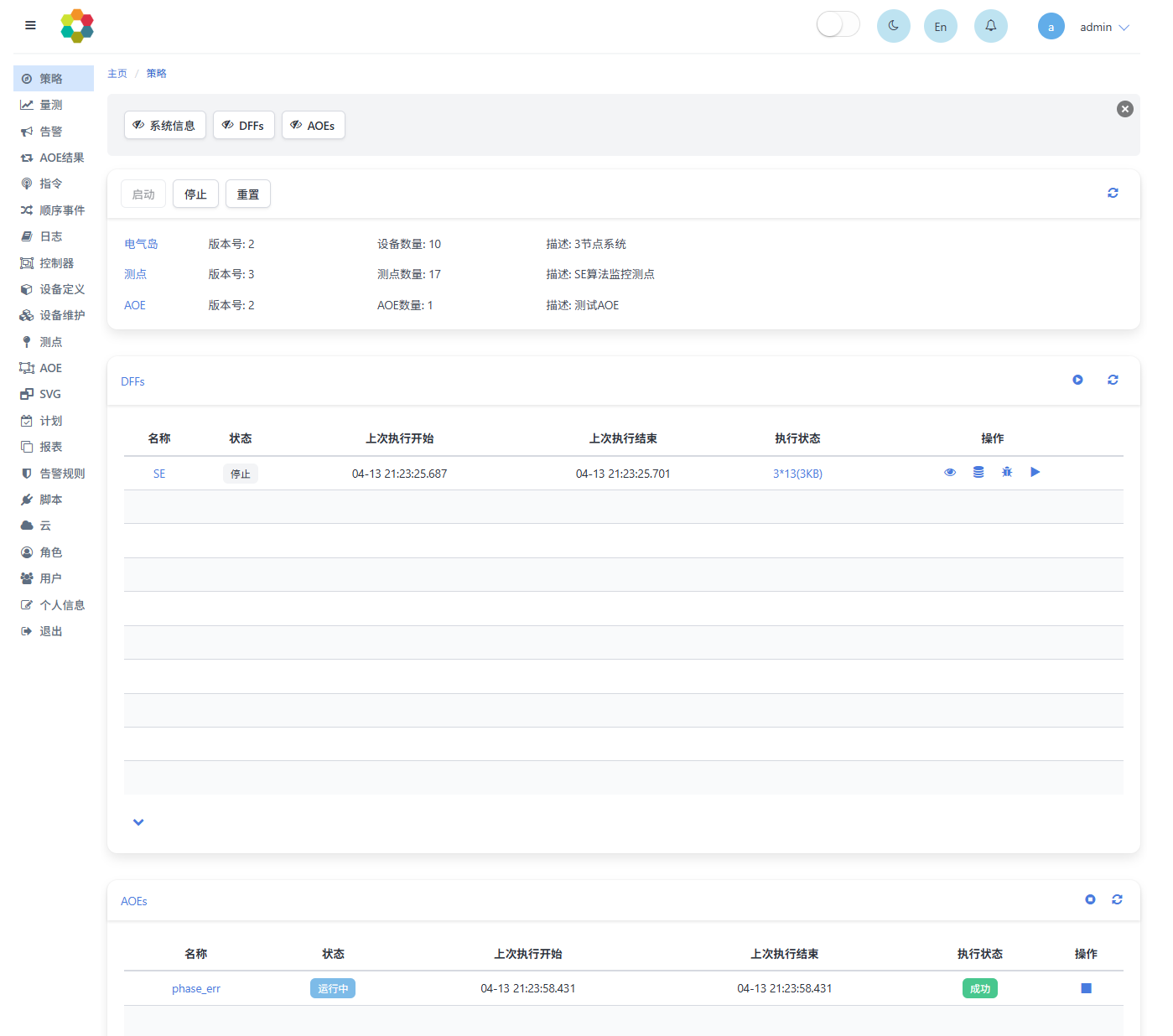
点击左侧菜单中量测,进入量测监控页面。点击设点按钮可对测点进行赋值操作,点击报表和曲线按钮可在网页上方显示数据报表及走势图。
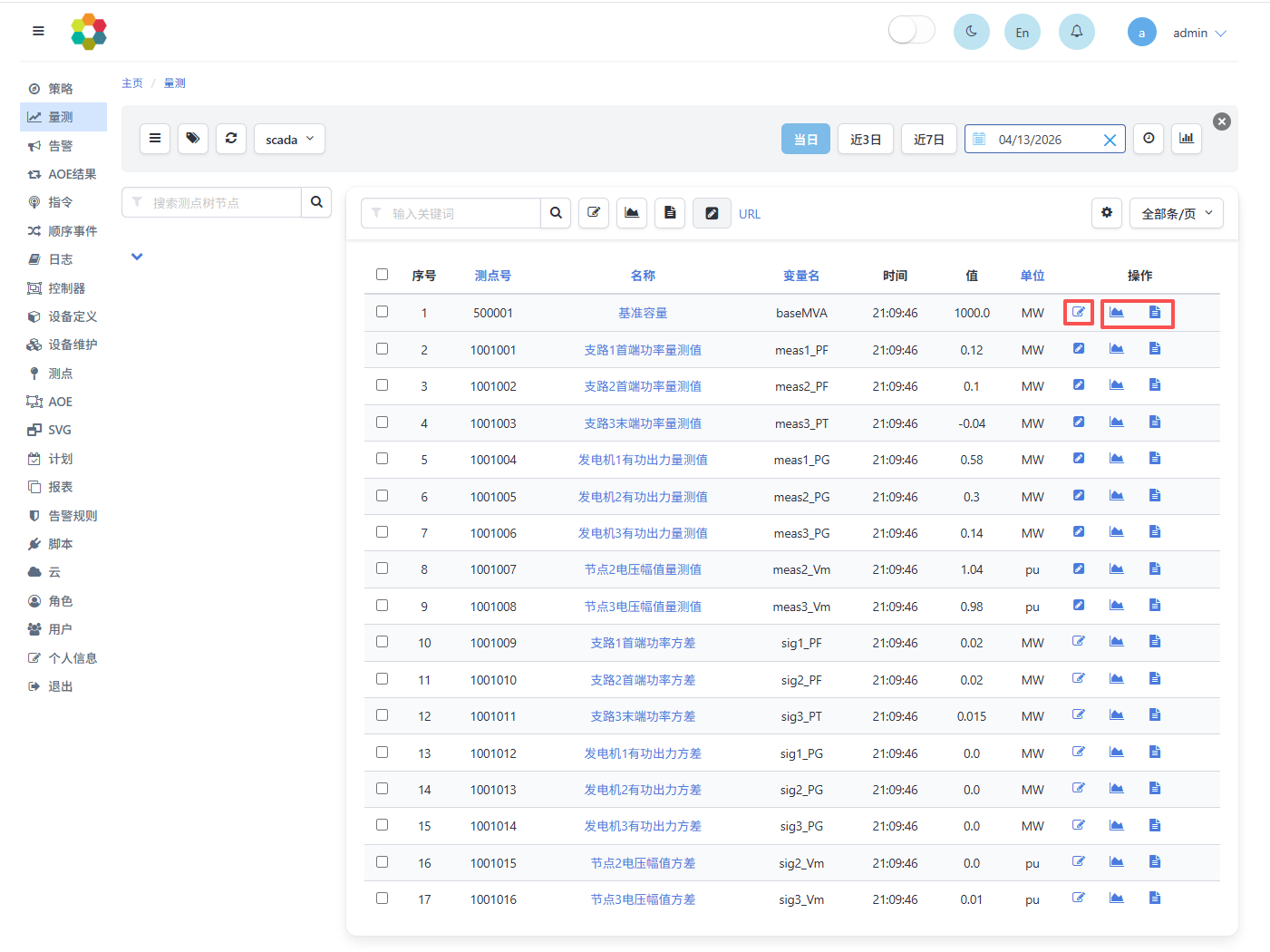
点击左侧菜单中告警页面,可以观测系统的告警信息,并对其进行确认等操作。
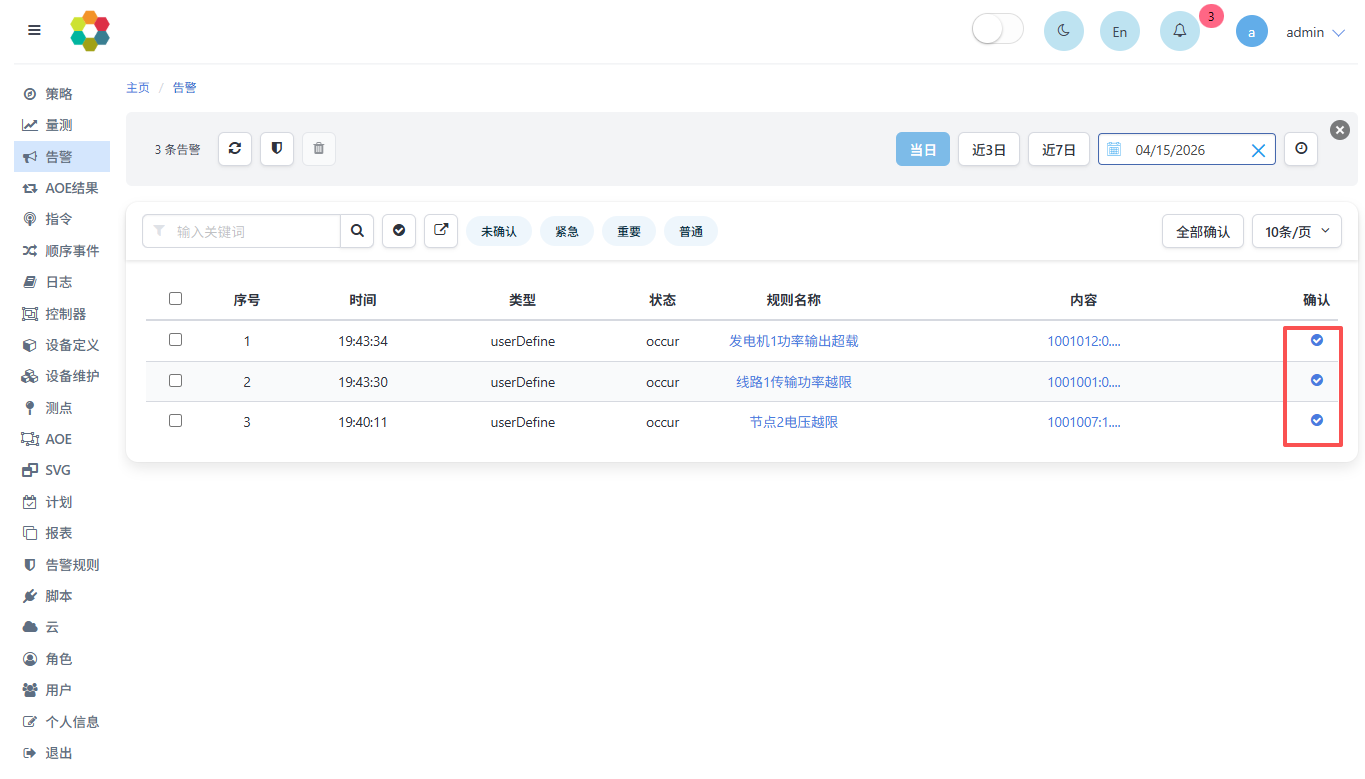
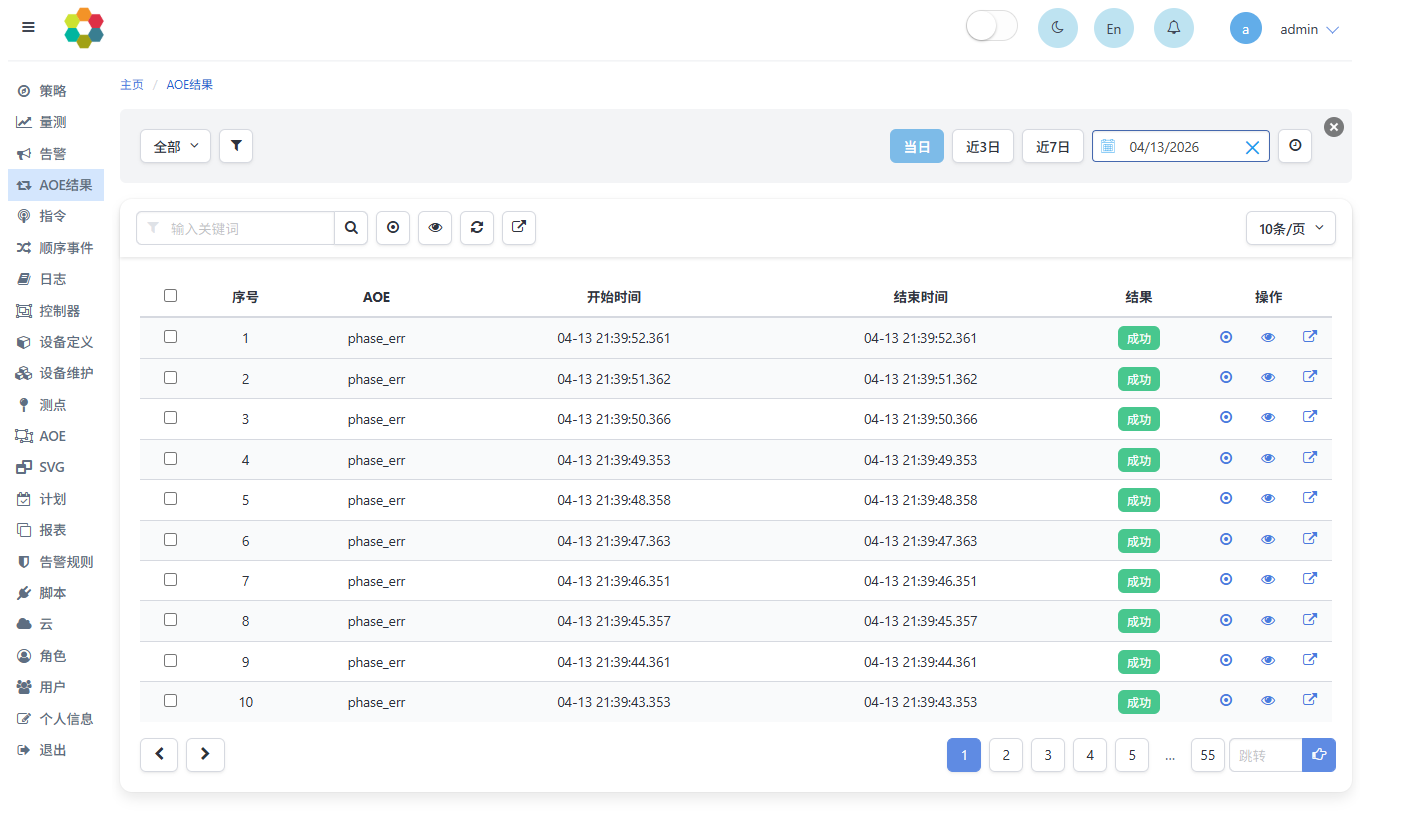
点击左侧菜单中AOE结果页面,可以观测详细的AOE的执行情况。
此外,可以在浏览界面查看设备、SVG、计划、报表等配置。
2 设计一个DFF
本章介绍如何设计一个DataFrame流(DataFrame Flow, DFF),首先介绍DFF的概念,然后分别说明DFF详情声明、DFF节点类型和DFF边类型,最后阐述DFF与AOE之间的配合。
2.1 DFF概念
一、什么是DFF
DFF全称为DataFrame Flow,是一种用于描述和处理多能系统(电、热、冷、气等)复杂数据计算过程的图形化逻辑模型。
您可以将其理解为一张“数据加工工序图”。在这张图中,能源系统的各种数据(如电压、流量、电价)被统一整理成标准化的表格(称为DataFrame),并通过带有方向的连接线(Flow)在不同的处理节点之间流动。DFF的作用,就是清晰地定义数据从哪里来、经过哪些计算步骤、最终流到哪里去。
二、什么是DataFrame
DataFrame 是MEMS中采用的一种标准化数据表示结构,其基于张量的数据表示。
在数学与物理学中,张量是标量、矢量和矩阵概念的高阶推广。MEMS将多能系统中各类异构数据,无论是单个数值(如某节点电压)、一维序列(如某时段负荷曲线)还是多维关系表(如支路参数矩阵),统一抽象为带名称标识的张量结构,并以列式表格的形式呈现,即为 DataFrame。
利用张量的多维数组形式结构,通过拓展其中的数据类型,使其可包含整数、浮点数、字符串等不同类型数据,则通过张量的组合可表示出各类业务数据。如下表用DataFrame表示了一个3节点直流微电网系统的节点信息:
| NodeId_3 | V_3 | I_3 | Type_3 |
|---|---|---|---|
| 1 | 750.0 | 0.0 | Slack |
| 2 | / | -30.2 | PQ |
| 3 | / | -22.8 | PQ |
上表中张量均采用列数据表示,在列名称中使用由“_”分隔的正整数表示张量各维度的长度。其中,NodeId_3(节点标识)表示长度为3的节点编号列;V_3(电压幅值,“—”表示待求解)长度为3的节点电压列;I_3(注入电流,负值表示负荷)长度为3的节点注入电流列;Type_3(节点分类)长度为3的节点类型列。
在多能系统中的应用价值在于:DataFrame 作为贯穿整个 DFF(DataFrame Flow)计算流程的数据载体,屏蔽了底层电、热、气不同能源介质的数据格式差异。无论是物理设备的实时采样值,还是优化算法产生的调度指令,均以相同的 DataFrame 格式在各计算节点间流转,从而实现了信息模型与物理模型在数据层面的无差别融合,为软件定义的灵活分析提供了统一的数据基础。
三、DFF的组成
一个DFF由节点 (Node)和边 (Edge)两个基本元素构成:
-
节点 (Node):分为数据源节点和张量计算节点,可以读取数据和进行矩阵计算、数学模型求解等操作。
-
边 (Edge):边实现节点与节点之间的连接和状态数据流转,支持相同结构的张量组计算操作以及人工智能模型。
基于节点和边两个元素,可以组成有向无环图来表示DataFrame流,如下图所示:
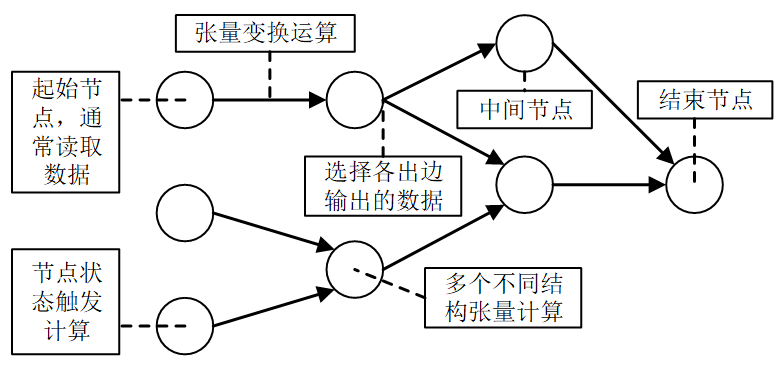
通过DFF,业务人员无需编写代码,只需将能源分析过程拆解为节点和连线,像绘制流程图一样配置计算逻辑。当业务规则发生变化时,直接在图上调整参数即可生效,无需改动底层程序,大幅减少了定制开发的投入。同时,所有数据都以结构统一的DataFrame格式流转,无论是电力、热力还是燃气数据,都能用同一种标准表达,确保物理设备信息与分析模型之间无缝对接、准确贯通。
2.2 DFF详情声明
设计一个DFF首先进行详情声明,包括DFF的触发类型、存储模式等信息的定义。
一、触发条件
MEMS中以状态为基础构建数学计算过程,以DataFrame流表示状态的流动变化,通过状态本身、状态触发事件、状态操作驱动状态的流转和变化,完成数学计算。
DFF被触发激活并从起始节点开始运行整个DFF网络的行为称为网络触发。DFF触发后从起始节点出发,依次执行各节点和边,直到结束节点,完成以状态张量为基本单元的数据计算和流动。
MEMS中的触发类型包括周期驱动、时间驱动、事件驱动、数据源驱动、手动驱动,具体说明如下表:
| 触发类型 | 名称 | 参数 | 说明 |
|---|---|---|---|
| SimpleRepeat | 周期驱动 | 时间周期 | 每隔一定时间周期,重复触发 |
| TimeDrive | 时间驱动 | Cron表达式 | 按照设定的时间触发 |
| EventDrive | 事件驱动 | 事件判断表达式 | 当设定的事件规则满足时触发 |
| DataSource | 数据源驱动 | / | 当数据源有变化时触发 |
| Manual | 手动驱动 | / | 手动触发 |
DFF的多种触发机制支持,能够实现数据流动链路的及时性、正确性,既保证了系统对关键事件的实时响应能力,又避免了无效的周期性空转计算。
二、存储模式
MEMS对DFF的计算过程与结果设计了EveryTime、Once、Memory、Never 四种存储模式。根据具体要求,用户可以选择合理的存储模式,以实现功能需求和系统性能之间的平衡。以下为各存储模式的定义说明:
| 存储模式 | 名称 | 说明 | 特点 | 使用场景 |
|---|---|---|---|---|
| EveryTime | 每次 | 每次DFF流程执行都会保存结果到数据库。 | 每次运行都会生成新的结果记录; 使用流程的开始时间作为唯一标识; 适合需要保留所有执行历史的场景; 会在数据库中存储完整的执行结果。 | 需要分析DFF执行历史趋势; DFF多次执行结果需要对比; DFF执行结果需要长期保存。 |
| Once | 单次 | 只保存DFF一次结果到数据库,后续执行不会覆盖或新增记录。 | 无论执行多少次,只在数据库中保存一条记录; 不使用时间戳作为标识(固定使用 t=0); 适合只需要最新结果的场景; 会在数据库中存储结果,但只保存一次。 | 只需要最新执行结果; 结果相对稳定,不需要历史记录; 节省存储空间。 |
| Memory | 内存 | 只将DFF结果保存在内存中,不写入数据库。 | 结果仅在内存中临时存储; 系统重启后结果会丢失; 执行速度快,因为不需要I/O操作; 适合临时计算或中间结果。 | 临时计算或中间结果; 对执行速度要求较高的场景; 结果不需要长期保存的情况。 |
| Never | 从不 | 不保存任何执行结果。 | 执行完成后结果立即丢弃; 不占用任何存储空间; 适合只关注执行过程,不需要结果的场景。 | 测试或调试流程; 流程执行本身就是目的(如数据转换、发送通知等); 结果已经通过其他方式处理(如写入文件、发送到外部系统等)。 |
根据具体需求选择合适的存储模式,配置建议如下:
- 需要完整历史记录:选择 EveryTime
- 只需要最新结果:选择 Once
- 追求执行速度:选择 Memory
- 不需要保存结果:选择 Never
2.3 DFF节点类型
在DFF中,节点是其有向无环图表达方法的组成单元之一。节点可分为数据源节点和张量计算节点2大类,其中数据源节点是获取数据信息的节点,张量计算节点可对多个不同结构的张量组进行操作,需包含矩阵计算、数学模型求解等多种计算能力,由此设计节点类型如下表所示:
| 节点类型 | 名称 | 输入量和参数 | 说明 |
|---|---|---|---|
| None | 无动作 | / | 无动作 |
| Source | 数据请求 | 数据源枚举 | 通过文件、数据库、URL、测点等数据源读取数据并生成张量 |
| TensorEval | 张量计算 | 计算表达式 | 执行张量计算表达式 |
| Solve | 线性方程组求解 | 系数、常数对应张量 | 线性方程组求解 |
| NLSolve | 非线性方程组求解 | 方程组公式、变量初值字符串 | 非线性方程组求解 |
| MILP | 混合整数线性规划 | 目标系数、约束系数、约束上下限、变量类型、初值对应张量 | 混合整数线性规划 |
| NLP | 非线性规划 | 目标函数、约束条件、变量初值字符串 | 非线性规划 |
| Wasm | Wasm脚本 | Wasm脚本 | 执行Wasm脚本中的自定义运算 |
具体的配置格式详见DFF节点定义。
2.4 DFF边类型
在DFF中,边是其有向无环图表达方法的组成单元之一。边实现节点与节点之间的连接和状态数据流转,在边上可配置选取首节点中相同结构的张量组作为数据源,并执行所需的计算操作,由此设计边的类型如下表所示:
| 边类型 | 名称 | 说明 |
|---|---|---|
| Eval | 张量计算 | 支持幂运算、转置、聚合计算、排序等单个张量计算操作 |
| Kmeans | K-means聚类 | K-means聚类模型 |
| RandomTree | 随机树 | 随机树模型 |
| Onnx | Onnx神经网络交换 | 开放神经网络交换模型 |
| Nnef | Nnef神经网络交换 | 神经网络交换格式模型 |
具体的配置格式详见DFF边定义。
DFF与AOE
3 设备模块
MEMS的设备模块分为控制器管理、设备定义和设备维护。控制器管理功能中,可管理同一局域网内各控制器的启停、配置等操作;设备定义功能中,主要定义了各类设备模板的资源类型、基本属性、端子数量;设备维护功能中,选定相应的设备模板进行设备树维护。
3.1 控制器管理
MEMS的控制器管理模块可通过网络与能源系统中的各个控制器连接,管理各控制器的启动和停止,同时可对控制器进行完整配置操作以及查看控制器采集测点数据、控制策略执行情况、告警信息等,此外,在控制器管理模块中还可直接将控制器中的测点配置信息直接选择导入能量管理系统中,可极大简化能量管理系统中的测点配置。只需要将该软件与控制器置于同一个局域网内,即可直接连接管理控制器。
MEMS默认使用端口7056和7057连接管理控制器,监听端口也可在config配置文件中进行设置,写法如下:
lccListenPort=7056
lccRtmsgListenPort=7057
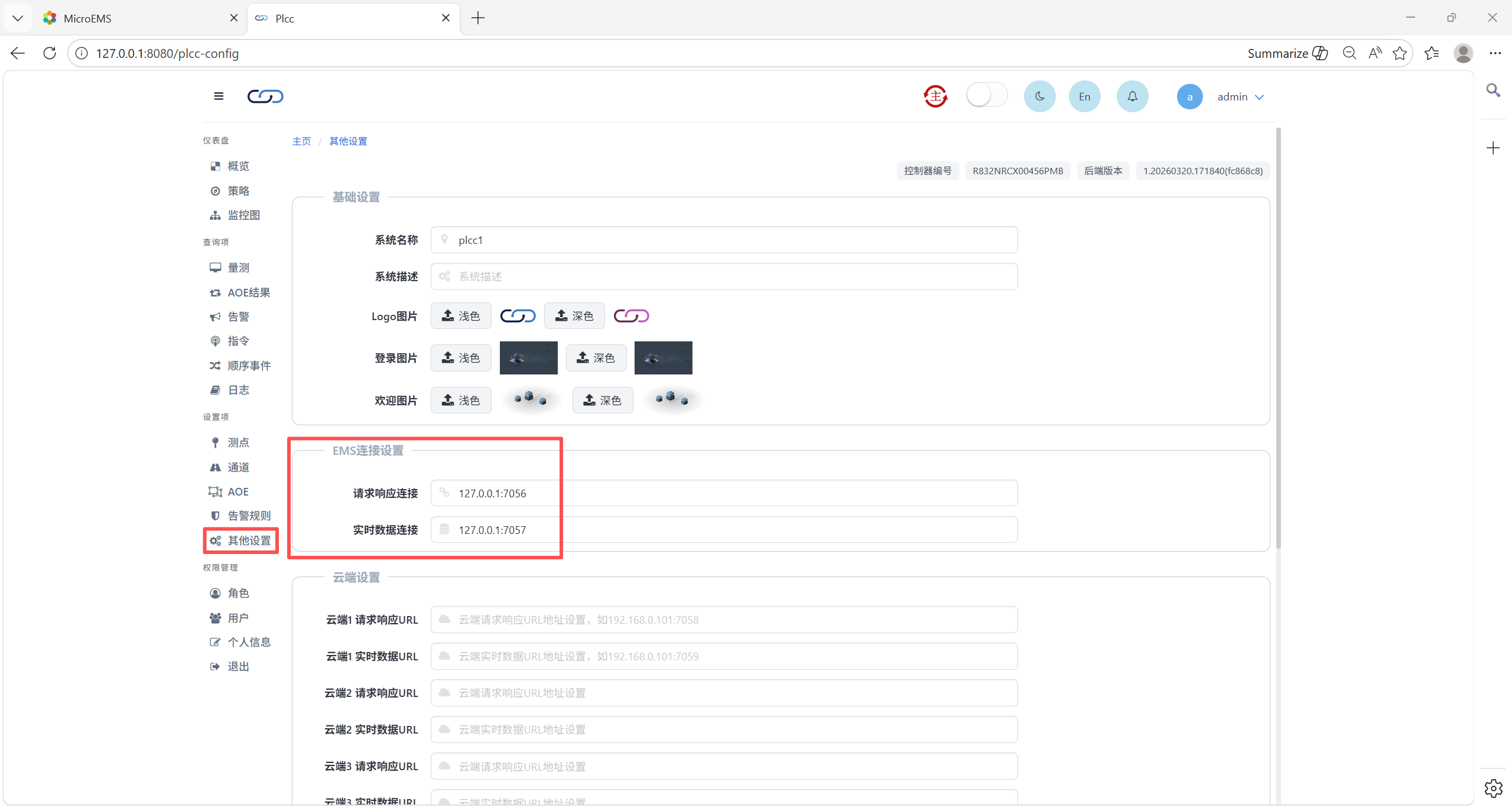
在低代码控制器config配置文件配置接入MEMS的IP和端口,如下所示,其中eigProxyAddress和eigRtMsgProxyAddress为参数名称,127.0.0.1为MEMS的IP:
eigProxyAddress = 127.0.0.1:7056
eigRtMsgProxyAddress = 127.0.0.1:7057
上述配置也可在MEMS界面设置项-其他设置-EMS连接设置中进行配置,如下图所示。
配置完成后,在MEMS的设备-控制器界面上可以看到接入的控制器,如下图所示。
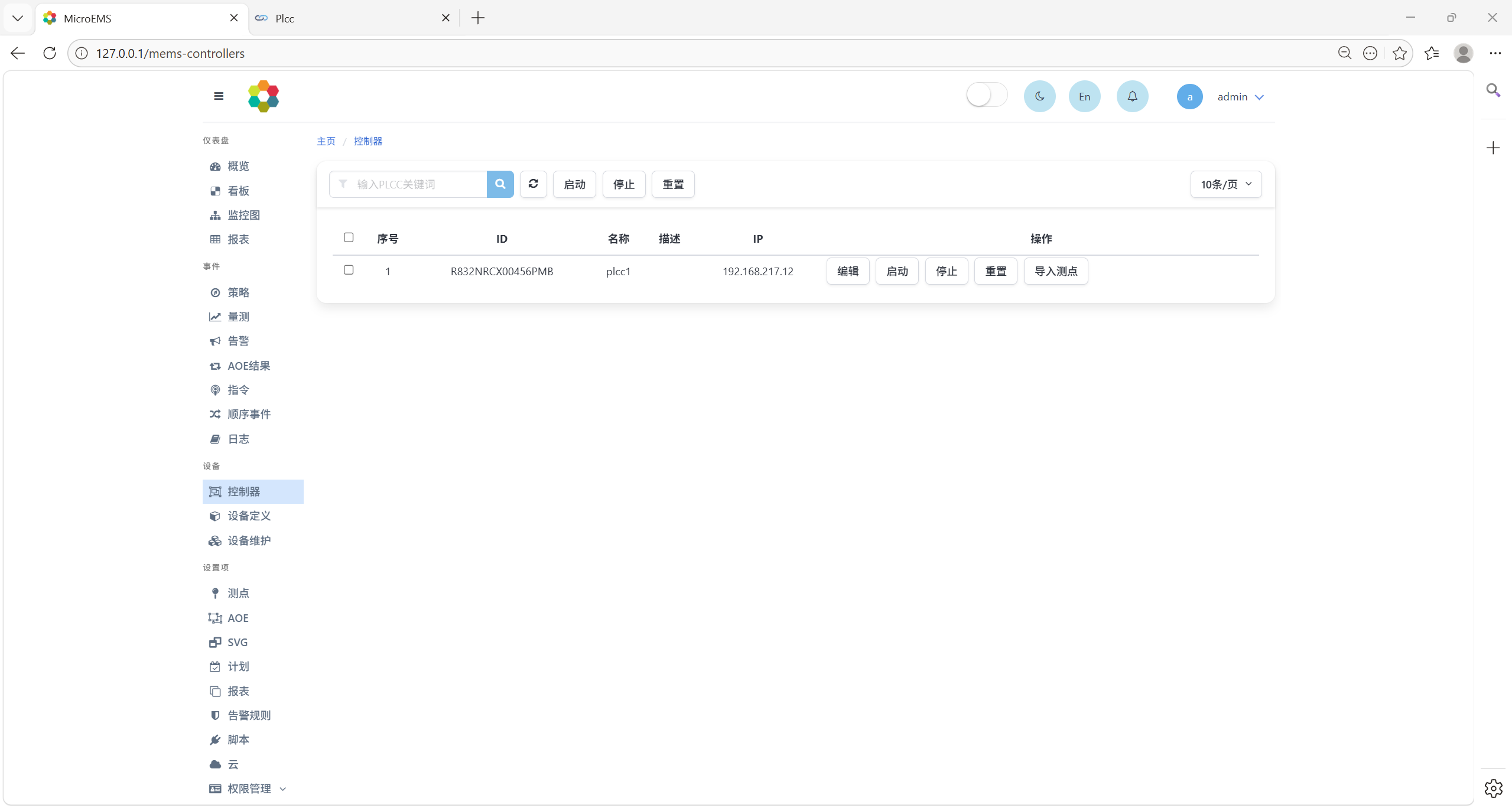
点击导入测点按钮,可将控制器中的测点配置导入MEMS的测点中。
点击编辑按钮,可进入低代码控制器编辑界面,与在低代码控制器自身界面进行编辑操作类似。此外,在MEMS界面上还可进行控制器启动、停止、重置操作。
3.2 设备定义
MEMS在设备定义功能中定义各类设备模板,设备模板用于后续设备维护时选定。具体配置可在设备-设备定义界面中进行操作,如下图所示:
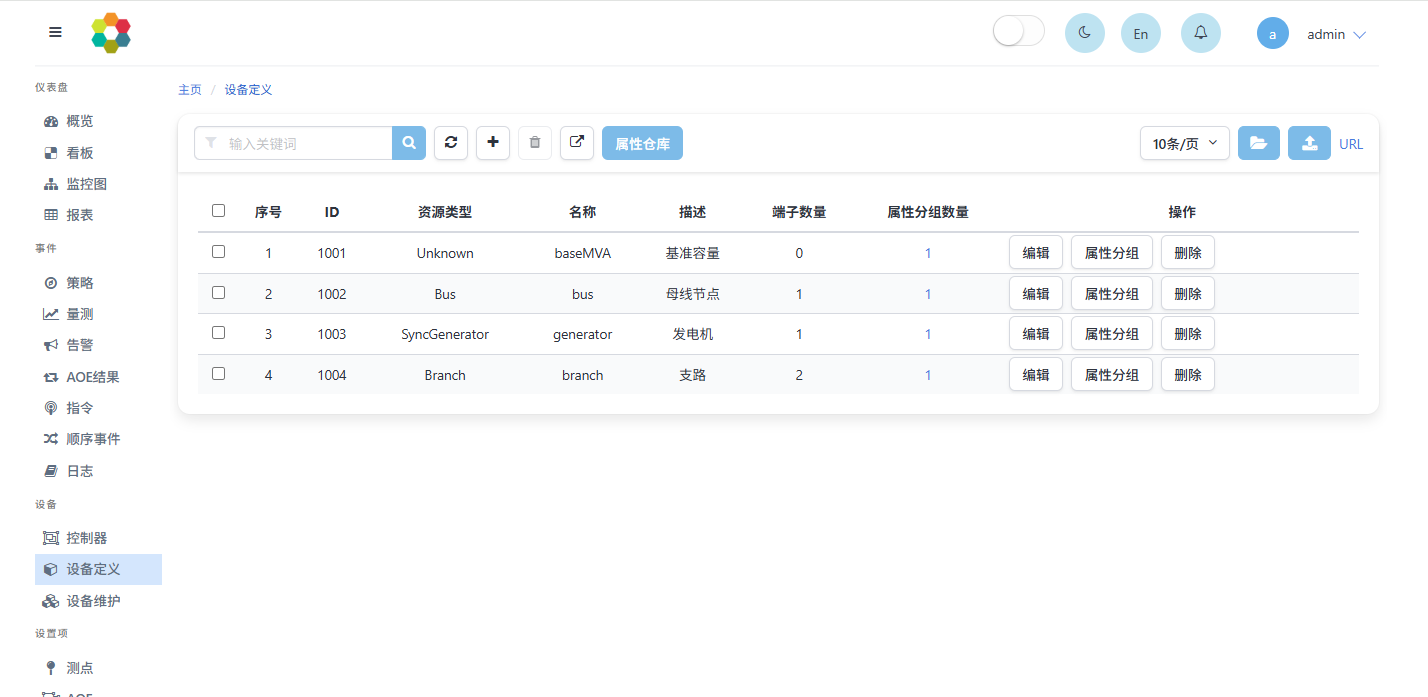
设备模板定义的具体参数解释如下:
- 序号:u64类型,是各个设备模板的编号,只是配置表格中的一个标记,一般从1开始连续对设备模板进行编号,方便表格编写,不影响MEMS程序功能。
- ID:u64类型,是设备模板的编号ID,不能重复,设备维护选用设备模板时,通过设备模板ID实现对应。注意:设备模板ID一般从1001后开始编号。
- 资源类型:用约定的类型声明表示,支持的资源类型如下表所示。
| 资源类型 | ||||
|---|---|---|---|---|
| Switch | Busbar | ACline | DCline | Winding |
| SyscGenerator | ESS | PCS | Transformer | Load |
| ShuntCompensator | SerialCompensator | Feeder | PWBusbar | Cable |
| Regulator | Connector | Measurement | Company | Sublsland |
| LoadArea | Substation | PowerPlant | VoltageLevel | BaseVoltage |
| HvdcSys | HvdcPoleSys | DCPole | DCLineDot | TLineDot |
| Converter | Breaker | Disconnector | GroundDisconnector | TLine |
| ACLineDot | TNode | Convergenceline | ShuntReactor | ShuntCapacitor |
| SeriesReactor | SeriesCapacitor | SVC | SVG | SeriesPowerTransformer |
| SeriesTransformerWinding | Acfilter | Synccondensor | DCBreaker | DCDisconnector |
| Signal | Combined | Composite | Section | SectionType |
| Bus | Branch | UserDefine1 | UserDefine2 | UserDefine3 |
| UserDefine4 | UserDefine5 | UserDefine6 | UserDefine7 | UserDefine8 |
| UserDefine9 | UserDefine10 | Unknown | ||
- 名称:字符串类型,最长15字符,表达设备模板的内容,便于理解。
- 描述:选填,最长128字符,用于解释设备模板的具体作用。
- 端子数量:u64类型,0~255之间的整数,必填,定义该设备的端子数。
- 属性分组:属性仓库定义完成后,可进入属性分组添加该设备模板的属性。具体内容见属性仓库和属性分组。
设备定义例子如下:设备定义_example
3.2.1 属性仓库
属性仓库中可以定义和管理各种属性,定义完成后,设备模板可直接从该仓库中选取所需属性。具体配置可在设备-设备定义中点击属性仓库按钮进入设备属性定义界面进行操作,如下图所示:
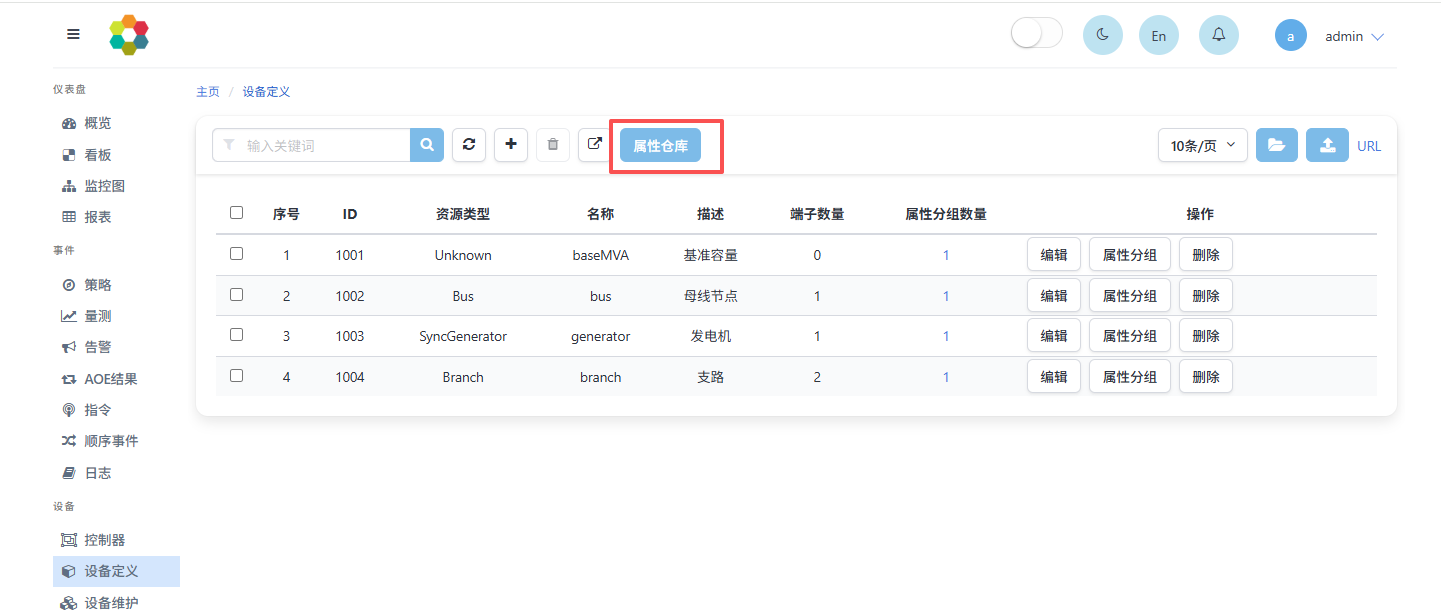
属性仓库中每条属性的具体参数解释如下:
- 序号:u64类型,是各个属性的编号,只是配置表格中的一个标记,一般从1开始连续对属性进行编号,方便表格编写,不影响MEMS程序功能。
- ID:u64类型,是属性的编号ID,不能重复,设备定义选取所需属性时,通过属性ID实现对应。注意:属性ID一般从101后开始编号。
- 属性标识:必填,字符串类型,由字母、数字、下划线或减号组成,最长15字符,作为属性的标识符。
- 属性描述:必填,最长15字符,用于解释属性的具体作用。
- 数据类型:用约定的类型声明表示,支持的数据类型如下表所示。
| 数据类型 | |||||
|---|---|---|---|---|---|
| U8 | U16 | U32 | U64 | I8 | I16 |
| I32 | I64 | F32 | F64 | Complex32 | Complex64 |
| Str | TensorF32 | TensorF64 | TensorC32 | TensorC64 | Unknown |
- 数据单位:用约定的数据单位声明表示,支持的数据单位如下表所示。
| 数据单位 | |||||||
|---|---|---|---|---|---|---|---|
| on_or_off | A | V | kV | W | kW | MW | Var |
| kVar | MVar | VA | kVA | MVA | H | mH | Ah |
| mAh | kWh | ℃ | ft | km | meter | mm2 | UnitOne |
| % | bit | B | kB | MB | GB | TB | PB |
属性仓库例子如下:属性仓库_example
3.2.2 属性分组
属性分组用于管理各设备模板的属性。具体配置可在设备-设备定义界面中,点击目标设备模板的属性分组按钮进入属性分组界面进行操作,如下图所示:
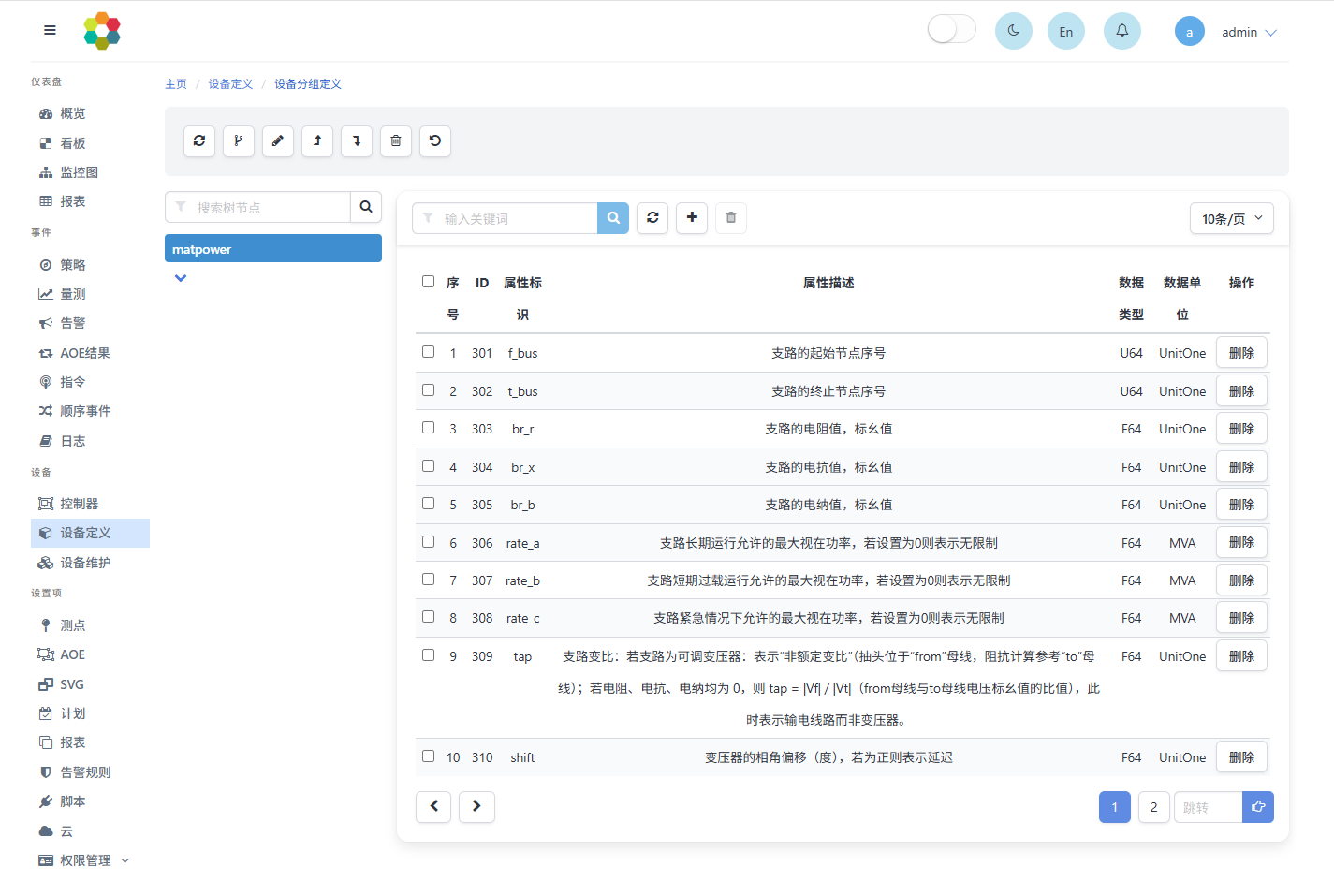
属性分组前,首先需创建属性分组树节点,属性分组的具体参数如下:
- 标识:必填,最长15字符,表达属性分组的内容,便于理解。
- 描述:必填,最长15字符,用于解释属性分组的具体作用。
在创建属性分组后可为其添加属性,即勾选属性仓库中已定义的属性进行添加。
3.3 设备维护
设备维护用于编辑与管理系统中具体的设备。设备的管理根据设备的父子关系生成设备树实现。设备的编辑在设备定义功能中完成各类设备模板的定义后,可在设备维护功能中选择相应的设备模板并创建具体设备,然后进行设备属性数值编辑、测点绑定、CNs绑定等操作。设备维护包括设备编辑、测点绑定、CNs绑定三块功能:
此外,设备维护支持版本管理功能,在执行前需提交并应用版本。
3.3.1 设备编辑
设备通过设备树进行分类管理,具体可在设备维护中,点击设备按钮上传设备配置文件实现,如下图所示:
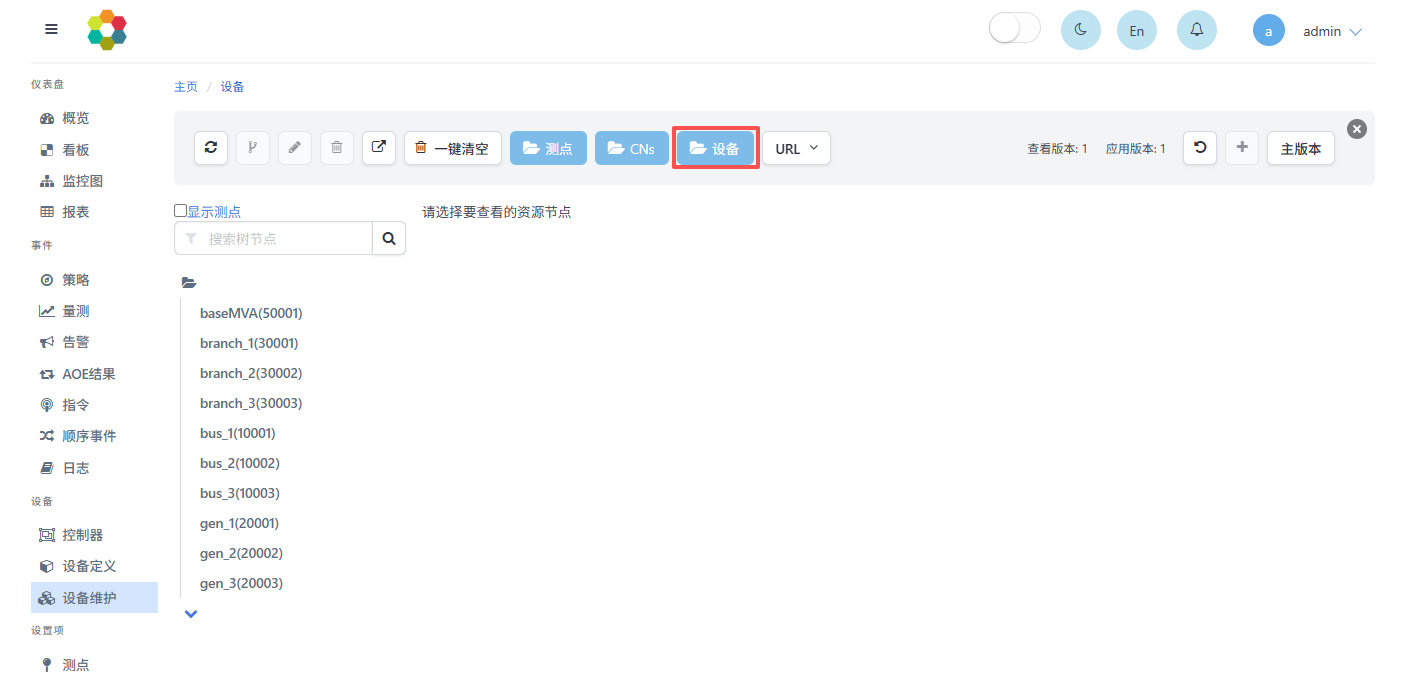
各设备的具体参数解释如下:
- 序号:u64类型,是各个具体设备的编号,只是配置表格中的一个标记,一般从1开始连续对属性进行编号,方便表格编写,不影响MEMS程序功能。
- 父节点:表示本设备所属的上级设备名称,用于设备树管理。为空时表示本设备为最高级根节点。
- ID:u64类型,是设备的编号ID,不能重复。注意:属性ID一般从10001后开始编号。
- 设备定义:为选择项,只能从设备定义功能中事先定义好的设备模板中选择,选择后将自动填写设备定义ID、资源类型、端子数量等信息。
- 名称:字符串类型,最长15字符,表达设备的内容,便于理解。
- 描述:选填,最长128字符,用于解释设备的具体信息。
在设备绑定了设备模板后,需要完成填写所选设备模板下的所有属性值,具体值的填写要求由设备定义中确定,即需符合设备模板属性的数据类型。
设备编辑例子如下:设备编辑_example
3.3.2 测点绑定
设备通过测点绑定实现与测点的联系,用于用户管理设备具体的量测值读写操作。具体可在设备维护中,点击测点按钮上传设备测点绑定配置文件实现,勾选显示测点展示设备所关联的测点,如下图所示:
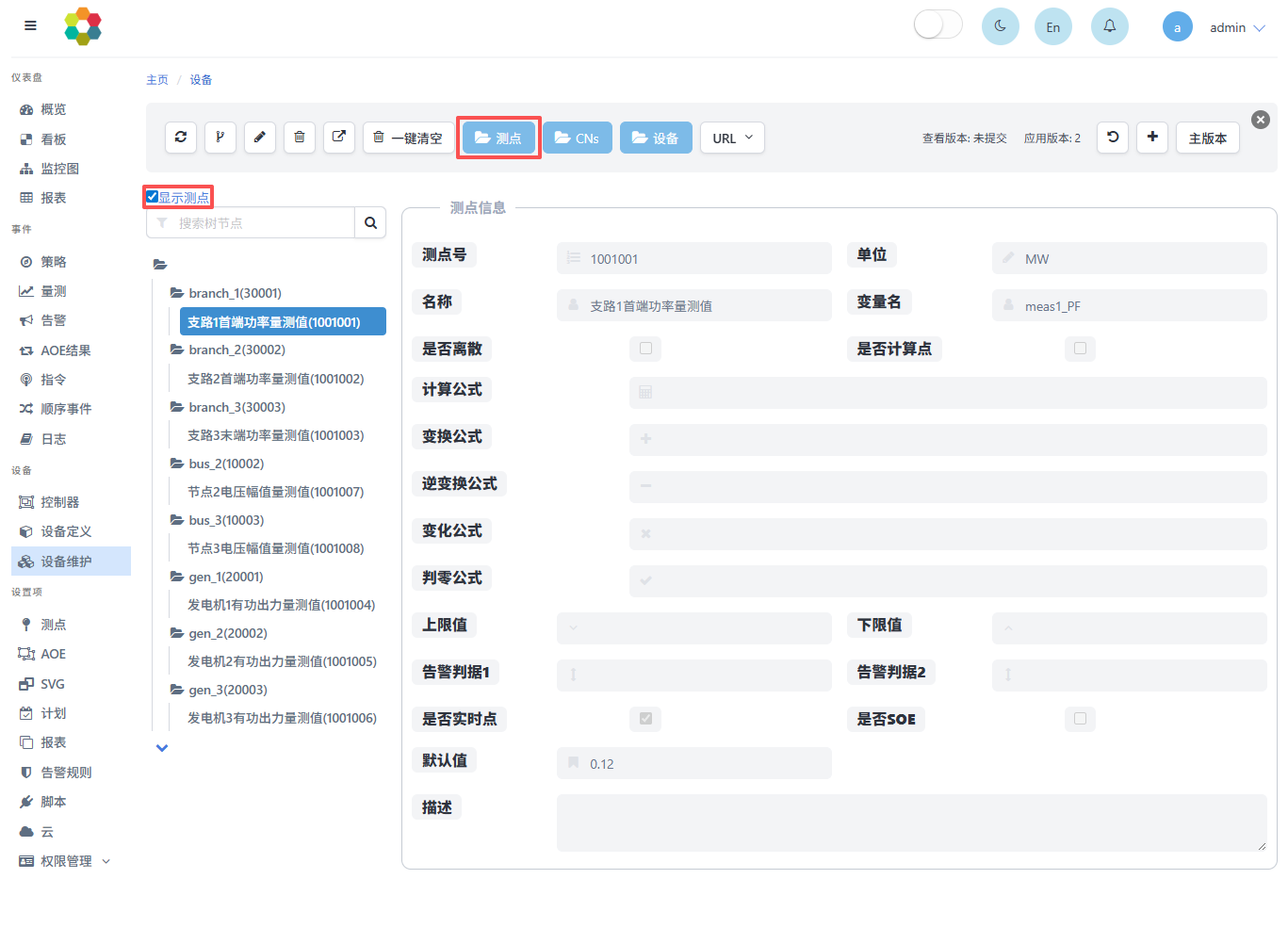
设备测点绑定的配置案例如下所示:
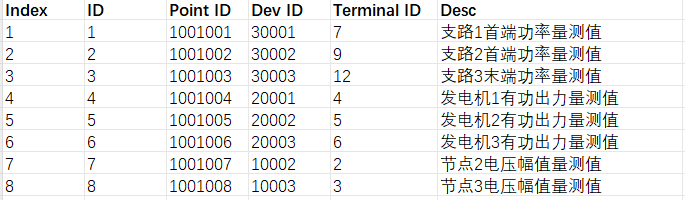
其配置参数的具体解释如下:
- 序号:u64类型,只是配置表格中的一个标记,一般从1开始连续对属性进行编号,方便表格编写,不影响MEMS程序功能。
- ID:u64类型,是该条测点绑定的编号ID,不能重复。
- 测点ID:u64类型,所绑定目标测点的ID。
- 设备ID:u64类型,所绑定的测点对应的设备的ID。
- 端子ID:u64类型,所绑定的测点对应的CNs的端子ID。
- 描述:选填,最长128字符,用于解释所绑定测点的具体含义。
设备编辑例子如下:测点绑定_example
3.3.3 CNs绑定
设备通过CNs绑定实现与端子的联系,CNs绑定的具体参数解释如下:
- CN:
- Terminal:
设备编辑例子如下:测点绑定_example
4 配置文件编写
MEMS的文件配置分为:测点配置、AOE配置、SVG配置、计划配置、DFF配置、告警规则配置、脚本配置等,下面将分章节介绍各配置文件的编写规则:
4.1 测点配置
测点(point)配置是对每一个测点的属性进行定义,其含义和配置方式可以参考https://sgool.zju.edu.cn/docs/lcc_in_action/4-1-测点文件配置.html。
在上述LCC的测点配置基础之上,MEMS中的测点配置还包含测点与设备绑定、测点数据源和版本管理,具体如下。
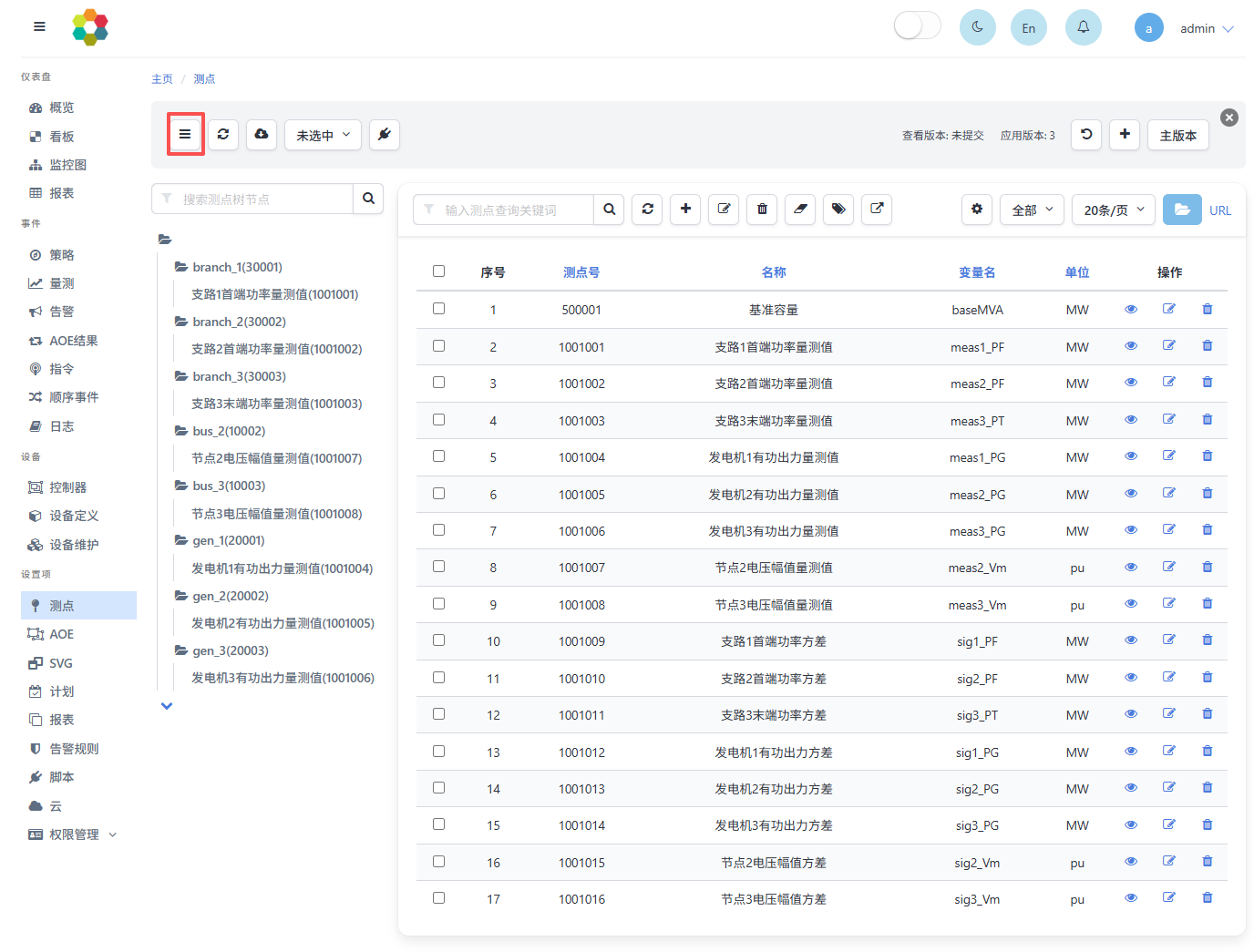
4.1.1 测点与设备绑定
测点与设备的绑定可在设备维护中实现,具体可见测点绑定。在设置项-测点界面中,可点击如下按钮显示测点与设备的绑定关系:
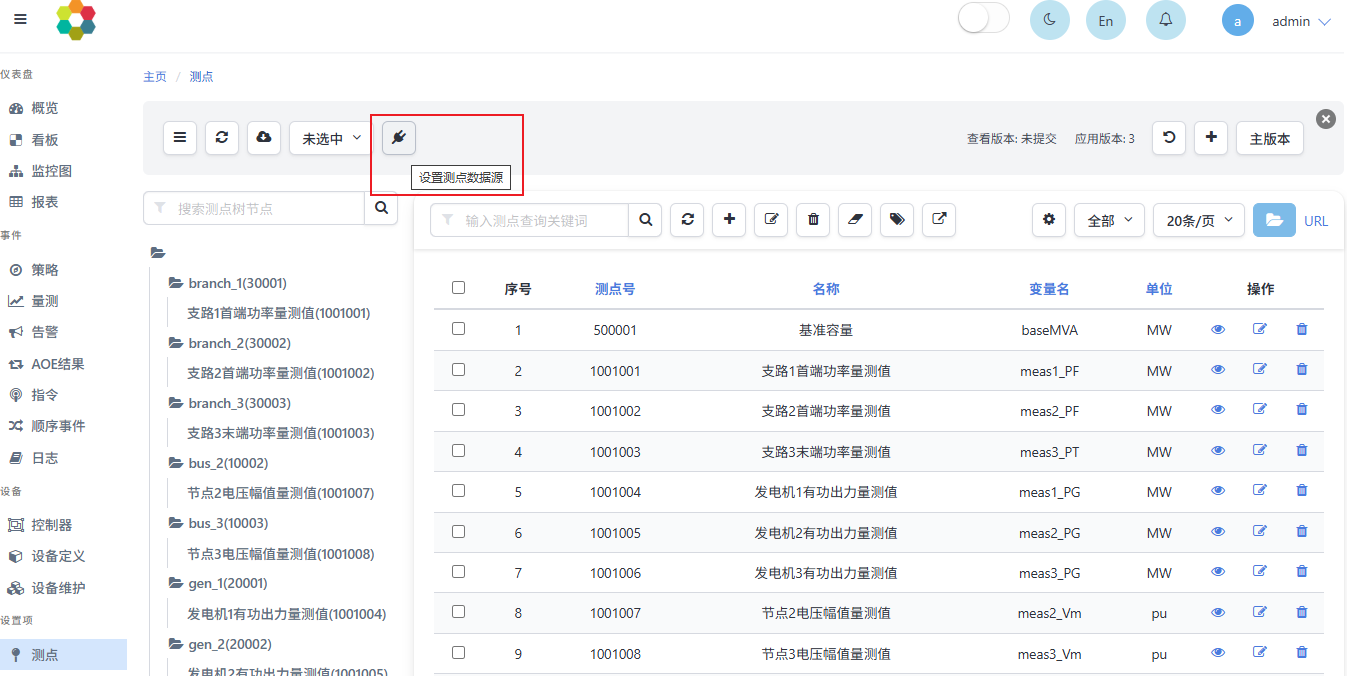
4.1.2 测点数据源
点击设置测点数据源按钮,可进行测点的数据源配置,如下图所示:
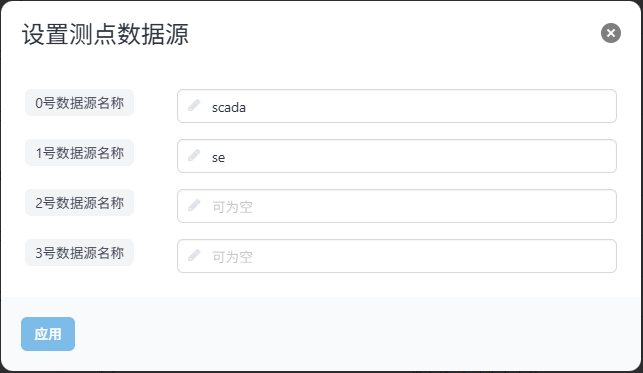
注意:
- MEMS支持多数据源,用于储存测点不同来源的赋值,常见的来源包括scada、状态估计、人工等。最多可以设置4个数据源,其中0号数据源一般表示scada数据源,需要支持多种数据源时,可以在测点界面进行设置。
- 在量测界面和监控图界面可以切换数据源用于查看不同数据源的实时数据或历史数据,也可以也界面上通过设置测点值改变当前数据源下的数值。
4.1.3 版本管理
MEMS中的测点配置支持版本管理功能,在执行前需点击提交一个版本按钮进行提交,并点击主版本按钮选择应用相应的版本,如下所示:
4.2 AOE配置
AOE配置是对AOE控制策略进行定义,其含义和配置方式可以参考https://sgool.zju.edu.cn/docs/lcc_in_action/4-3-AOE策略文件配置.html。
在上述LCC的AOE配置基础之上,MEMS中的AOE配置还可以与DFF进行联动,如下所示:
此外,AOE配置支持版本管理功能,在执行前需提交并应用版本。
SVG配置
4.4 计划配置
MEMS可对设备运行计划曲线进行配置。通过定义计划分组,能源系统、供用能设备、控制策略可选择计划分组进行关联从而确定设备运行计划,实现设备、控制策略与运行计划定义的逻辑分离,提升计划管理清晰度、通用性和可扩展性。
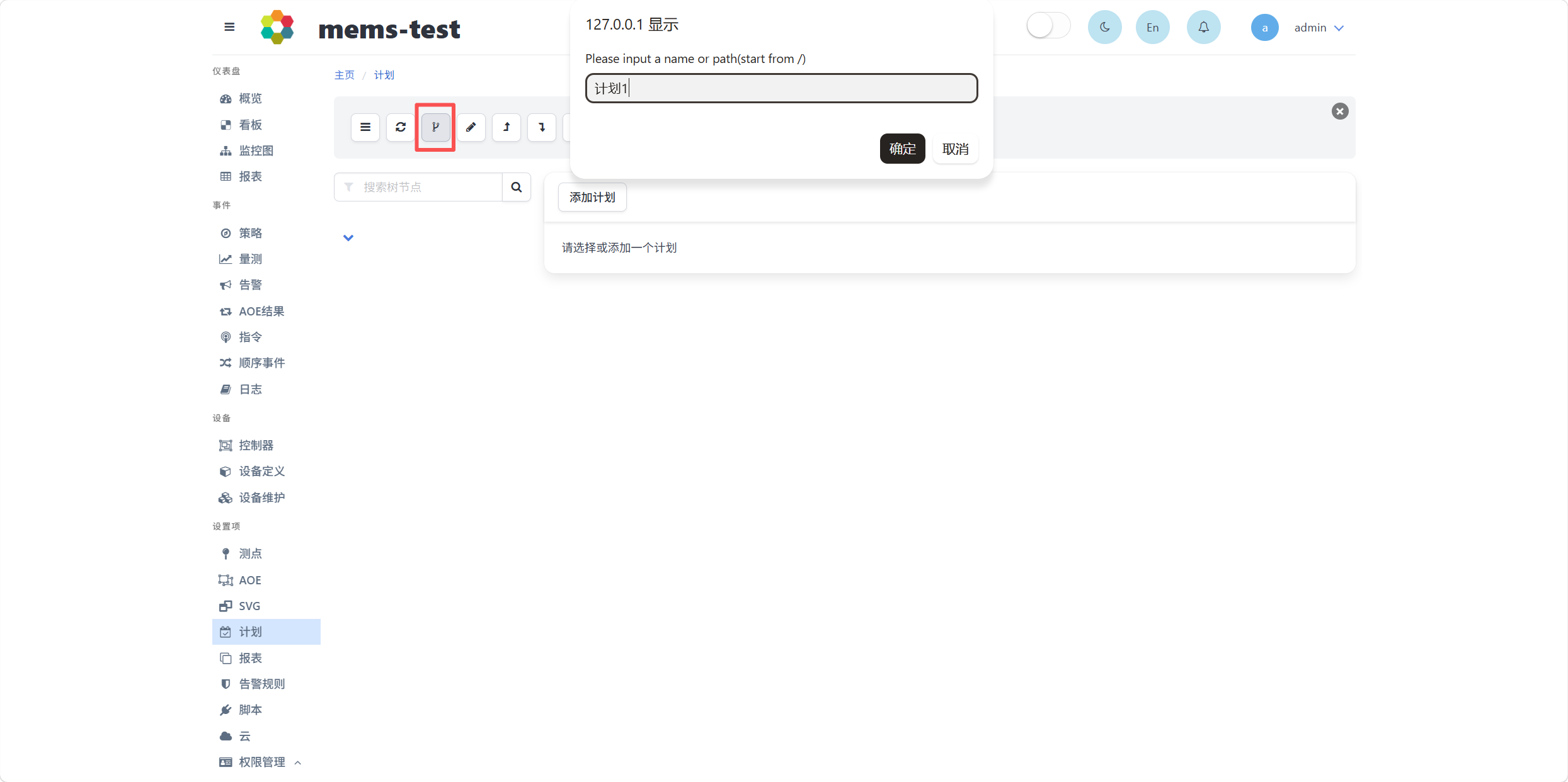
4.4.1 新建计划分组
在设置项-计划中,点击创建新树节点按钮,弹出计划分组名称输入框,输入计划分组名称后点击确定,添加计划分组,如下图所示。
4.4.2 添加计划
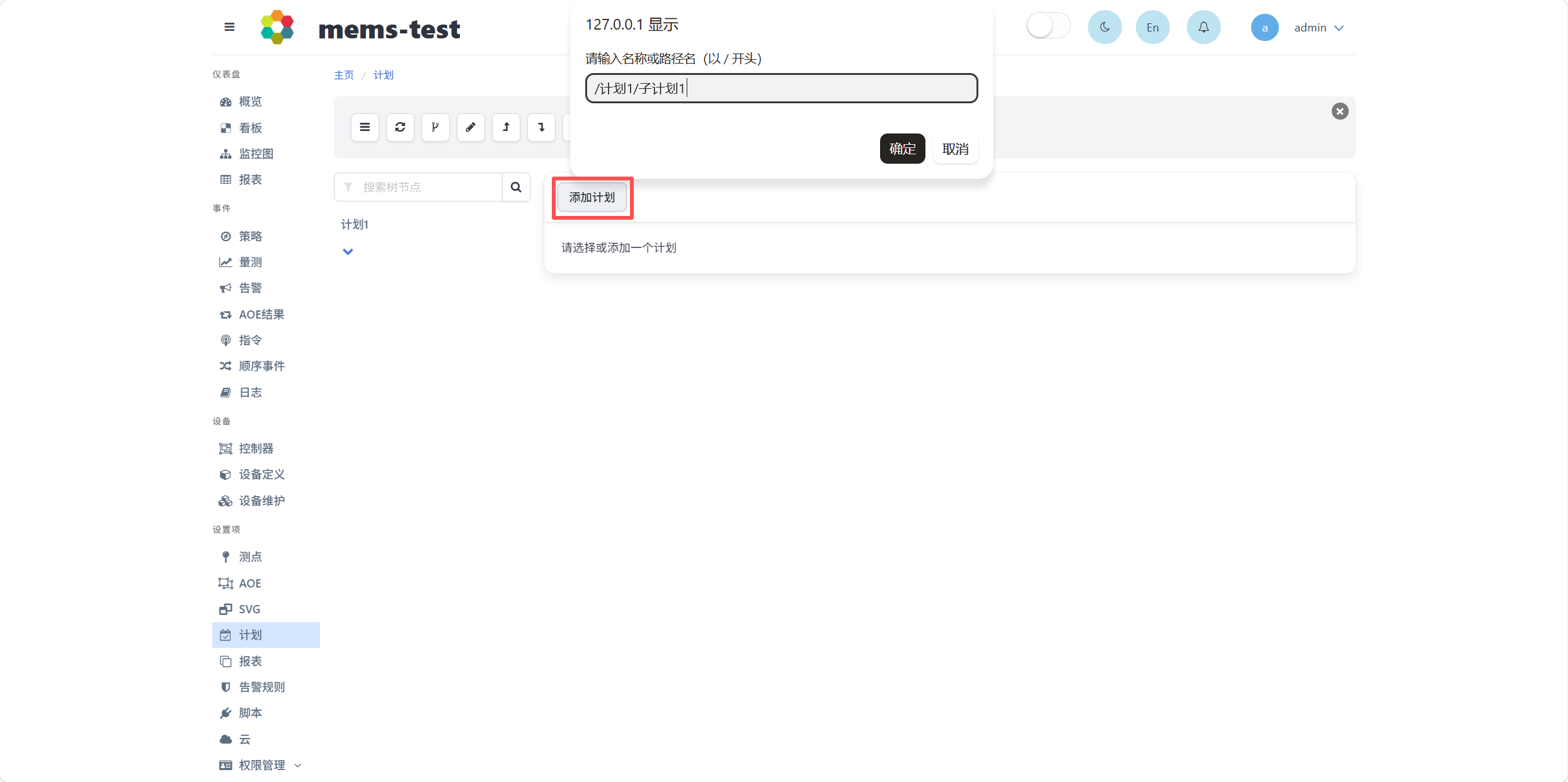
点击添加计划按钮,在弹出的计划名称输入框中输入以/开头和分割路径的计划路径名称,如下图所示。
4.4.3 计划曲线设置
通过右侧加减号按钮添加和删除一天时间内的分段计划曲线操作,新增的曲线分段默认开始时间为上一条曲线分段的结束时间,一天的开始和结束时间为00:00。编辑完成后,需要点击保存按钮,页面下方将会显示设置的计划曲线。
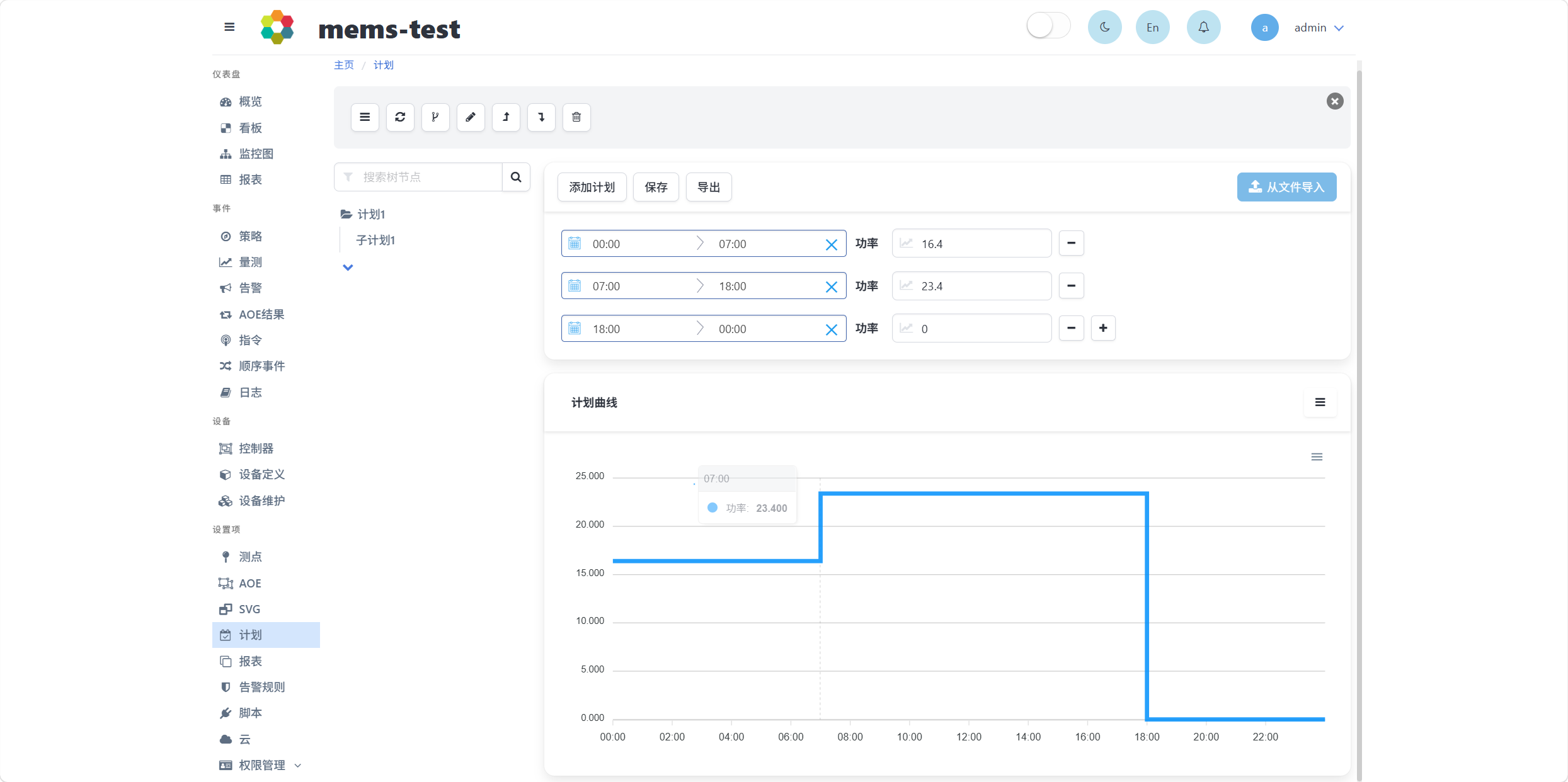
注意计划曲线设置需满足如下验证内容:
- 起止时间:需要覆盖全天且不能重叠
- 功率:数值类型,必填
4.4.4 计划曲线导入和导出
通过点击工具栏的导出按钮,可将设置的计划曲线导出为文件,文件格式如下所示。
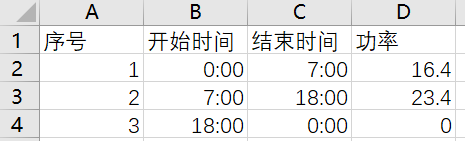
通过点击从文件导入按钮,可将满足上述格式要求的计划曲线配置文件导入,进行计划曲线设置。
4.5 DFF配置
DFF文件配置可以在excel中完成,DEE配置可以分为DFF详情定义、DFF节点定义、DFF边定义三个部分。
注:
DFF增加删除、修改配置后需要重置(reset)才能生效。
4.5.1 DFF详情定义
DFF详情定义部分,定义了DFF的触发类型、保存模式等整体信息以及相关联的AOE信息,其配置内容包括DFF ID、是否启用、名称、触发条件(及触发条件参数)、存储模式。
| DFF ID | 是否启用 | 名称 | 触发条件 | 触发条件参数 | 存储模式 | 目标AOE | AOE变量名称 |
|---|---|---|---|---|---|---|---|
| <u64> | <Bool> | <String> | Simple_Repeat Time_Drive Event_Drive DataSource Manual | <u64> <String> <String> <String> < \ > | EveryTime Once Memory Never | <u64> | <String> |
-
DFF ID:不同DFF的标识,用<u64>(64位无符号整数)表示。(注:DFF ID需从65536后开始编号)。
-
是否启用:决定该DFF是否启用,用<Bool>(布尔类型)表示。
-
名称:表达DFF的功能,便于理解,用<String>(表示字符串类型)表示。
-
触发条件:分为五类,即SimpleRepeat(定时触发)、TimeDriven(时间驱动)、EventDriven(事件驱动)、DataSource(数据源驱动)、Manual(手动)。
-
触发条件参数:参数配置格式如下表
触发条件 说明 Simple_Repeat 触发条件参数为重复驱动之间的时间间隔,用正整数<u64>表示,单位为ms Time_Drive 表示执行计划,写法参照cron表达式,在设置时间点触发 Event_Drive 事件判断表达式 DataSource 数据源驱动触发条件参数可以为空,表示任一数据源节点收到数据后即运行DFF(未收到数据的数据源节点输出为空DataFrame),也可以设为用 ;分隔的节点编号,表示相应编号数据源节点都收到数据之后才会驱动运行DFF。Manual 为缺省值,无需设置 -
存储模式:分为四类,即EveryTime(每次)、Once(单次)、Memory(内存)、Never(从不)。
-
目标AOE:DFF所关联的目标AOE的ID,用<u64>(64位无符号整数)表示,若不启用该功能可空。
-
AOE变量名称:DFF最后输出结果传递给关联AOE的目标变量,用<String>(表示字符串类型)表示,若不启用该功能可空。
4.5.2 DFF节点定义
DFF节点定义部分的配置内容包括DFF ID、节点ID、名称、节点类型及其参数。
| DFF ID | 节点ID | 名称 | 节点类型 | 参数 |
|---|---|---|---|---|
| <u64> | <u64> | <String> | None Source Transform TensorEval Sql Solve NLSolve MILP NLP Wasm | < \ > <String> <String> <String> <String> <String> <String> <String> <String> <String> |
-
DFF ID:声明节点属于哪个DFF,用<u64>(64位无符号整数)表示。
-
节点ID:一个DFF配置下节点编号。
-
名称:便于理解节点内容,往往是对节点功能的简要文字解释,用<String>(表示字符串类型)表示。
-
节点类型:用约定的类型声明表示,包含如下类型:None、Source、Transform、TensorEval、Sql、Solve、NLSolve、MILP、NLP、Wasm。
-
节点类型参数:不同节点类型的参数配置要求不同,具体要求如下。
节点类型示例说明
一、None
节点类型为None时,表示在节点中不对数据进行操作,直接输出数据。
二、Source
节点类型为Source时,该节点可实现查询和获取数据作为数据源输入的操作。选择该类型后需继续选择数据源类型并填写获取方式,其中数据源类型包括:Meas、Point、File、Url、Data、Dev、Image、Sql、OtherFlow、Plan、PointsEval、MeasEval。
(1)Source_Meas(量测)
在节点类型为Source的节点中,选择DF源类型为Meas时,可以获取量测信息作为数据输入(表格配置中选择Source_Meas类型)。其中,量测信息分为历史量测信息和实时量测信息两种,具体配置方法如下:
1)获取历史量测信息
在参数1中,可采用如下语法获得量测的历史信息:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数1 | 参数2 |
|---|---|---|---|---|---|
| 65536 | 1 | 获取量测历史数据 | Source_Meas | ?id=1000001&start=1775654400000&end=1775655100000 |
节点含义:获取ID为1000001的测点在时间戳1775654400000、1775655100000之间的量测信息。返回的信息为该测点每一次值变化时的的ID、量测值和时间戳。
当需要获取多个测点的量测历史信息时,id参数可以配置多个,如:?id=1000001,1000002&start=1775654400000&end=1775655100000表示获取ID为1000001和1000002的测点在时间戳1775654400000、1775655100000之间的信息。
2)获取实时量测信息
在参数2中,可采用SQL语句的select获得量测的实时信息(参数1需为空),如下:
获取某一测点的量测信息:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数1 | 参数2 |
|---|---|---|---|---|---|
| 65536 | 1 | 获取量测实时信息 | Source_Meas | select * from meas where id = 1000001 |
节点含义:获取ID为1000001的测点的ID、量测值和时间戳(*表示全部信息)。假如此时1000001测点量测值为999,则返回1*3的DataFrame:
| id | value | timestamp |
|---|---|---|
| 1000001 | 999 | 17708606400008 |
注:
*表示量测的全部信息,若仅需返回量测的单个信息或几个信息时,只需将*替换为相应的参数即可,如下:select id,value from meas where id = 1000001表示获取ID为1000001的测点的id和实时量测值;select timestamp from meas where id = 1000001表示获取ID为1000001的测点的时间戳。
获取多个测点的量测信息:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数1 | 参数2 |
|---|---|---|---|---|---|
| 65536 | 1 | 获取量测实时信息 | Source_Meas | select * from meas where id = 1000001 or id = 1000002 |
节点含义:获取ID为1000001和1000002的测点的ID、量测值和时间戳。假如此时1000001测点量测值为999,1000001测点量测值为888,则返回2*3的DataFrame:
| id | value | timestamp |
|---|---|---|
| 1000001 | 999 | 17708606409640 |
| 1000002 | 888 | 17708606407318 |
注:
-
若需查询量测的测点数量较多,可采用如下语法:
select * from meas where id between 1000001 and 1001000,表示返回ID在1000001至1001000之间的所有测点的量测信息。 -
此外,若要求获取的信息按某一顺序排列,可采用
order by xxx asc实现,如:select * from meas where id between 1000001 and 1001000 order by id asc,表示返回ID在1000001至1001000之间的所有测点的量测信息,并按测点ID进行排列。
(2)Source_Point(测点)
在节点类型为Source的节点中,选择DF源类型为Point时,可以获取测点的配置信息作为数据输入(表格配置中选择Source_Point类型)。采用SQL语句获得测点配置信息,具体配置方法如下:
获取某一测点的配置信息:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数 |
|---|---|---|---|---|
| 65536 | 1 | 获取测点配置信息 | Source_Point | select * from points where id = 1000001 |
节点含义:获取ID为1000001的测点全部配置信息(*表示全部信息)。返回1*13的DataFrame(下表测点的具体配置信息为举例):
| id | name | alias | is_discrete | is_computing | data_uni | upper_limit | lower_limit | is_realtime | is_soe | is_remote | timestamp | value |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1000001 | 测点1 | point1 | false | false | MW | 999999 | 0 | true | false | false | 17708606407318 | 0.12 |
注:
*表示测点的全部信息,若仅需返回单个信息或几个信息时,只需将*替换为相应的参数即可,如下:select id,alias,value from meas where id = 1000001表示获取ID为1000001的测点的id、别名和默认值配置信息;select id,is_discrete from meas where id = 1000001表示获取ID为1000001的测点的id、是否离散配置信息。
获取多个测点的配置信息:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数 |
|---|---|---|---|---|
| 65536 | 1 | 获取测点配置信息 | Source_Point | select * from points where id = 1000001 or id = 1000002 |
节点含义:获取ID为1000001和1000002的测点的全部配置信息。返回2*13的DataFrame。
注:
-
若需查询测点数量较多,可采用如下语法:
select * from points where id between 1000001 and 1000010,表示返回ID在1000001至1000010之间的所有测点的配置信息。 -
此外,若要求获取的信息按某一顺序排列,可采用
order by xxx asc实现,如:select * from points where id between 1000001 and 1000010 order by id asc,表示返回ID在1000001至1000010之间的所有测点的配置信息,并按测点ID进行排列。
(3)Source_File(文件)
在节点类型为Source的节点中,选择DF源类型为File时,可以读取文件作为数据输入(表格配置中选择Source_File类型)。具体配置方法为在参数中编辑文件路径,举例如下:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数1 | 参数2 |
|---|---|---|---|---|---|
| 65536 | 1 | 读取文件数据 | Source_File | C:\Users\Desktop\data.xlsx |
节点含义:读取桌面上文件data.xlsx的表格数据。
注:
-
支持xlsx、csv等文件格式的数据读取。
-
文件读入后,表格的表头将作为DataFrame的变量名。
-
当未指定路径,只声明了文件名时,将在
mems.exe所在文件夹中寻找所声明的文件,若不存在将报错。
(4)Source_Url(统一资源定位符,即网络链接)
在节点类型为Source的节点中,选择DF源类型为Url时,可以读取网络链接中的数据作为输入(表格配置中选择Source_Url类型)。具体配置方法为在参数中编辑文件路径,举例如下:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数1 | 参数2 |
|---|---|---|---|---|---|
| 65536 | 1 | 读取Url数据 | Source_Url | https://github.com/shufengdong/sparrowzz/blob/master/data/tetests/input.csv |
节点含义:读入ulr链接input.csv中的数据。
(5)Source_Data(数据)
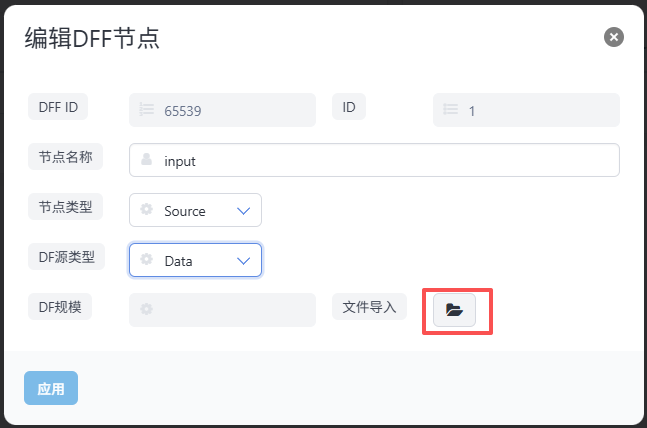
在节点类型为Source的节点中,选择DF源类型为Data时,可以导入文件作为数据输入。具体配置方法为在DFF配置页面的节点编辑窗口中点击文件导入按钮,然后选择相应文件,如下图所示:
注:
-
Source_Data与Source_File的区别:Source_Data是将文件内容内嵌到报表中(适合静态数据);Source_File是运行时动态读取文件(适合经常变化的数据)。 -
Source_Data会在加载时将文件内容一次性读取并内嵌到报表对象中,适合数据不经常变化的场景;如果数据需要动态更新,应使用Source_File。
(6)Source_Dev(设备)
在节点类型为Source的节点中,选择DF源类型为Dev时,可以读取设备信息作为数据输入(表格配置中选择Source_Dev类型)。具体配置方法可采用SQL语句的select获得设备信息,举例如下:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数1 | 参数2 |
|---|---|---|---|---|---|
| 65536 | 1 | 读取文件数据 | Source_Dev | select `101`,`102`,`103`,`104`,`105`, from Bus order by `101` |
节点含义:读取设备类型为Bus的所有设备的`101`,`102`,`103`,`104`,`105`属性值(每个属性形成一列),并且按`101`属性值进行排序。
注:
- 若需获取某设备的全部属性,可用
*实现,如下:select * from Bus表示获取Bus设备的全部属性值。
三、Transform
节点类型为Transform时,该节点可对节点中的数据进行变换后输出。在节点中可通过变换公式对数据进行变换操作,支持排序、两个表格数据拼接等各类变化操作。举例如下:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数 |
|---|---|---|---|---|
| 65536 | 2 | bus_meas | Transform | join(bus_points,points,[“point”],[“id”],inner) |
节点含义:将bus_points表和points表进行内连接。
四、TensorEval
节点类型为TensorEval时,该节点可用于编写脚本以实现复杂的张量运算,支持张量加、减、乘、幂、求逆、初等函数运算、复数运算、生成矩阵等各类张量运算。举例如下:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数1 | 参数2 |
|---|---|---|---|---|---|
| 65536 | 2 | 数据处理 | TensorEval | a = [[1001001],[1001002]]; b = [[123],[345]]; res_df1 = horzcat(a,b); return res_df1; | 3 |
节点含义:将矩阵a和b水平拼接为矩阵res_df1,并作为该节点的张量输出。其中,参数2中的3,表示脚本支持复数和矩阵运算操作。
注:
-
TensorEval节点所支持的脚本语言为RustScript(一种结合了 Rust 和 MATLAB 语法特征的脚本语言),其语法可以参考RustScript手册。
-
TensorEval节点可以选择配置不同的脚本操作。具体有如下选项:是否Polars、是否复数、是否矩阵、自定义名称、Multi-returns(是否多个返回值)。在表格配置中,通过参数2实现不同的选项,其数字和对应含义如下表所示:
参数2 含义 空 默认,操作选项均不选择 1 脚本支持复数运算 2 脚本支持矩阵运算 3 脚本支持复数和矩阵运算 4 脚本支持Polars运算 5 脚本支持Polars和复数运算 6 脚本支持Polars和矩阵运算 7 脚本支持Polars、复数和矩阵运算 8 脚本支持多个返回值 9 脚本支持多个返回值和复数运算 10 脚本支持多个返回值和矩阵运算 11 脚本支持多个返回值和复数、矩阵运算 12 脚本支持多个返回值和Polars运算 13 脚本支持多个返回值和Polars、复数运算 14 脚本支持多个返回值和Polars、矩阵运算 15 脚本支持多个返回值和Polars、矩阵和复数运算
五、Solve
节点类型为Solve时,可在节点中进行线性方程组的求解运算。举例如下:
举例如下:
方程组
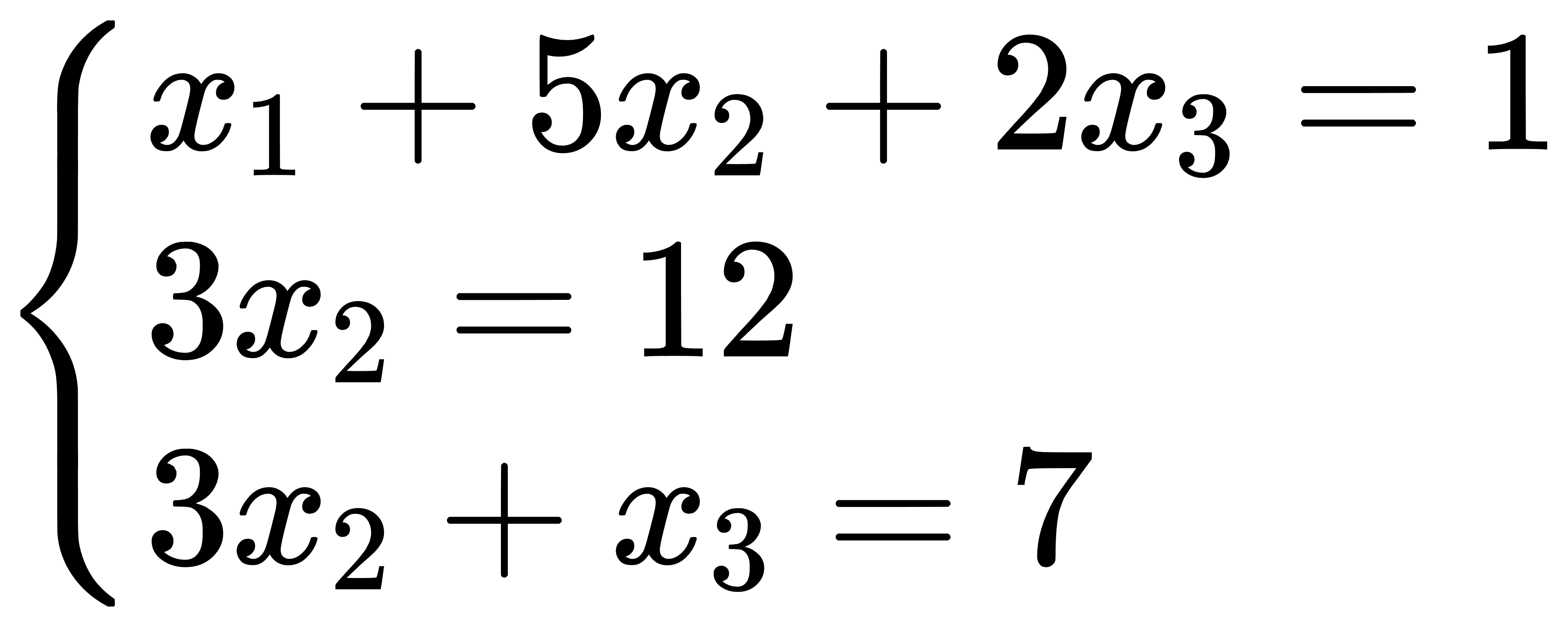
对于以上方程组的求解,DFF配置如下:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数 |
|---|---|---|---|---|
| 65536 | 1 | 系数矩阵 | Source_File | solve.csv |
| 65536 | 2 | 解方程 | Solve | function; |
| FLOW ID | 首尾节点 | 动作名称 | 动作类型 | 动作参数 |
|---|---|---|---|---|
| 65536 | 1;2 | function | None |
方程组系数矩阵(solve.csv)输入如下:
| x1 | x2 | x3 | b |
|---|---|---|---|
| 1 | 5 | 2 | 1 |
| 0 | 3 | 0 | 12 |
| 0 | 3 | 1 | 7 |
节点含义:节点1中方程组系数矩阵,并通过动作1传递到节点2;节点2中对输入的方程组进行求解。求解结果为:
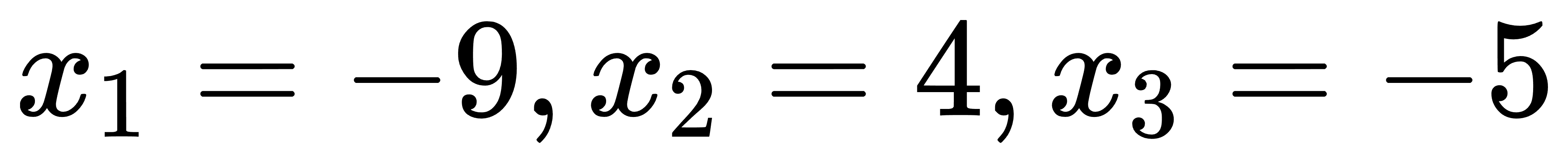
六、NLSolve
节点类型为NLSolve时,可在节点中进行非线性方程组的求解运算。举例如下:
方程组
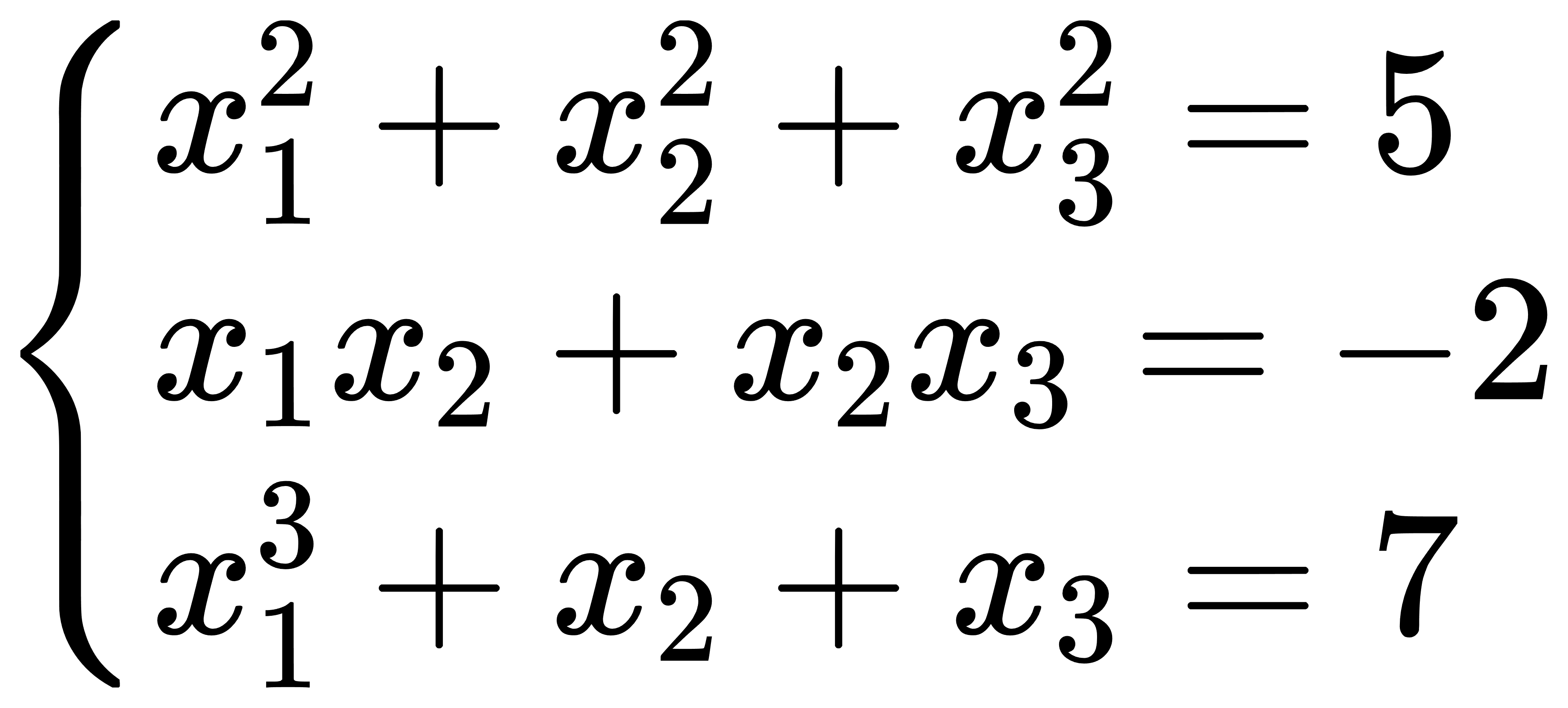
对于以上方程组的求解,DFF配置如下:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数 |
|---|---|---|---|---|
| 65536 | 1 | 方程组输入 | Source_File | NLsolve.csv |
| 65536 | 2 | 解方程 | NLSolve | function; |
| FLOW ID | 首尾节点 | 动作名称 | 动作类型 | 动作参数 |
|---|---|---|---|---|
| 65536 | 1;2 | function | None |
非线性方程组(NLsolve.csv)输入如下:
| x_name | init | equation |
|---|---|---|
| x1 | 1 | x1^2+x2^2+x3^2-5 |
| x2 | -1 | x1*x2+x2*x3+2 |
| x3 | 0 | x1^3+x2+x3-7 |
节点含义:节点1中读入非线性方程组,并通过动作1传递到节点2;节点2中对输入的非线性方程组进行求解。求解结果为:
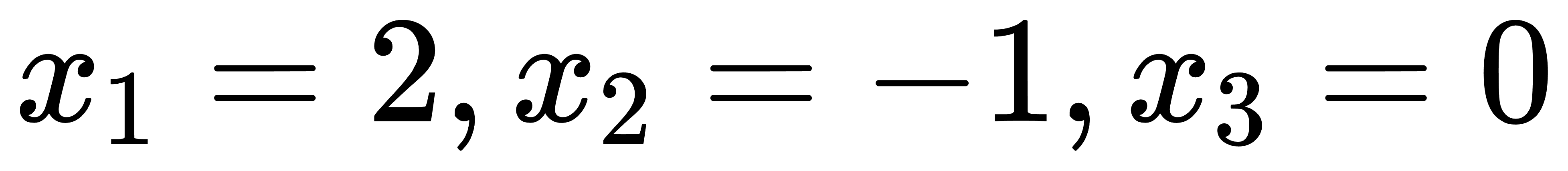
七、MILP
节点类型为MILP时,可在节点中进行混合整数线性规划运算。MILP类型节点至少有2个入边,分别包含混合整数线性规划的目标函数和约束条件数据,数据格式如下:
#1)目标函数:
x type lower upper c
其中:x表示变量名;type表示变量类型,1表示0-1二进制变量,2表示整型变量,3表示实数型变量;lower表示变量下限;upper表示变量上限;c表示变量系数
此外,默认求解最大值(max)。
#2)约束条件:
x1 …… xi b type
其中:x1-xi表示每条约束条件中变量的系数;b表示常量;type为1表示表达式≥0,为-1表示表达式≤0。
举例如下:
目标函数
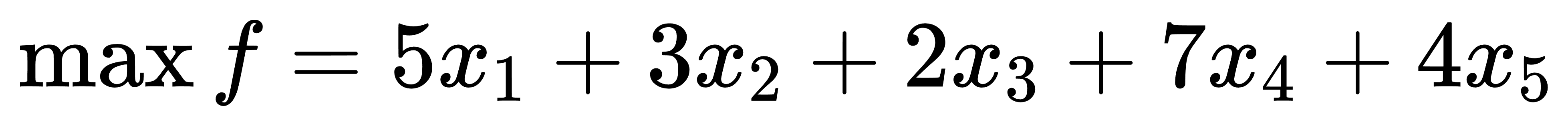
约束条件
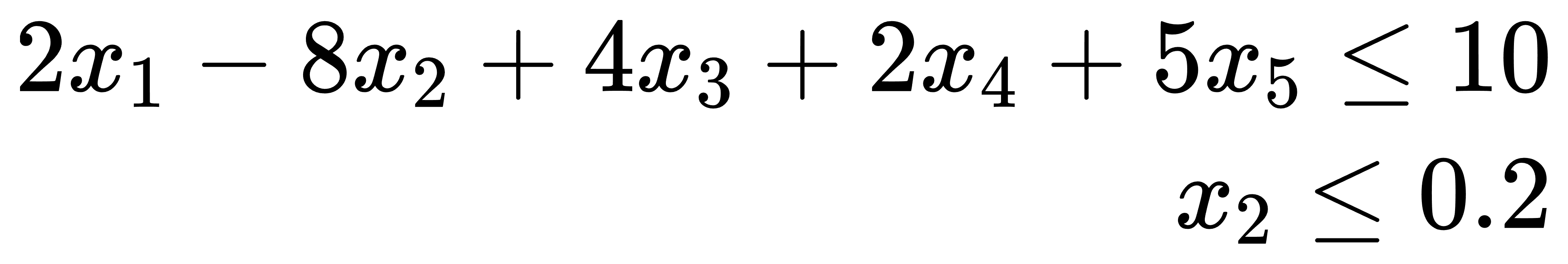
变量类型

对于以上MILP模型的求解,DFF配置如下:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数 |
|---|---|---|---|---|
| 65536 | 1 | 输入目标函数 | Source_File | milp_obj.xlsx |
| 65536 | 2 | 输入约束条件 | Source_File | milp_cons.xlsx |
| 65536 | 3 | 求解 | MILP | obj;constraint; |
| FLOW ID | 首尾节点 | 动作名称 | 动作类型 | 动作参数 |
|---|---|---|---|---|
| 65536 | 1;3 | obj | None | |
| 65536 | 2;3 | constraint | None |
目标函数矩阵(milp_obj.xlsx)输入如下:
| x | type | lower | upper | c |
|---|---|---|---|---|
| x1 | 2 | 0 | 5 | |
| x2 | 3 | 0 | 3 | |
| x3 | 2 | 0 | 2 | |
| x4 | 2 | 0 | 7 | |
| x5 | 2 | 0 | 4 |
约束条件矩阵(milp_cons.xlsx)输入如下:
| x1 | x2 | x3 | x4 | x5 | b | type |
|---|---|---|---|---|---|---|
| 2 | -8 | 4 | 2 | 5 | 10 | -1 |
| 0 | 1 | 0 | 0 | 0 | 0.2 | -1 |
节点含义:节点1中读入目标函数矩阵,并通过动作1传递到节点3;节点2中读入约束条件矩阵,并通过动作2传递到节点3;节点3对输入的MILP矩阵进行求解。求解结果为:
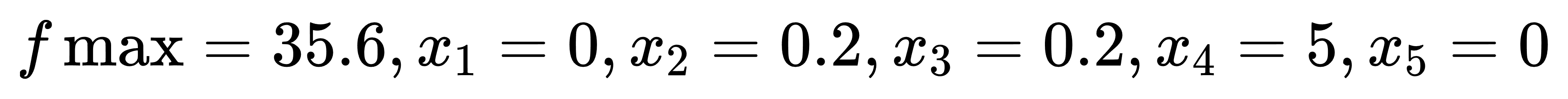
八、NLP
节点类型为NLP时,可在节点中进行非线性规划运算。NLP类型节点至少有2个入边,分别包含非线性规划的变量和表达式数据,数据格式如下:
#1)变量:
x_name lower upper init
其中:x_name表示变量名;lower表示变量下限;upper表示变量上限;init表示变量计算初始值(可为空)。
#2)表达式(目标函数和约束条件):
equations lower upper
其中:equations表示表达式;lower表示表达式的下限(可为空);upper表示表达式的上限(可为空)。
第一行为目标函数(默认计算最小值,无需填写上下限),第二行起表示约束条件。
举例如下:
目标函数
约束条件
变量类型
对于以上NLP模型的求解,DFF配置如下:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数 |
|---|---|---|---|---|
| 65536 | 1 | 输入变量 | Source_File | nlp_x.xlsx |
| 65536 | 2 | 输入目标函数和约束条件 | Source_File | nlp_obj_cons.xlsx |
| 65536 | 3 | 求解 | NLP | nlp_x;nlp_obj_cons; |
| FLOW ID | 首尾节点 | 动作名称 | 动作类型 | 动作参数 |
|---|---|---|---|---|
| 65536 | 1;3 | nlp_x | None | |
| 65536 | 2;3 | nlp_obj_cons | None |
目标函数(nlp_x.xlsx)输入如下:
| x | type | lower | init |
|---|---|---|---|
| x1 | 1 | 5 | |
| x2 | 1 | 5 | |
| x3 | 1 | 5 | |
| x4 | 1 | 5 |
目标函数和约束条件(nlp_obj_cons.xlsx)输入如下:
| equations | lower | upper |
|---|---|---|
| x1 * x4 * (x1 + x2 + x3) + x3 | ||
| x1 * x2 * x3 * x4 | 25 | 2e19 |
| x1^2 + x2^2 + x3^2 + x4^2 | 40 | 40 |
节点含义:节点1中读入NLP的变量配置,并通过动作1传递到节点3;节点2中读入NLP的目标函数和约束条件,并通过动作2传递到节点3;节点3对输入的NLP矩阵进行求解。求解结果为:
4.5.3 DFF边定义
DFF边定义部分的配置内容包括DFF ID、首尾节点、边名称、边描述、边类型及其参数。
| DFF ID | 首尾节点 | 边名称 | 描述 | 边类型 | 参数 |
|---|---|---|---|---|---|
| <u64> | <u64>;<u64> | <String> | <String> | None Eval Sql Onnx OnnxUrl Nnef NnefUrl WriteFile WriteSql | < \ > <String> <String> <String> <String> <String> <String> <String> <String> |
-
DFF ID:声明边属于哪个DFF,用<u64>(64位无符号整数)表示。
-
首尾节点:边需要声明首尾节点,用一对正整数表示,格式为:<尾节点ID>;<首节点ID>。边的方向为:尾节点→首节点。节点ID与DFF节点定义中相对应。
-
边名称:便于理解边内容,往往是对边的动作做简要文字解释,用<String>(表示字符串类型)表示。
-
边描述:用于解释边动作的具体作用,用<String>(表示字符串类型)表示。
-
边类型:用约定的类型声明表示,包含如下类型:None、Eval、Sql、Onnx、OnnxUrl、Nnef、NnefUrl、WriteFile、WriteSql。
-
边参数:不同边类型的参数配置要求不同,具体要求如下。
边类型示例说明
一、None
边类型为None时,边不动作。特殊的,当边名称设置为需要传递的变量名,可以传递变量(只能传递一个变量)。
| DFF ID | 首尾节点 | 边名称 | 描述 | 边类型 | 参数 |
|---|---|---|---|---|---|
| 65536 | 1;2 | bus | None |
边含义:将节点1中获得的变量bus传递给节点2,作为节点2的输入变量。
二、Eval
边类型为Eval时,边可执行张量计算。举例如下:
| DFF ID | 首尾节点 | 边名称 | 描述 | 边类型 | 参数 |
|---|---|---|---|---|---|
| 65536 | 1;2 | 数据转换 | Eval | select(alias(cast(col(value),f32),r_1_1_672)); |
边含义:将名为value的数据进行强制类型转换为f32类型,并改名为r_1_1_672。
三、Onnx
边类型为Onnx时,边执行神经网络动作。举例如下:
| DFF ID | 首尾节点 | 边名称 | 描述 | 边类型 | 参数 |
|---|---|---|---|---|---|
| 65536 | 2;3 | 负荷预测 | Onnx | model.onnx |
边含义:节点2输入的数据作为神经网络的输入,经过model.onnx后输出数据至节点3。
注:
- 参数为Onnx文件的路径。
- 节点2输入的DF数据需要和
model.onnx的输入维度对应。
具体例子:负荷预测。
四、WriteFile
边类型为WriteFile时,边可将DataFrame流数据写至指定路径文件中保存,或用DataFrame更新指定数据源id的量测值。对于这两种动作模式,WriteFile动作逻辑如下:如果参数为“meas://x”, 表示用DataFrame更新数据源id为x的量测值;其他形式的参数表示文件路径,表示将DataFrame写到文件。需要注意的点:
-
对于“meas://x”,输入的DataFrame需包含“point”和“discete或analog”两列信息。其中,“point”的列表示测点号,如果有“discete”的列表示更新离散量,如果有“analog”的列表示更新模拟量,注意discrete或analog不能同时出现。
-
WriteFile动作通过“meas://x”,一般设置数据源非0的量测,或者数据源为0的本地测点,不可以设置数据源为0的远方测点,远方测点只能间接通过AOE设置。
-
WriteFile动作通过“meas://x”更新量测值后,后续的节点或边如果需要用到该动作设置后的量测的数据,由于异步的关系,并不能保证是更新后的值。
-
DataFrame写到文件支持输出
xlsx或csv格式。文件可指定路径,若未指定则默认mems.exe所在文件夹。
举例如下:
| DFF ID | 首尾节点 | 边名称 | 描述 | 边类型 | 参数 |
|---|---|---|---|---|---|
| 65536 | 3;4 | 结果输出 | WriteFile | output.csv |
边含义:将节点2输入的数据写至output.csv文件中保存。
| DFF ID | 首尾节点 | 边名称 | 描述 | 边类型 | 参数 |
|---|---|---|---|---|---|
| 65536 | 3;4 | 结果输出 | WriteFile | meas://1 |
边含义:用DataFrame更新数据源id为1的量测值,注意此时节点2输入数据需包含“point”列和“discete/analog”列。
4.5.4 不同DFF之间传递DataFrame
MEMS支持不同DFF之间传递DataFrame,包括在同一MEMS中不同DFF之间传递DataFrame、在不同MEMS的DFF之间传递DataFrame。
4.5.4.1 接收其他DFF的DataFrame的DFF配置
接收其他DFF的DataFrame的DFF,需要将DFF触发类型设置为DataSource数据源驱动,如下:
| DFF ID | 是否启用 | 名称 | 触发条件 | 触发条件参数 | 存储模式 | 目标AOE | AOE变量名称 |
|---|---|---|---|---|---|---|---|
| <u64> | <Bool> | <String> | DataSource | <String> | EveryTime Once Memory Never | <u64> | <String> |
若该DFF有多个数据源类型节点,且需要特定数据源节点都收到数据后再执行DFF,则触发条件参数填写特定节点编号,并用;分割,例如:若节点1和节点2接收其他DFF的数据,且均收到数据后再执行DFF,则该DFF的触发条件参数填写1;2。
在DFF节点中配置类型为SOURCE_OTHER的节点接收其他DFF的DataFrame:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数 |
|---|---|---|---|---|
| <u64> | <u64> | <String> | SOURCE_OTHER | <String> |
若是接收其他MEMS的DataFrame,则节点参数填写0;若是接收同一MEMS其他DFF的DataFrame,则节点参数填写其他DFF的id。
4.5.4.2 向其他DFF发送DataFrame的DFF配置
向其他DFF发送DataFrame的DFF,需要在DFF边中配置类型为WriteFile的边发送DataFrame。
| DFF ID | 首尾节点 | 边名称 | 描述 | 边类型 | 参数 |
|---|---|---|---|---|---|
| <u64> | <u64>;<u64> | <String> | <String> | WriteFile | mems://beeId/DFF_id/node_id |
参数写法中,mems://表示是将DataFrame发送到其他DFF,后面分别是写入MEMS的beeId、DFF id和节点id。注意只有在边接收到非空的DataFrame,才会向其他DFF发送数据,否则在边中不进行操作。
4.5.4.3 接收其他MEMS的DataFrame的通信配置
要在2个MEMS之间传递DataFrame,还要建立2个MEMS之间的通信,MEMS默认使用端口7058和7059监听其他MEMS的连接,监听端口也可在config配置文件中进行设置,写法如下:
emsListenPort=7058
emsRtMsgListenPort=7059
在另一个MEMS的config配置文件配置接入MEMS的IP和端口,如下所示,其中cloudURL3和cloudURL4为参数名称,beeId为接入MEMS的beeId,127.0.0.1为接入MEMS的IP,7058和7059为接入MEMS的端口:
cloudURL3 = beeId/127.0.0.1:7058
cloudURL4 = 127.0.0.1:7059
上述配置也可在MEMS界面设置项-云中进行配置,如下图所示。
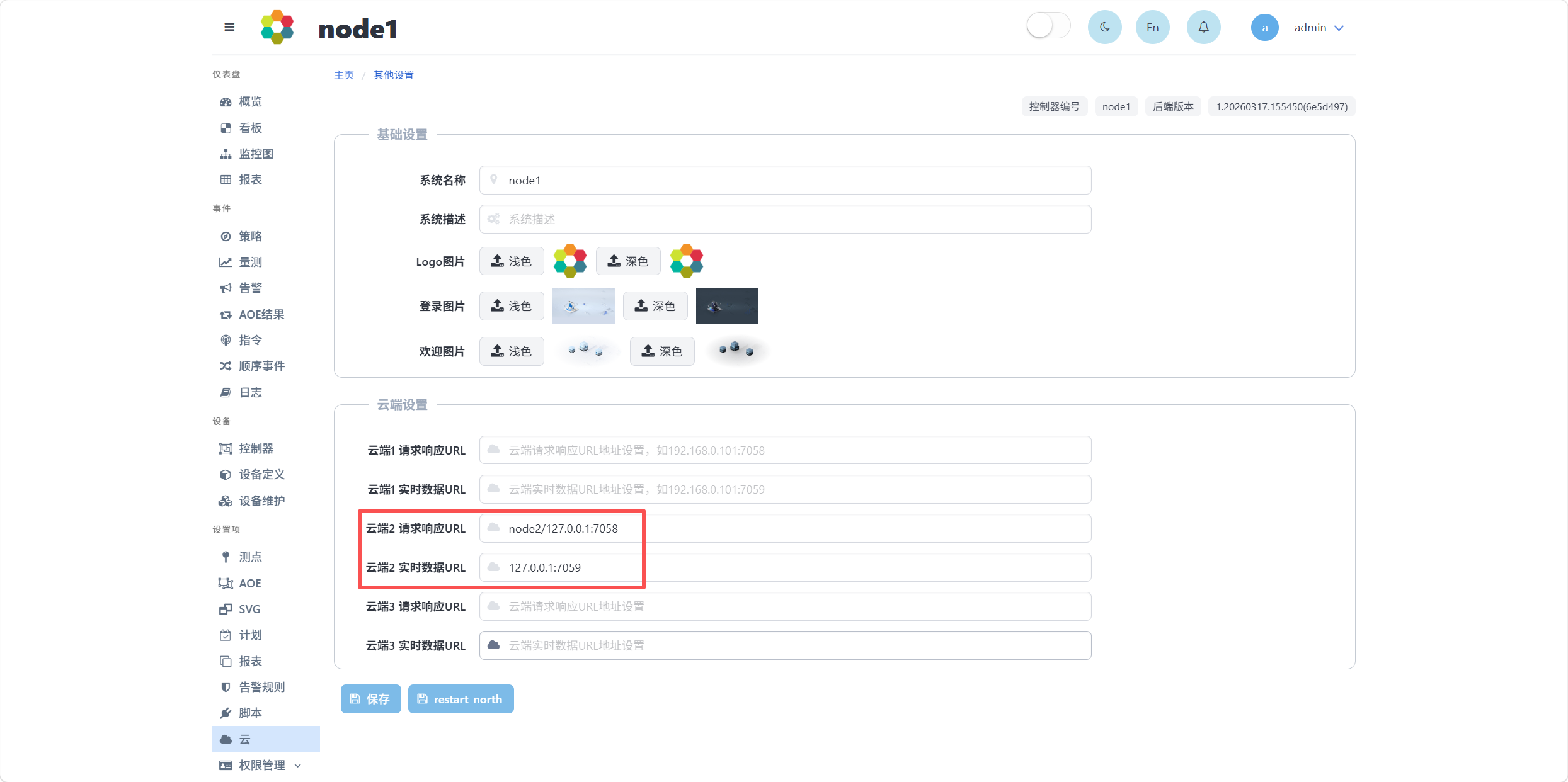
图中,node2为接入MEMS的beeId,127.0.0.1为接入MEMS的IP,7058和7059为接入MEMS的端口。
4.5.4 DFF运行结果展示
DFF运行结果可在MEMS界面仪表盘-报表中展示。其中,界面左侧显示了DFF列表。
选中其中一条DFF记录,可以看到DFF运行的时间,并点击选择时间记录。
界面右侧上方显示了可选择的结果展示模板,包括表格、散点图、柱状图、饼图等。选中需要的展示模板,再点击应用图标即可展示结果。
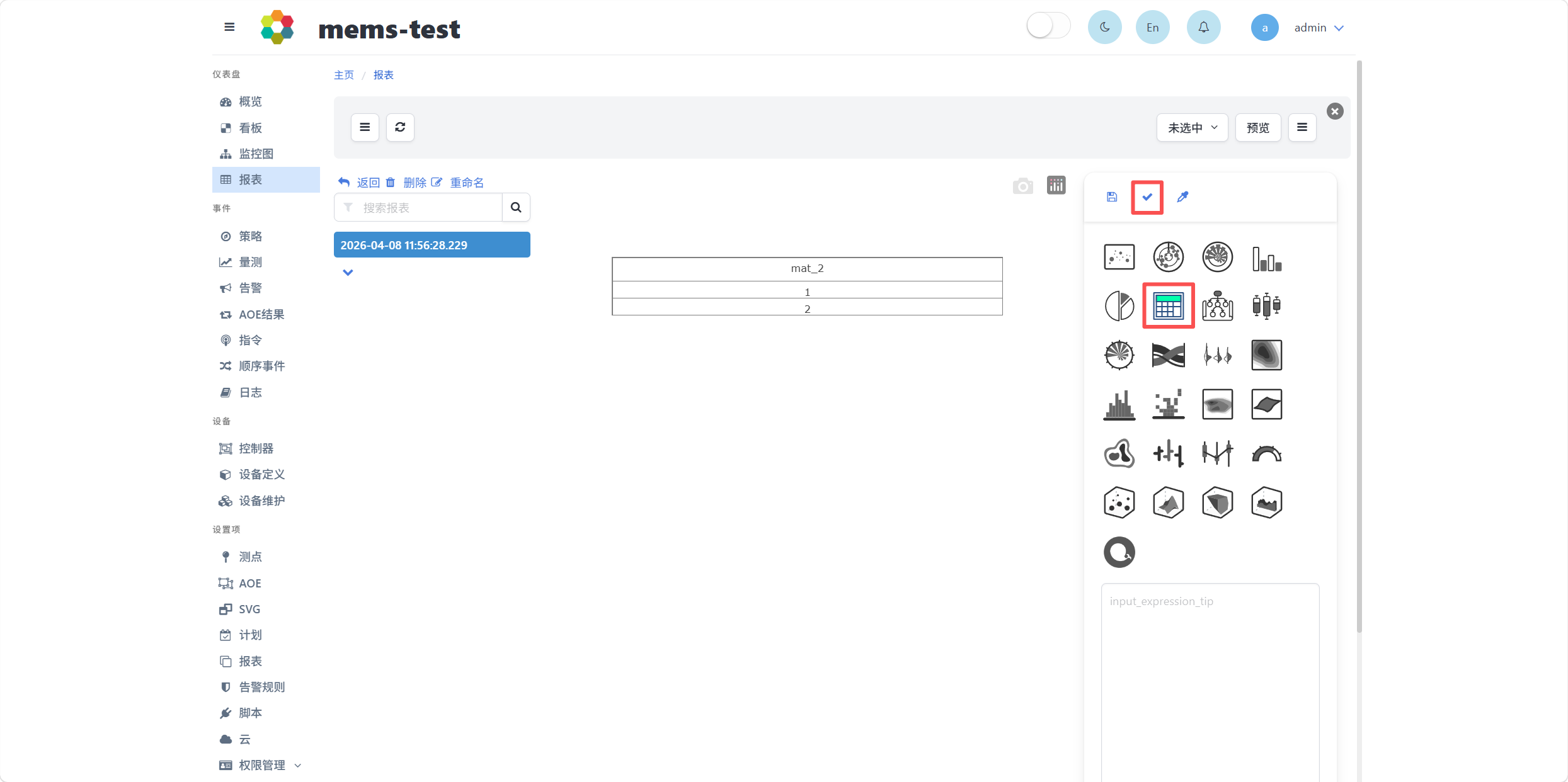
界面右下角显示了输出结果的列信息,可选择需要展示的列。
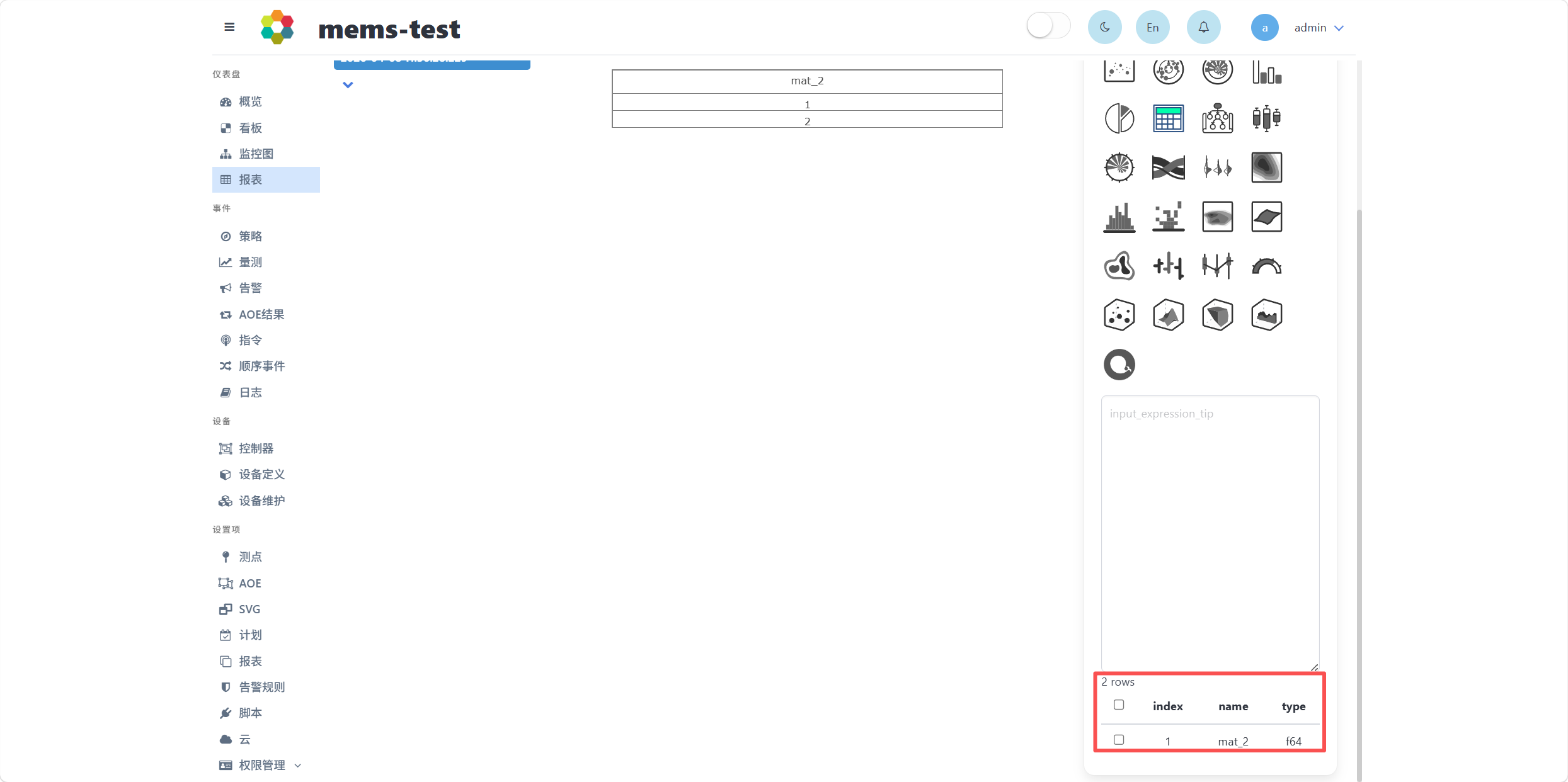
点击提交按钮,在弹出的窗口中输入报表名称,点击确定,即可保存该结果。
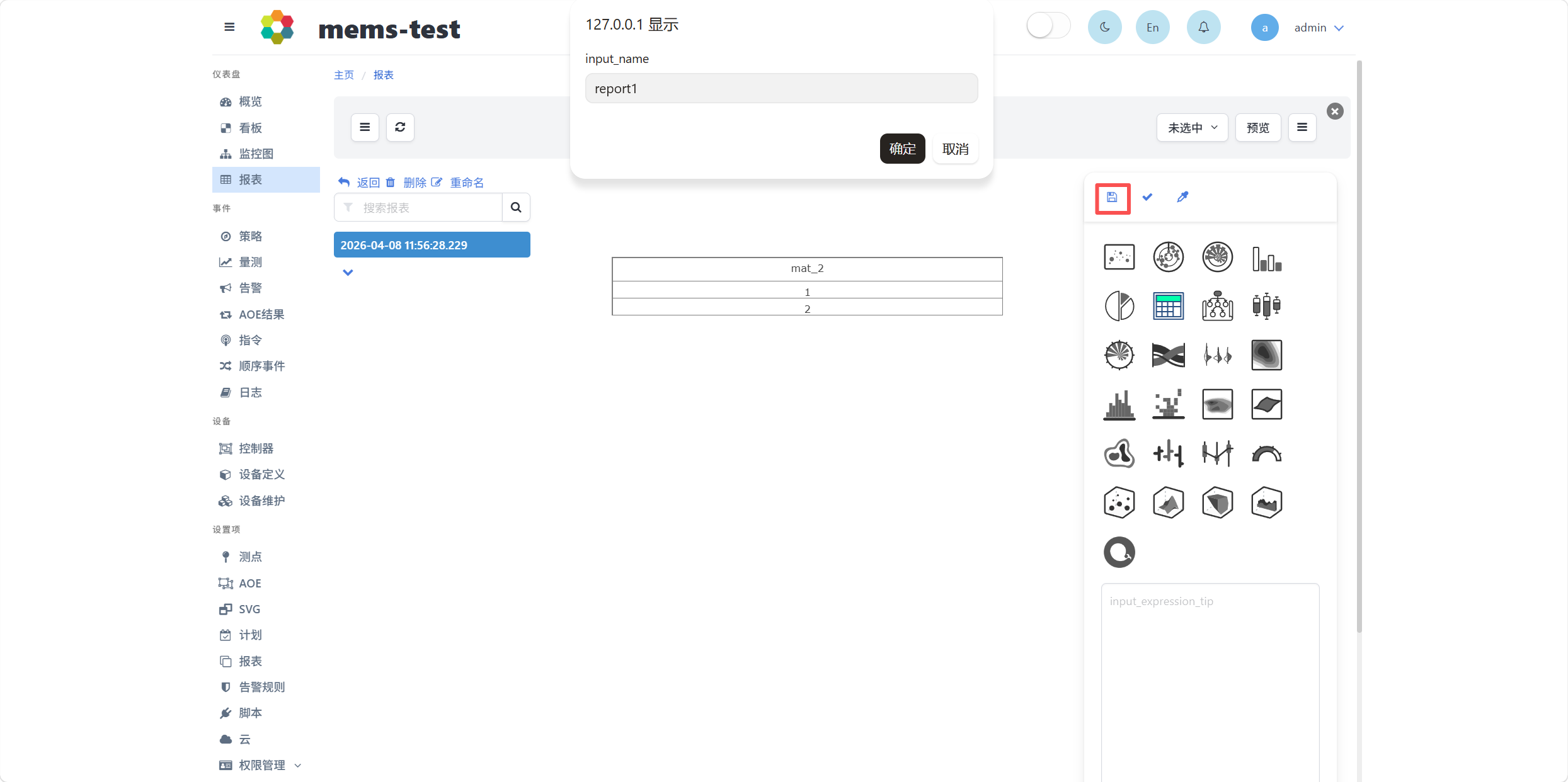
点击界面右上方的预览按钮,可显示所保存的DFF结果列表,如下图所示。
4.6 告警配置
MEMS可对设备告警规则进行配置。用户可在设置项-告警规则界面中设定触发条件与关联测点,系统便能自动实时监测量测变化并即时作出告警提醒。
点击添加新告警定义按钮,在弹出的新告警定义窗口中填写配置信息即可,如下图所示。
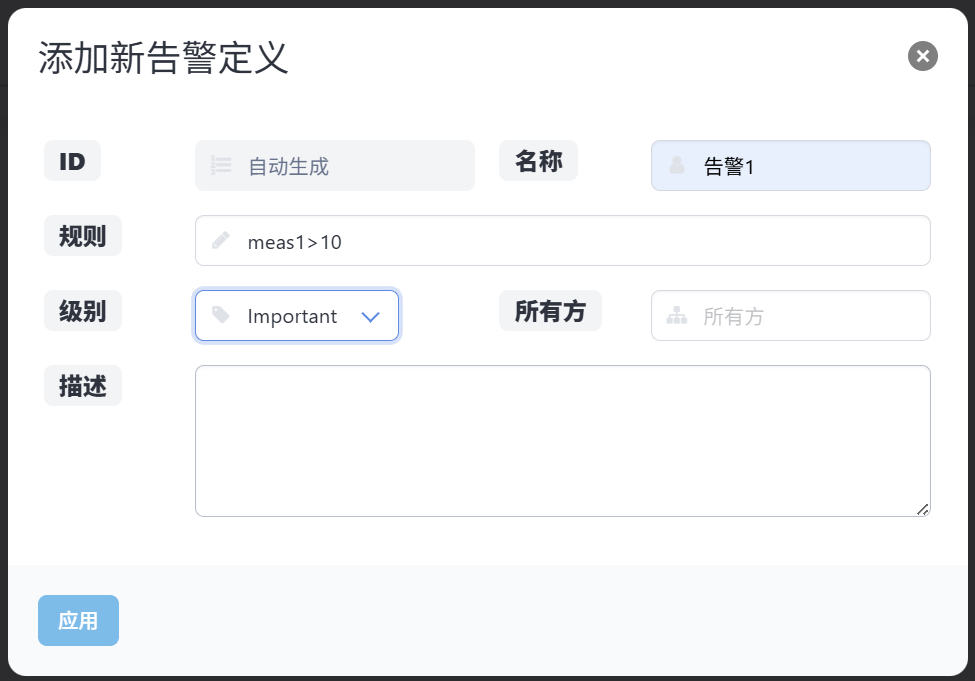
配置内容包括:告警名称、规则、级别、所有方和描述,具体如下:
-
告警规则 ID:不同告警规则的标识,用<u64>(64位无符号整数)表示。
-
告警名称:表达告警规则的内容,便于理解,用<String>(表示字符串类型)表示。
-
规则:判断公式,当公式成立时将会产生告警。
-
级别:用约定的类型声明表示,按重要等级分为Emergency、Impotent、Common三类。
-
所有方:选填,配置可查看和确认告警信息的用户权限。
-
描述:选填,用于解释告警规则的具体信息。
此外,点击编辑告警配置按钮,可以配置不同等级告警的提示效果,如下图所示。

通过点击工具栏的导出按钮,可将设置的告警规则导出为文件,文件格式如下所示。
通过点击从文件导入按钮,可将满足上述格式要求的告警规则配置文件导入。
4.7 脚本配置
MEMS支持通过通用的Javascript文件和wasm脚本文件进行控制策略和业务逻辑定义配置,通过导入控制策略或业务逻辑对应的脚本可自动生成控制策略和业务分析运算流程,在控制策略和业务逻辑较为复杂时,可降低配置工作量、提升开发效率。
4.7.1 新建脚本文件节点
在设置项-脚本中,点击新脚本文件节点按钮,在弹出的窗口中输入脚本文件的路径名,点击确定,完成新建脚本节点。
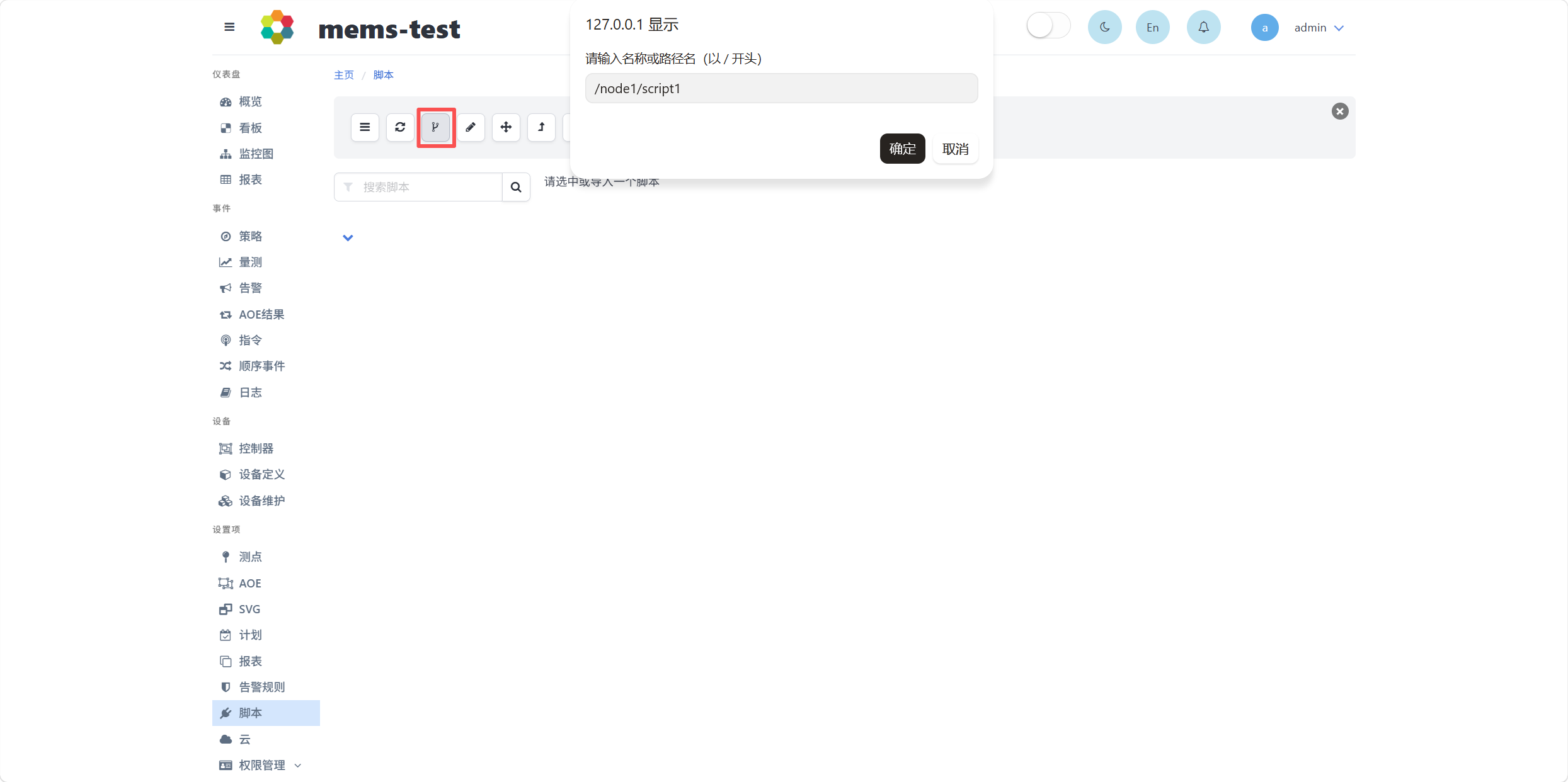
注意输入的路径名需以/开头,同时路径名中以/分隔不同层次的节点,从而以树形结构形成新的脚本文件节点。其中第一个/后的脚本文件节点为树根节点,以/分隔的前后两个节点中,后一个节点为前一个节点的子节点。
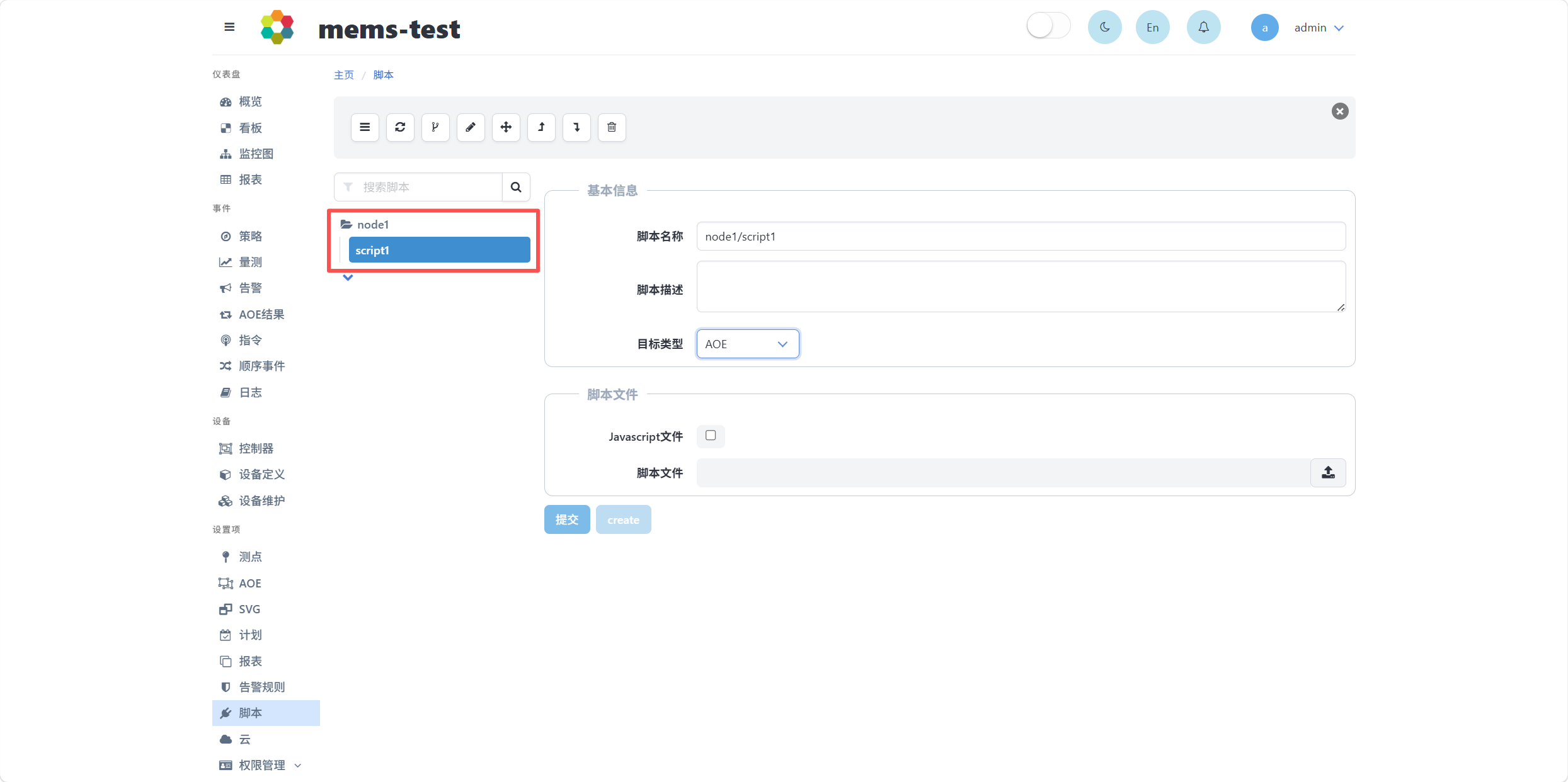
完成脚本节点新建后,页面中将以树形结构显示脚本文件节点列表,如下图所示,node1为一个树根节点,script1为node1的子节点。
4.7.2 脚本文件配置
点击选中脚本文件节点后,页面上会显示脚本文件节点的配置项。在上方的基本信息框中,第一项显示了该脚本名称,第二项为脚本描述,其中可输入对该脚本的说明性描述内容,第三项为目标类型,值可选AOE和DataFrame流中的一个,点击该项文本框后将出现下拉菜单,可对目标类型进行选择。
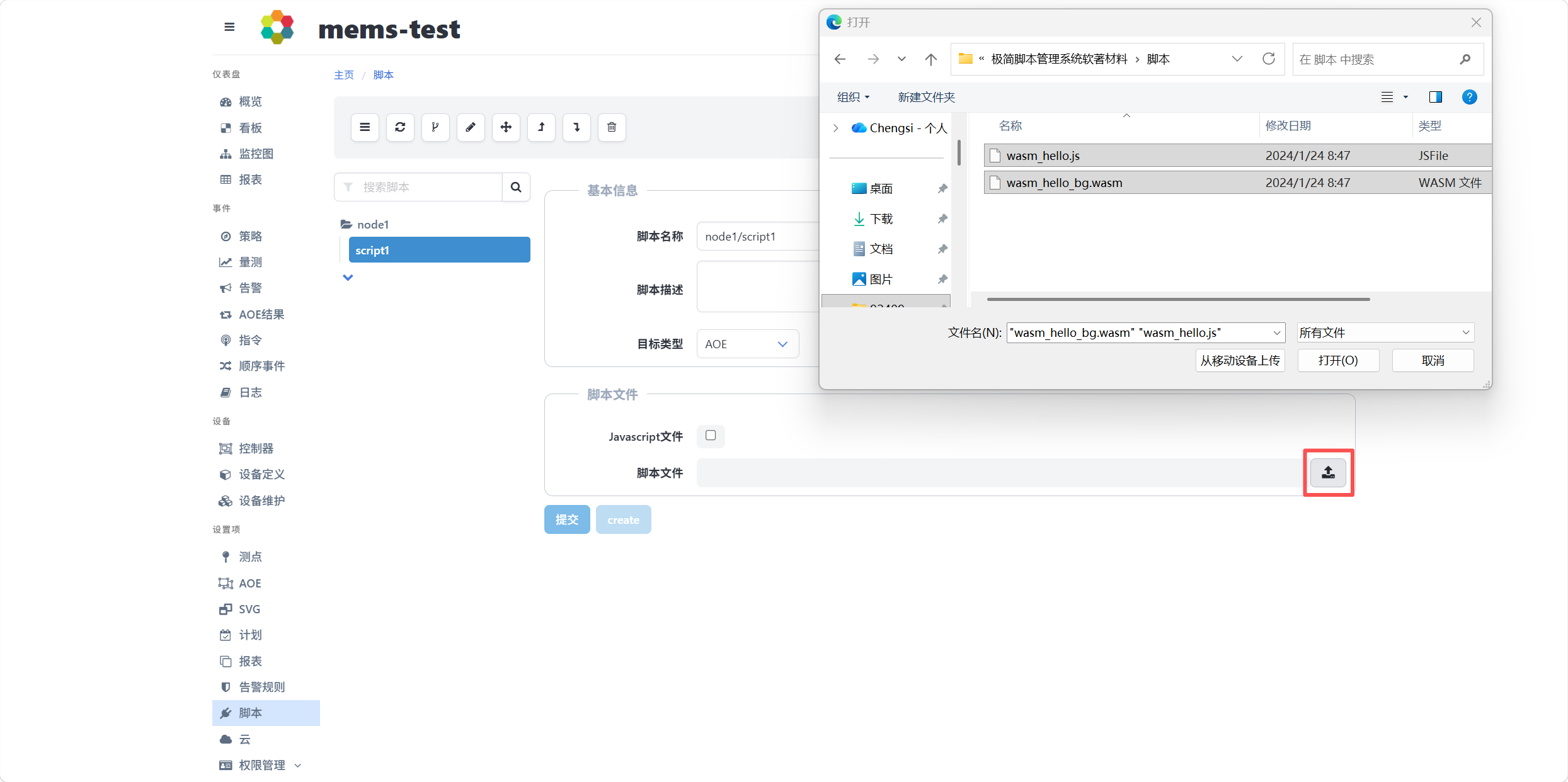
在下方的脚本文件框中,可进行脚本文件导入操作。点击上传按钮,可打开本地脚本文件选择窗口,选中要上传的Javascript文件和wasm脚本文件,点击打开按钮或双击文件图标即可将文件上传,如下图所示。
然后,依次点击提交和create按钮,即可执行脚本,生成AOE控制策略或DataFrame流。
脚本执行之后显示下图所示结果信息,其中包含了AOE策略信息。
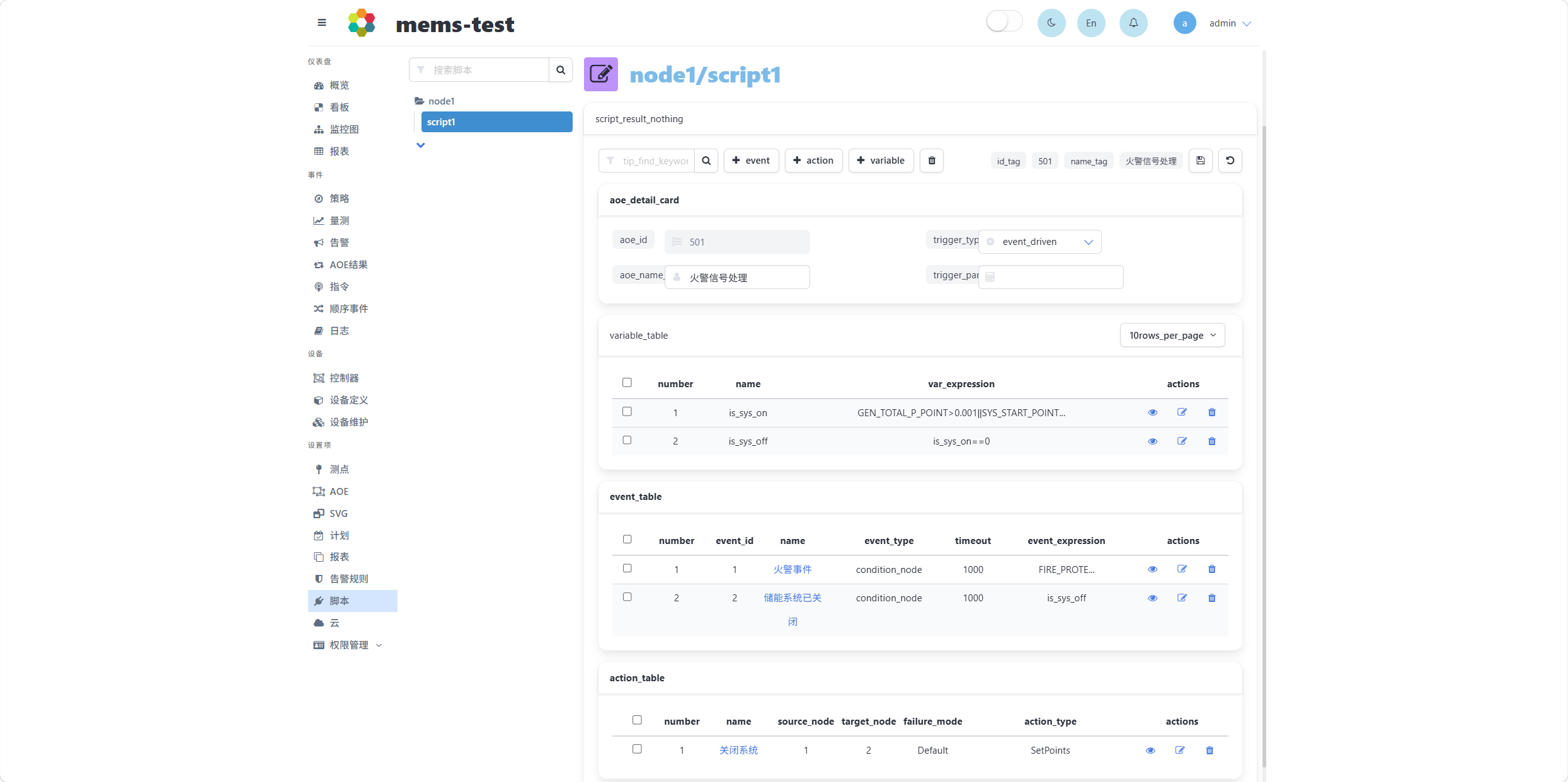
上图中,aoe_detail_card一栏显示了AOE策略基本信息,包括AOE id、控制策略触发类型、AOE名称、触发条件参数;variable_table一栏显示了定义的变量列表,包括变量名称和变量值计算表达式信息;event_table一栏显示了AOE节点定义信息,包括节点id、节点事件名称、节点类型、节点事件触发超时时间和节点事件判断表达式等信息;action_table一栏显示了AOE边定义信息,包括边名称、边所连接的首节点和尾节点id、边上动作执行失败后的处理方式、边类型和边上的动作定义等信息。
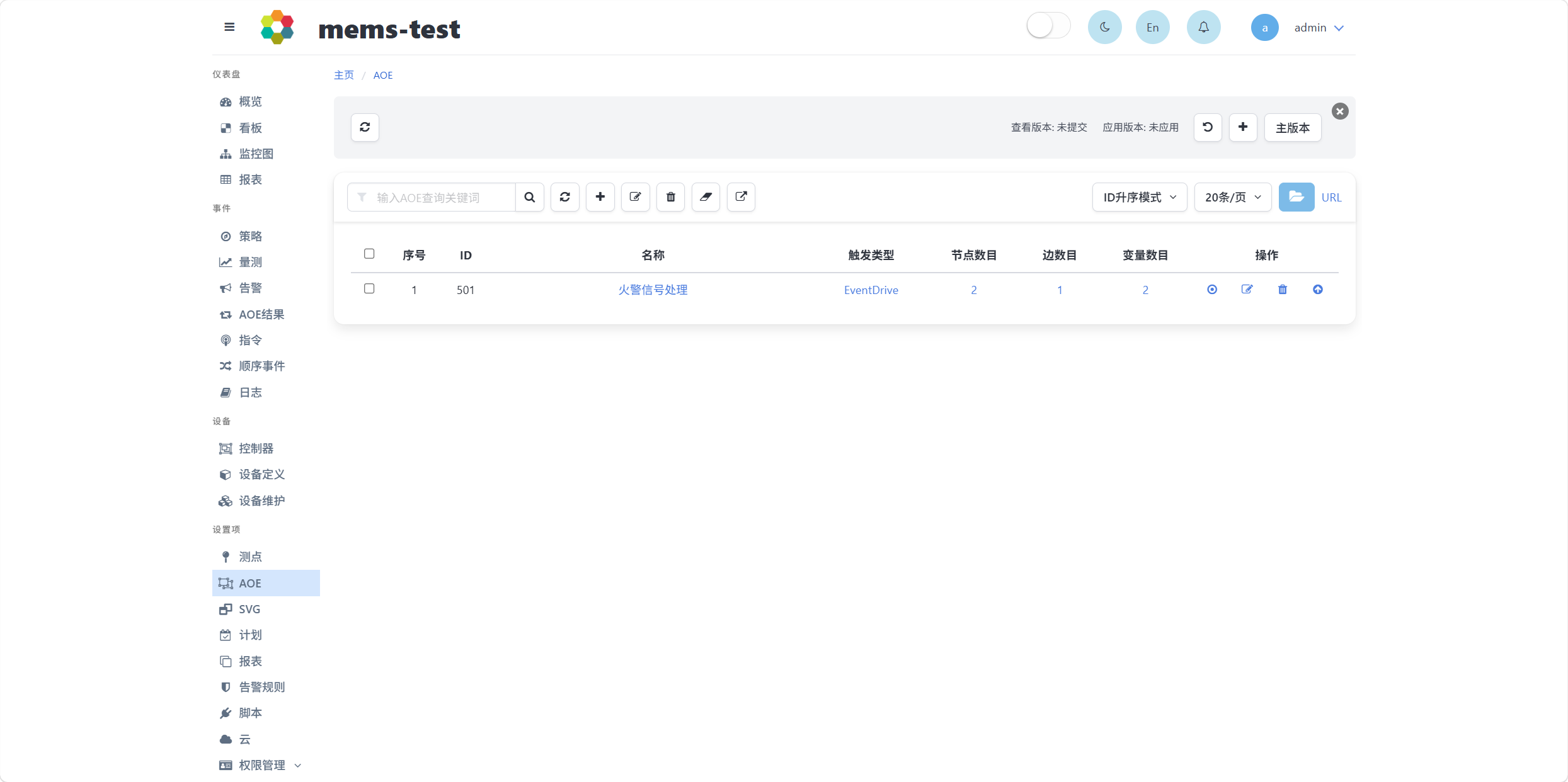
点击保存按钮保存脚本文件生成的策略。在AOE页面或报表页面中可以看到所生成的对应策略记录。上述脚本配置例子生成了一条AOE记录,如下图所示。
云配置
4.9 看板配置
MEMS看板可自定义布局,设置和展示曲线图、测点值列表、指令列表、告警信息、控制策略等内容,在配置页面上可与测点、控制策略、计划曲线等信息进行关联,方便灵活地实现能量管理系统典型展示内容。
4.9.1 看板布局
看板通过Excel配置文件来生成看板布局。使用Excel文件中的第一个工作表作为布局定义,每个单元格代表看板中的一个板块,单元格的值表示该板块的高度,合并单元格表示一个较大的板块区域。布局规则为:
- 板块大小:通过合并单元格来创建不同大小的板块。例如:合并2行1列的单元格创建一个高度为2倍的板块,合并1行2列的单元格创建一个宽度为2倍的板块。
- 板块高度:在每个单元格中输入数字表示该板块的高度(像素,未输入值的单元格默认为100px高度)。
在仪表盘-看板中,点击上传布局文件按钮,在弹出的窗口中选择Excel布局文件(布局文件示例),输入新建看板名称,点击确定完成新建看板。
4.9.2 看板内容配置
对于看板中的每一个板块,可自定义设置板块类型和展示内容。点击设置此板块文字,在弹出的窗口选择板块类型,并配置相应的参数,板块类型和对应配置参数如下:
- SVG板块:选择SVG文件路径
- 图表板块:选择模板、时间范围、测点和计划
- 量测板块:选择时间范围、测点和是否实时
- 告警板块:选择时间范围
- AOE板块:选择AOE模型
- 指令板块:选择时间范围
- SOE板块:选择时间范围
- 报表板块:选择时间范围和报表模型
- AOE监控板块:无
- AOE结果板块:选择时间范围
- 测点赋值板块:选择是否垂直显示
- 插件板块:上传插件文件
4.10 概览插件配置
MEMS概览页面支持用户通过导入插件的方式,在前端界面中添加自定义展示模块,该模块具有以下特点:
- 自定义界面模块:支持开发和部署自定义的前端界面组件。
- 动态扩展系统功能:无需修改系统核心代码,通过插件方式扩展功能。
- 独立部署和更新:插件可以单独开发、部署和更新,不影响系统其他部分。插件文件以7z压缩包形式上传,系统自动解压并部署插件,支持插件的版本管理和更新。
插件开发流程如下:
- 开发前端组件(HTML、CSS、JavaScript/WASM)
- 打包为7z压缩文件
- 上传插件压缩文件
- 系统自动部署插件
- 在概览或其他界面中使用插件
通过插件功能模块,MEMS实现了高度可扩展性,允许用户根据具体需求定制和扩展界面功能,而无需修改核心代码。
4.10.1 新建插件
在仪表盘-概览中,点击新建插件按钮,在弹出的窗口中输入插件的路径名,点击确定,完成新建插件。

注意输入的路径名需以/开头,同时路径名中以/分隔不同层次的节点,从而以树形结构形成新的插件节点。其中第一个/后的插件节点为树根节点,以/分隔的前后两个节点中,后一个节点为前一个节点的子节点。
4.10.2 插件配置
完成插件新建后,页面中将以树形结构显示插件节点列表,如下图所示,plugin为一个树根节点,test1为plugin的子节点。
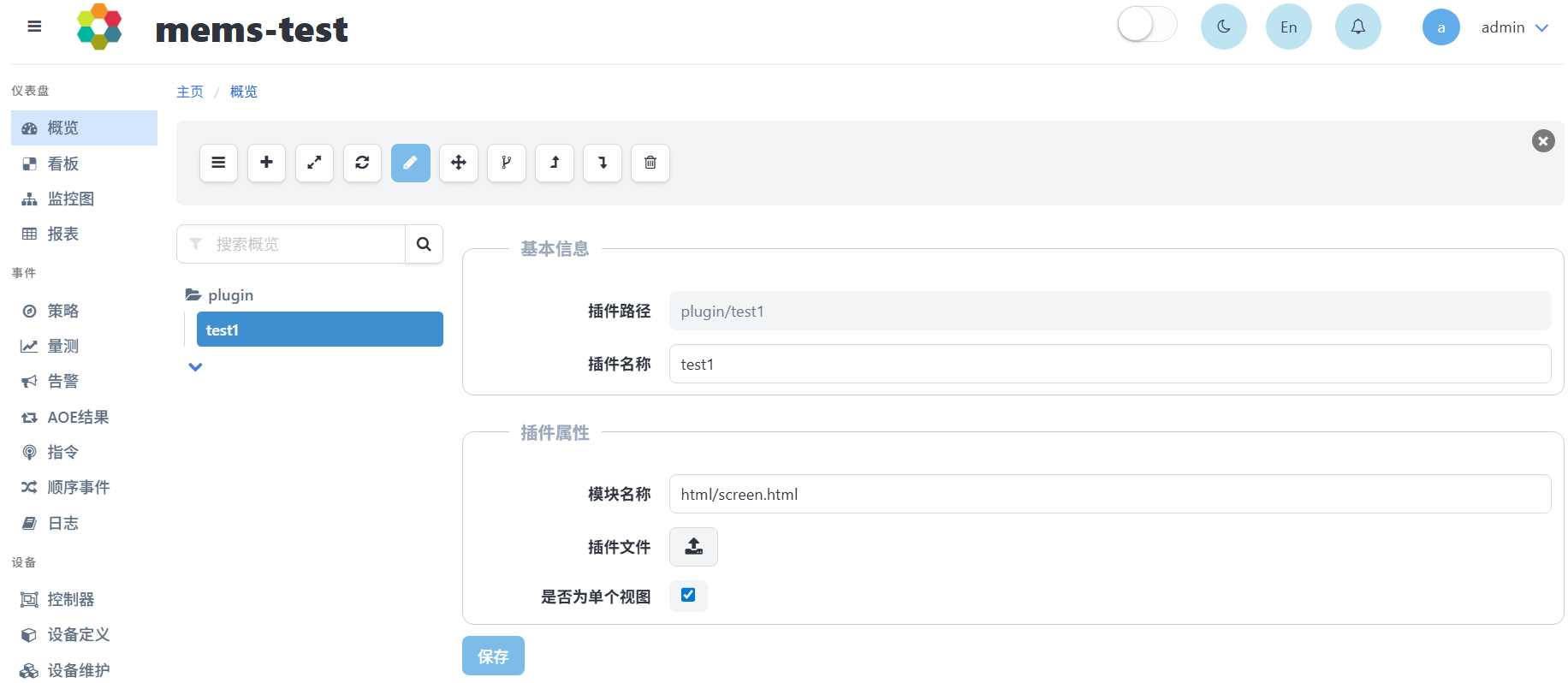
在基本信息中填写插件名称,在插件属性上传7z压缩包形式的插件文件(插件文件示例),模块名称填写压缩包中具体文件路径,选择是否为单个视图,配置完成后点击保存。
点击上方工具栏中编辑按钮可切换编辑模式和浏览模式。切换到浏览模式后,可查看插件界面显示结果,如下图所示。
5 应用范例
此章节用来给出基于MEMS的一些应用范例,以帮助用户尽快入门基于MEMS的开发工作。
持续更新中……
5.1 电力系统潮流计算
1、案例概况
本案例介绍利用mems实现matpower中的潮流计算,包括网络设备信息配置与查询、潮流计算。
matpower潮流计算功能包含以下主要函数:
- idx_gen: 生成
gen矩阵列索引 - idx_bus: 生成
bus矩阵列索引 - idx_brch:生成
branch矩阵列索引 - make_y_bus:生成节点导纳矩阵
- dsbus_dv:计算功率注入相对于电压的偏导数。
- make_sdzip:构建ZIP负载的复功率向量
- make_sbus:构建母线注入复功率向量
- newtonpf:牛顿法求解潮流
- runpf:执行潮流计算
上述函数均已通过RustScript语言实现,并在github中上传,可在mems中直接调用,URL如下:
- idx_gen: https://shufengdong.github.io/sparrowzz/rspower/lib/idx_gen.txt
- idx_bus:https://shufengdong.github.io/sparrowzz/rspower/lib/idx_bus.txt
- idx_brch:https://shufengdong.github.io/sparrowzz/rspower/lib/idx_brch.txt
- make_y_bus:https://shufengdong.github.io/sparrowzz/rspower/lib/make_y_bus.txt
- dsbus_dv:https://shufengdong.github.io/sparrowzz/rspower/lib/dsbus_dv.txt
- make_sdzip:https://shufengdong.github.io/sparrowzz/rspower/lib/make_sdzip.txt
- make_sbus:https://shufengdong.github.io/sparrowzz/rspower/lib/make_sbus.txt
- newtonpf:https://shufengdong.github.io/sparrowzz/rspower/lib/newtonpf.txt
- runpf:https://shufengdong.github.io/sparrowzz/rspower/lib/runpf.txt
潮流计算输入数据主要包含母线、支路、发电机对应的bus、branch、gen3个矩阵。
2、设备配置
在mems界面设备中配置bus、branch、gen3个矩阵对应信息,包括设备属性定义、设备定义和设备实例构建。
(1)设备属性定义
将bus、branch、gen矩阵的列属性定义为设备属性。在设备-设备定义-属性仓库页面导入设备属性定义文件,文件内容如下图所示:
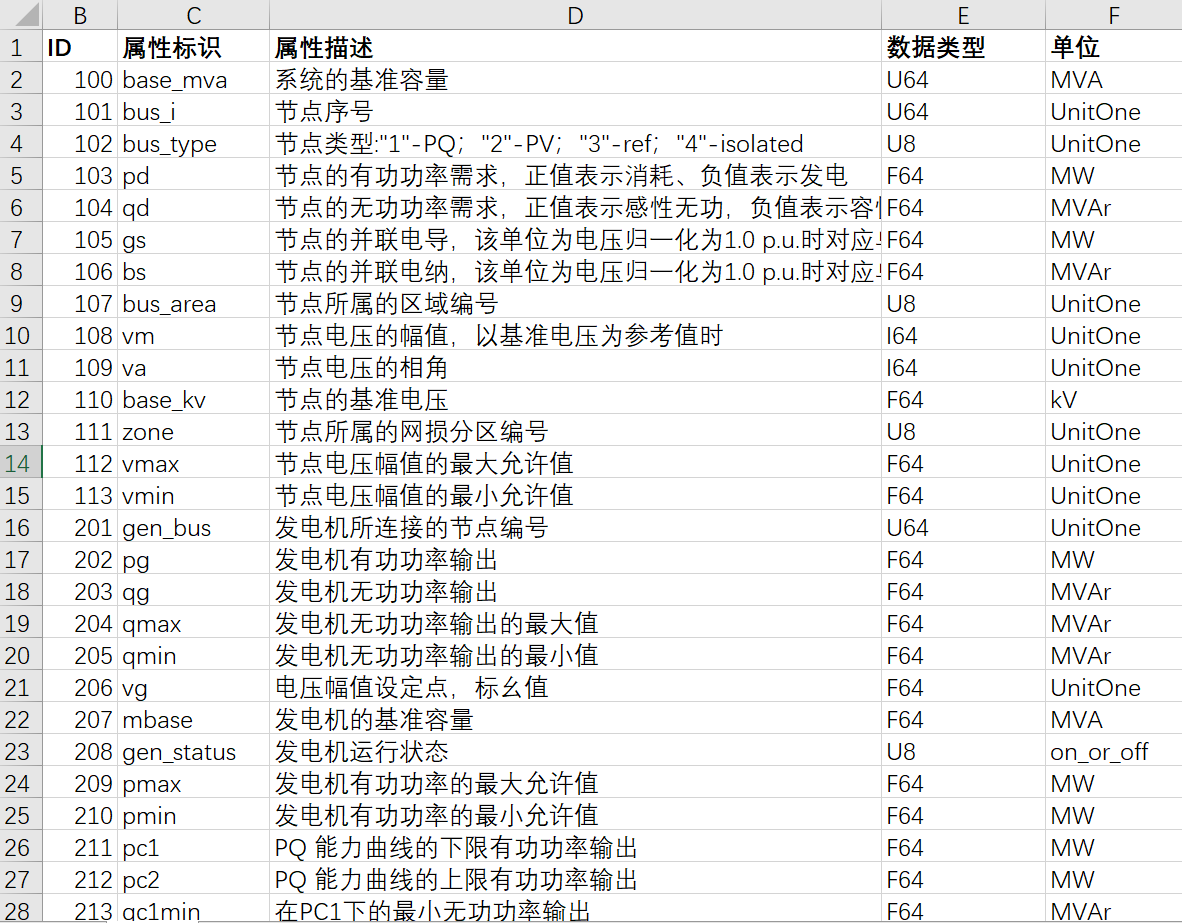
(2)设备定义
在设备-设备定义页面导入设备定义文件,文件内容如下图所示:
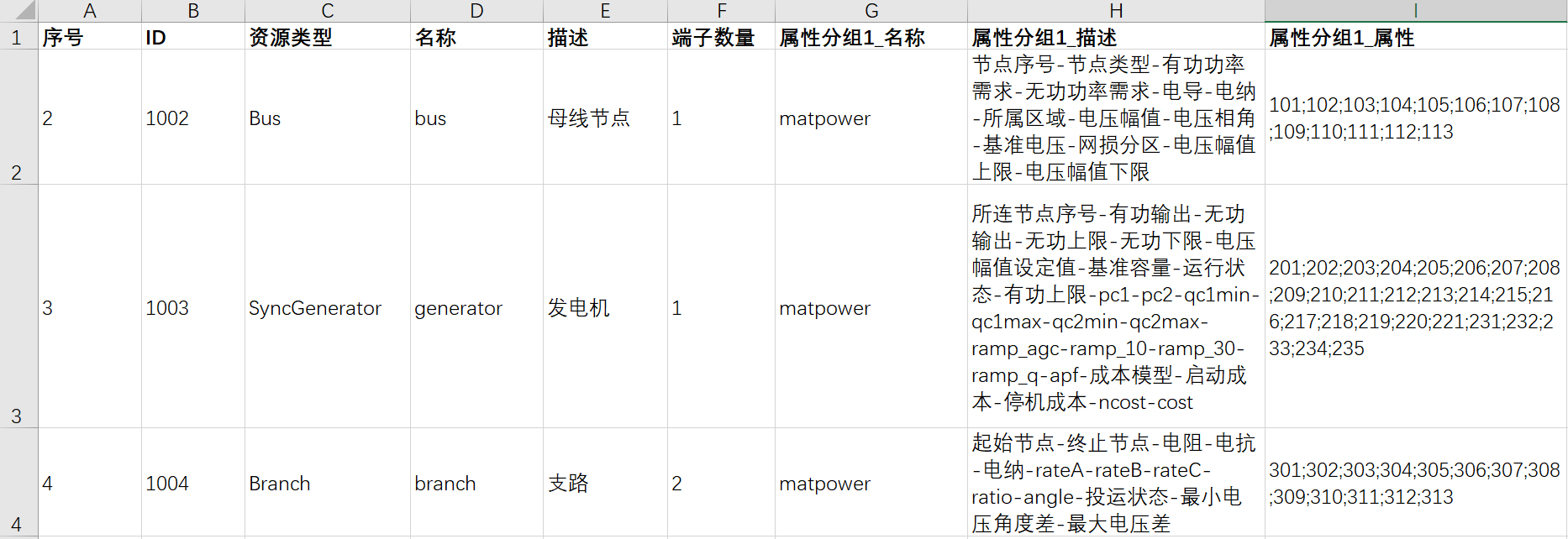
(3)设备实例构建
在设备-设备维护页面导入设备实例文件,文件内容如下图所示:
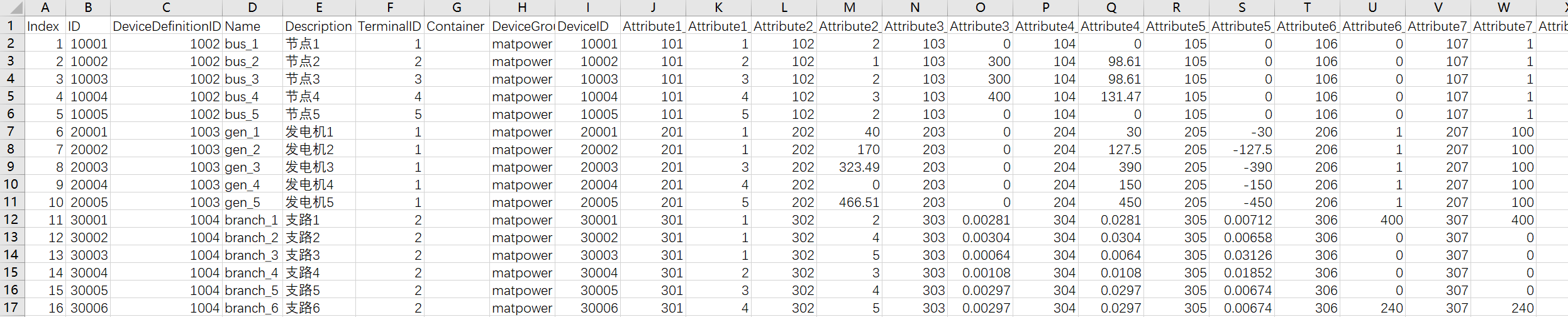
3、测点配置
matpower中的系统基准容量baseMVA作为测点数据进行配置,后续计算从测点中获取。在设置项-测点中导入对应测点,设置其默认值为系统基准容量,如下图所示:

4、潮流计算配置
在设置项-报表配置实现潮流计算的DataFrame流,包括获取网络设备信息、潮流计算,以下说明具体配置步骤。
(1)获取设备信息
在报表配置文件中,从设备表中获取各类设备参数,对应matpower的bus、branch、gen输入参数,配置如下图所示:

以节点1获取母线信息为例,该节点类型为SOURCE_DEV,表示获取设备表信息,参数为如下sql语句:
select
`101`,`102`,`103`,`104`,`105`,`106`,`107`,`108`,`109`,`110`,`111`,`112`,`113`
from Bus
order by `101`
其中,Bus为母线表,列名为母线属性id。这里写出所有需要的列名,保证查询结果中属性顺序与matpower的bus矩阵属性顺序一致,同时按照母线编号进行行排序,以便与matpower比较计算结果。
(2)获取系统基准容量
系统基准容量信息通过测点获取,配置如下图所示。

该节点类型为SOURCE_POINT,表示获取测点表信息,配置参数为如下sql语句:
select value from points where id=500001
其中,points为测点表,id为测点id列名,value为测点值列名。
(3)输入数据传给潮流计算节点
通过边将上述数据传给潮流计算节点,配置如下图所示:

(4)进行潮流计算
在节点5中进行潮流计算,该节点类型为TensorEval,参数2为3,表示进行复数张量运算,参数1配置及说明如下:
baseMVA=get(baseMVA_mat,0,0); //获取系统基准容量标量值
//通过URL导入潮流计算所需函数
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/idx_gen.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/idx_bus.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/idx_brch.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/make_y_bus.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/dsbus_dv.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/make_sdzip.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/make_sbus.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/newtonpf.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/runpf.txt
r = runpf(); //执行潮流计算
return r; //返回计算结果
上述配置中,由于从边获取的数据baseMVA_mat为张量,通过get函数取出其中元素获取标量值。通过#include_url关键字从URL引入需用到的外部RustScript程序,使配置文件中的程序结构更清晰。
5. 潮流计算结果查看
运行潮流计算的DataFrame流,在仪表盘-报表页面可查询计算结果,选择表格展示形式,如下图所示:
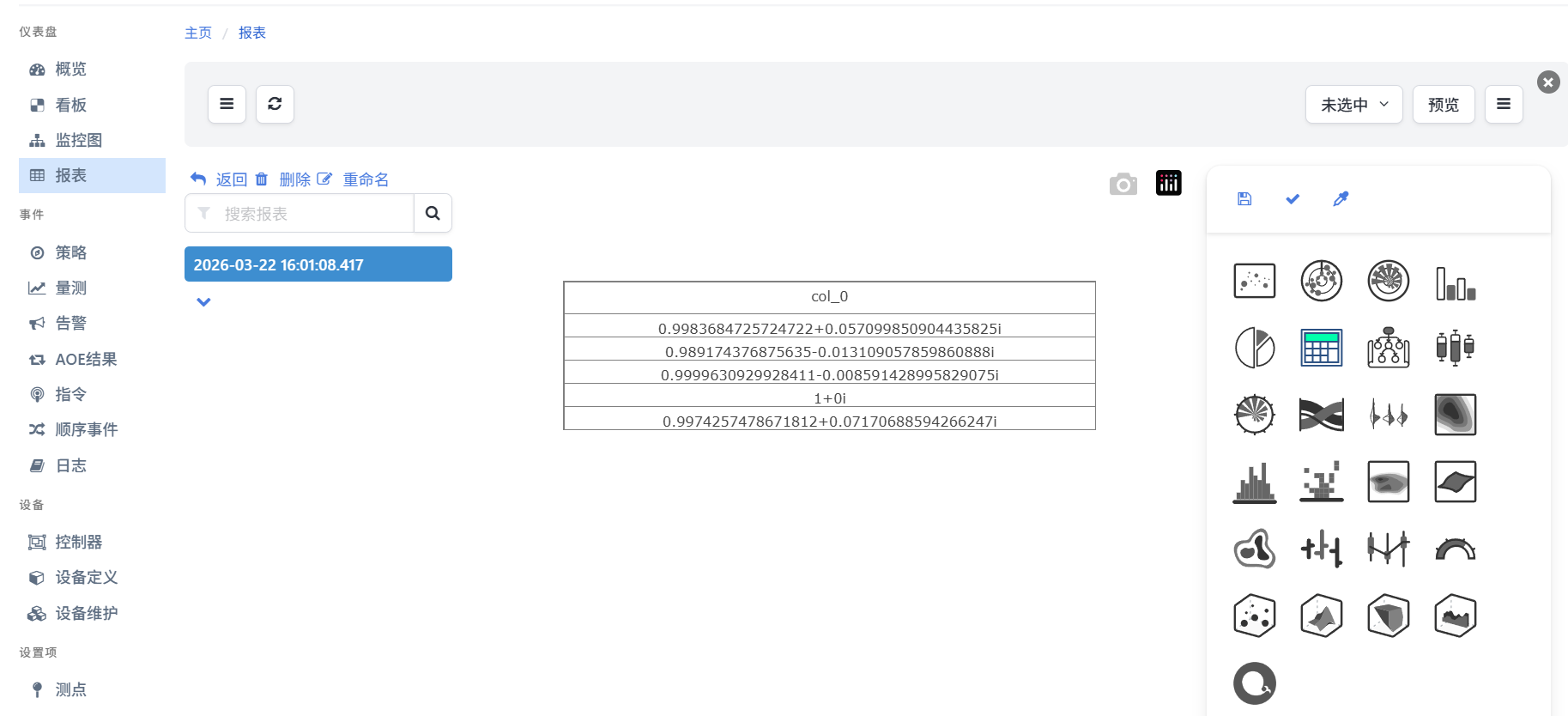
其中复数的实部为节点电压幅值、虚部为电压相角。
以下附件中提供了上述潮流计算DataFrame流的配置文件,以及matpower 5节点系统案例对应的的设备、测点配置文件,可参考使用。
5.2 电力系统状态估计
1、案例概况
本案例介绍利用mems实现matpower中的状态估计计算,包括从scada数据源获取量测数据、网络设备信息查询、状态估计计算、计算结果写入状态估计se数据源。
matpower状态估计功能包含以下主要函数:
- run_se: 运行状态估计
- doSE: 求解状态估计问题
- checkDataIntegrity:校验输入数据完整性
- isobservable:校验系统是否可观测
上述函数均已通过RustScript语言实现,并在github中上传,可在mems中直接调用,URL如下:
- run_se: https://shufengdong.github.io/sparrowzz/rspower/lib/runse.txt
- doSE: https://shufengdong.github.io/sparrowzz/rspower/lib/doSE.txt
- checkDataIntegrity:https://shufengdong.github.io/sparrowzz/rspower/lib/checkDataIntegrity.txt
- isobservable:https://shufengdong.github.io/sparrowzz/rspower/lib/isobservable.txt
状态估计计算输入数据中,除潮流计算的输入数据以外,还包括以下8类量测数据:
- PF:支路首端有功功率量测(由首端流向尾端)
- QF:支路首端无功功率量测(由首端流向尾端)
- PT:支路尾端有功功率量测(由首端流向尾端)
- QT:支路尾端无功功率量测(由首端流向尾端)
- Vm:母线电压幅值量测
- Va:母线电压相角量测
- PG:发电机有功出力量测
- QG:发电机无功出力量测
这8类量测可分别设置其测量误差。
在输入数据中通过位置索引变量确定量测与设备的对应关系,例如idx.idx_zPF = [1;2]、measure.PF = [0.12;0.10]中,idx_zPF指定了PF向量中的2个量测分别为branch矩阵中第1条和第2条支路的量测。
2、量测配置
状态估计案例中,bus、branch、gen设备信息的导入与潮流计算类似,除此之外,还需要配置量测信息。由第1节可知,每条支路包含PF、QF、PG、QG四个量测,每个母线包含Vm、Va两个量测,每台发电机包含PG、QG两个量测。对于每个量测,在mems界面设置项-测点中导入对应的测点。其中,测点单位需正确配置,后续需通过单位区分同一元件的不同量测物理量。对于存在量测值的测点,设置其默认值为量测值,对于不存在量测值的测点,设置其默认值为NaN。
此外,系统基准容量和8类量测的误差参数也作为测点数据进行配置,后续计算从测点中获取。
然后,在设备-设备维护-测点导入设备的量测信息,建立设备与测点的关联关系。量测信息配置文件如下图所示:
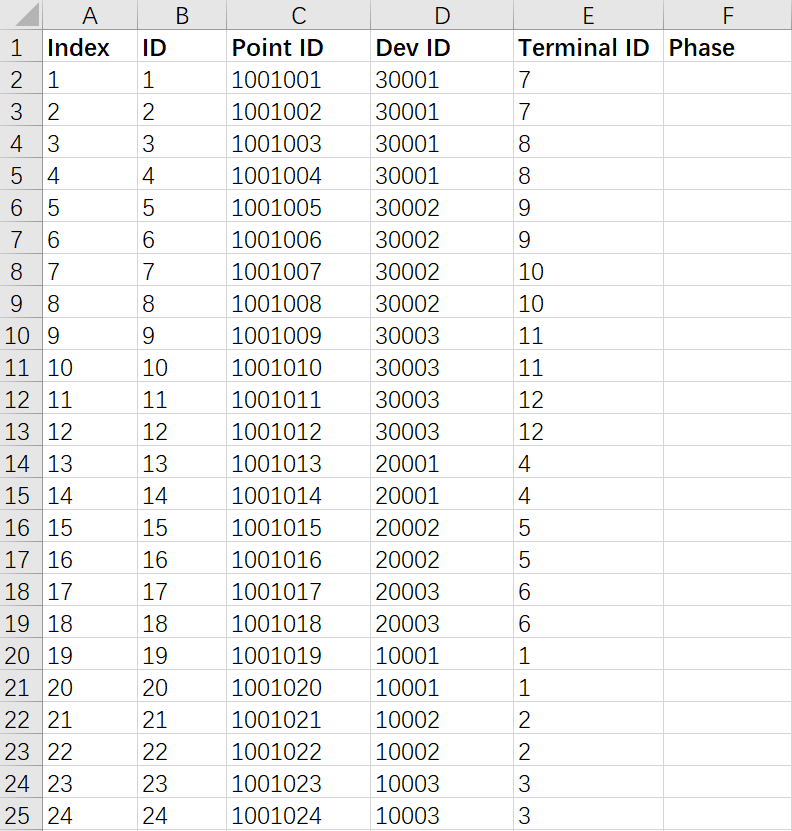
其中,ID列为量测id,Point ID列为对应测点点号,Dev ID为对应设备ID,Terminal ID为对应端子ID,Phase为量测相别。注意导入量测后需要提交并应用版本。
3、状态估计计算配置
在设置项-报表配置实现状态估计计算的DataFrame流,包括获取量测数据、获取网络设备信息、执行状态估计计算、输出结果等,以下说明具体配置步骤。
(1)获取测点id和单位信息
报表配置文件中,在节点1中获取测点id和单位信息,如下图所示。

节点1类型为SOURCE_POINT,表示获取测点表信息,配置参数为如下sql语句:
select id,data_unit from points order by id
其中,points为测点表,id为测点id列名,data_unit为测点单位列名。
(2)获取scada数据源实时量测信息
在节点2中获取scada数据源实时量测信息,如下图所示。

节点2类型为SOURCE_MEAS,表示获取量测表信息。参数1为0,表示获取数据源为0(即scada数据源)的量测数据,参数2为如下sql语句:
select id,value from meas order by id id
其中,meas为量测表,id为量测对应测点id列名,value为量测值列名。
(3)获取母线量测信息
通过节点3、4、5、6和边1;4、2;4、3;4、4;5、4;6获取母线电压幅值和电压相角量测,如下图所示。


节点3类型为SOURCE_DEV,表示获取设备表信息,参数为如下sql语句:
select t2.dev,t2.terminal,t3.point from Bus t1
left join topo t2 on t1.id=t2.dev
left join measdef t3 on t2.terminal = t3.terminal
order by t1.id
其中,Bus为母线表;topo为拓扑信息表,包含设备id及其对应端子id信息;measdef为量测定义表,包含测点点号及其对应端子id对应关系。
节点4类型为TensorEval,参数2为4,表示进行DataFrame操作。在该节点中对查询到的测点信息、量测值、设备信息进行组合操作,参数1配置如下:
bus_points_unit = join(bus_points, points, `point`, `id`, inner);
bus_meas_all = join(bus_points_unit, meas, `point`, `id`, inner);
在该节点中先对设备表信息与测点表信息按设备表的顺序进行拼接,再与量测表信息进行拼接,均按照测点id字段进行拼接。
边4;5和4;6按照量测单位对母线2个物理量进行区分,分别将电压幅值量测和电压相角量测信息传给节点5和节点6。以边4;5为例,其动作类型为Eval,动作参数如下:
filter(col(dev), col(terminal), col(point), col(value), col(data_unit)==`UnitOne`);
其中,filter函数用于对DataFrame进行过滤筛选,最后一个参数为过滤条件表达式,UnitOne为电压幅值标幺值单位,之前的参数为保留的列。
(4)获取支路首端量测信息
通过节点7、8、9、10和边1;8、2;8、7;8、8;9、8;10获取支路首端有功和无功潮流量测,如下图所示。


获取支路测点信息整体过程与(3)中母线操作相同,不同之处是还需要区分支路首端和尾端量测,为此在节点7配置参数如下:
SELECT
t2.dev,
t2.terminal,
t3.point
FROM Branch t1
LEFT JOIN (
SELECT
dev,
terminal
FROM (
SELECT
dev,
terminal,
ROW_NUMBER() OVER (PARTITION BY dev ORDER BY terminal) AS rn
FROM topo
) tmp
WHERE rn = 1
) t2 ON t1.id = t2.dev
LEFT JOIN measdef t3 ON t2.terminal = t3.terminal
ORDER BY t1.id
其中,Branch为支路表。该案例中根据端子id大小区分支路首端和尾端,端子id小的表示首端,端子id大的表示尾端。通过子查询t2获取每个支路较小的端子id,从而获取支路首端测点信息,具体逻辑为:
- 从topo表中,按dev即设备id分组
- 每组内按terminal排序,用ROW_NUMBER()生成编号
- 取每组第1行(rn=1),即每个设备对应的最小端子id值
- 然后与Branch表通过t1.id=t2.dev左连接。
(5)获取支路尾端量测信息
通过节点11、12、13、14和边1;12、2;12、11;12、12;13、12;14获取支路首端有功和无功潮流量测,过程与获取支路首端量测信息类似,如下图所示。


(6)获取发电机量测信息
通过节点15、16、17、18和边1;16、2;16、15;16、16;17、16;18获取发电机有功和无功出力量测,如下图所示。


(7)获取量测误差信息
从测点表中获取各类量测误差信息,如下图所示:

(8)获取设备参数和系统基准容量
从设备表中获取各类设备参数,对应matpower的bus、branch、gen、baseMVA输入参数,如下图所示:

(9)输入数据传给状态估计计算节点
通过边将上述数据传给状态估计计算节点,配置如下图所示:
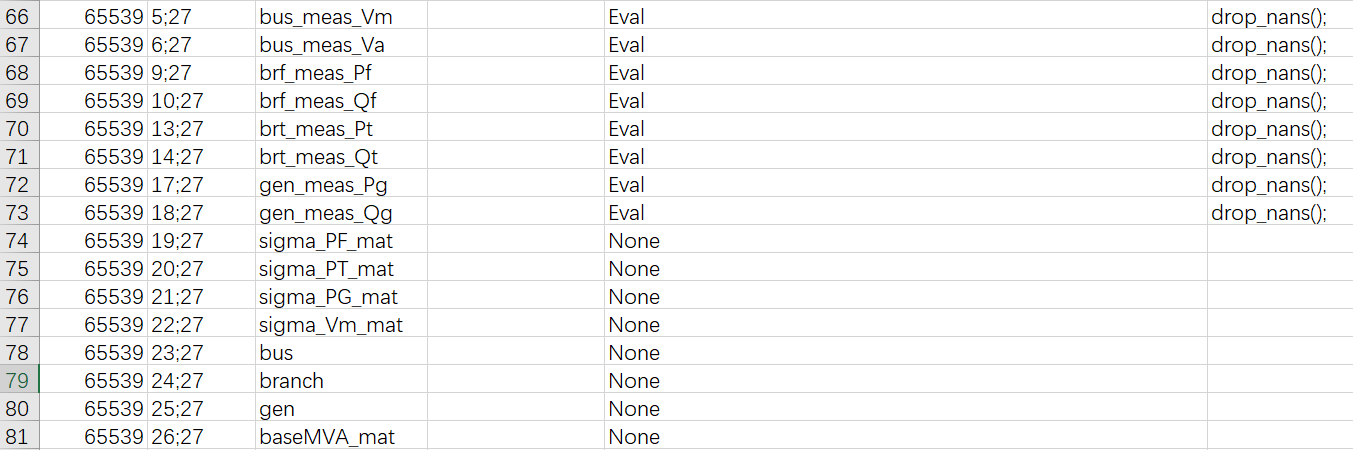
其中对于量测需要滤除NaN值,以边5;27过滤节点电压幅值中的NaN值为例,边类型为Eval,配置参数如下
drop_nans();
该函数用于删除DataFrame中包含NaN值的行。
(10)进行状态估计计算
在节点27中进行状态估计计算,该节点类型为TensorEval,参数2为3,表示进行复数张量运算,参数1配置及说明如下:
idx_zVm = select(bus_meas_Vm, [], 0)-10000; //母线电压幅值量测对应设备位置索引
measure_Vm = select(bus_meas_Vm, [], 3); //母线电压幅值量测值
idx_zVa = select(bus_meas_Va, [], 0)-10000; //母线电压相角量测对应设备位置索引
measure_Va = select(bus_meas_Va, [], 3); //母线电压相角量测值
idx_zPF = select(brf_meas_Pf, [], 0)-30000; //支路首端有功量测对应设备位置索引
measure_PF = select(brf_meas_Pf, [], 3); //支路首端有功量测值
idx_zQF = select(brf_meas_Qf, [], 0)-30000; //支路首端无功量测对应设备位置索引
measure_QF = select(brf_meas_Qf, [], 3); //支路首端无功量测值
idx_zPT = select(brt_meas_Pt, [], 0)-30000; //支路尾端有功量测对应设备位置索引
measure_PT = select(brt_meas_Pt, [], 3); //支路尾端有功量测值
idx_zQT = select(brt_meas_Qt, [], 0)-30000; //支路尾端无功量测对应设备位置索引
measure_QT = select(brt_meas_Qt, [], 3); //支路尾端无功量测值
idx_zPG = select(gen_meas_Pg, [], 0)-20000; //发电机有功出力量测对应设备位置索引
measure_PG = select(gen_meas_Pg, [], 3); //发电机有功出力量测值
idx_zQG = select(gen_meas_Qg, [], 0)-20000; //发电机无功出力量测对应设备位置索引
measure_QG = select(gen_meas_Qg, [], 3); //发电机无功出力量测值
sigma_PF=get(sigma_PF_mat,0,0); //支路首端有功潮流量测误差
sigma_PT=get(sigma_PT_mat,0,0); //支路尾端有功潮流量测误差
sigma_PG=get(sigma_PG_mat,0,0); //发电机有功出力量测误差
sigma_Vm=get(sigma_Vm_mat,0,0); //母线电压幅值量测误差
sigma_Va = []; //母线电压相角量测误差
sigma_QF = []; //支路首端无功潮流量测误差
sigma_QT = []; //支路尾端无功潮流量测误差
sigma_QG = []; //发电机无功出力量测误差
baseMVA=get(baseMVA_mat,0,0); //基准容量
areas = [1,1]; //所属区域
//通过URL导入状态估计计算所需函数
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/idx_gen.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/idx_bus.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/idx_brch.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/ext2int.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/int2ext.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/bustypes.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/make_y_bus.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/getV0.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/runse.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/dSbr_dV.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/dsbus_dv.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/doSE.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/isobservable.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/make_sdzip.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/make_sbus.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/pfsoln.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/total_load.txt
#include_url https://shufengdong.github.io/sparrowzz/rspower/lib/checkDataIntegrity.txt
type_initialguess = 2; //平启动计算
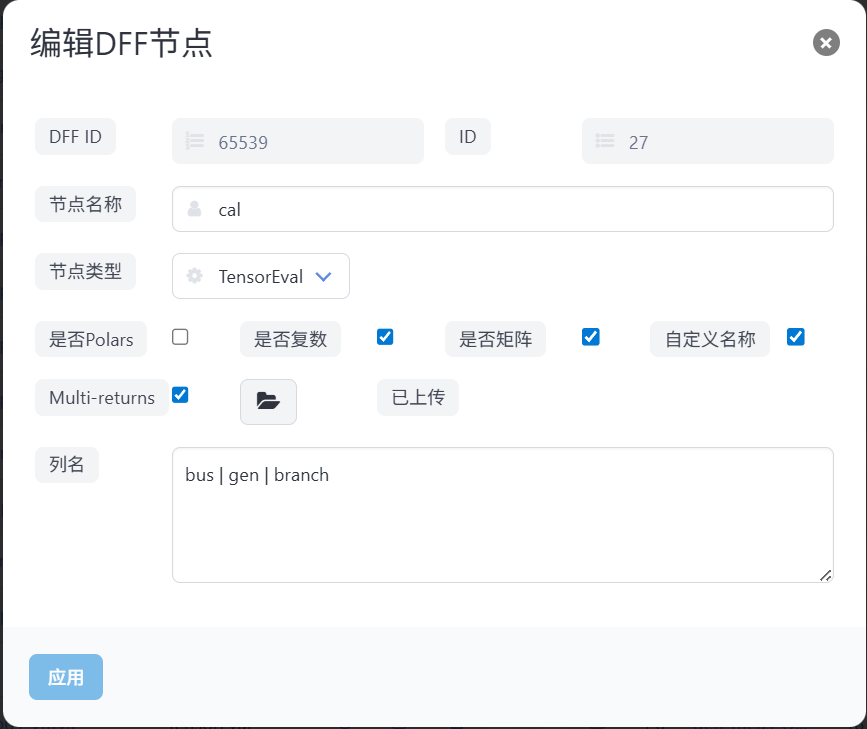
[baseMVA, bus, gen, branch, success, z, z_est, error_sqrsum] = run_se(type_initialguess, []); //执行状态估计计算
return (bus, gen, branch); //返回计算结果
该案例中通过设备id减去其编号基数获取设备位置索引。由于该节点计算结果包含多个返回参数,需要分别传给后续的边,还需要在界面对该节点填写列名为返回参数,并勾选自定义名称和Multi-returns,如下图所示:
(11)获取状态估计计算结果
通过边获取状态估计计算结果的bus、gen、branch返回参数,其中动作名称需与返回参数变量名称一致,如下图所示:

(12)状态估计结果写入测点的状态估计数据源
计算完成后,将状态估计写入测点的状态估计se数据源。以将电压幅值计算结果写入se数据源的节点和边配置如下图所示:


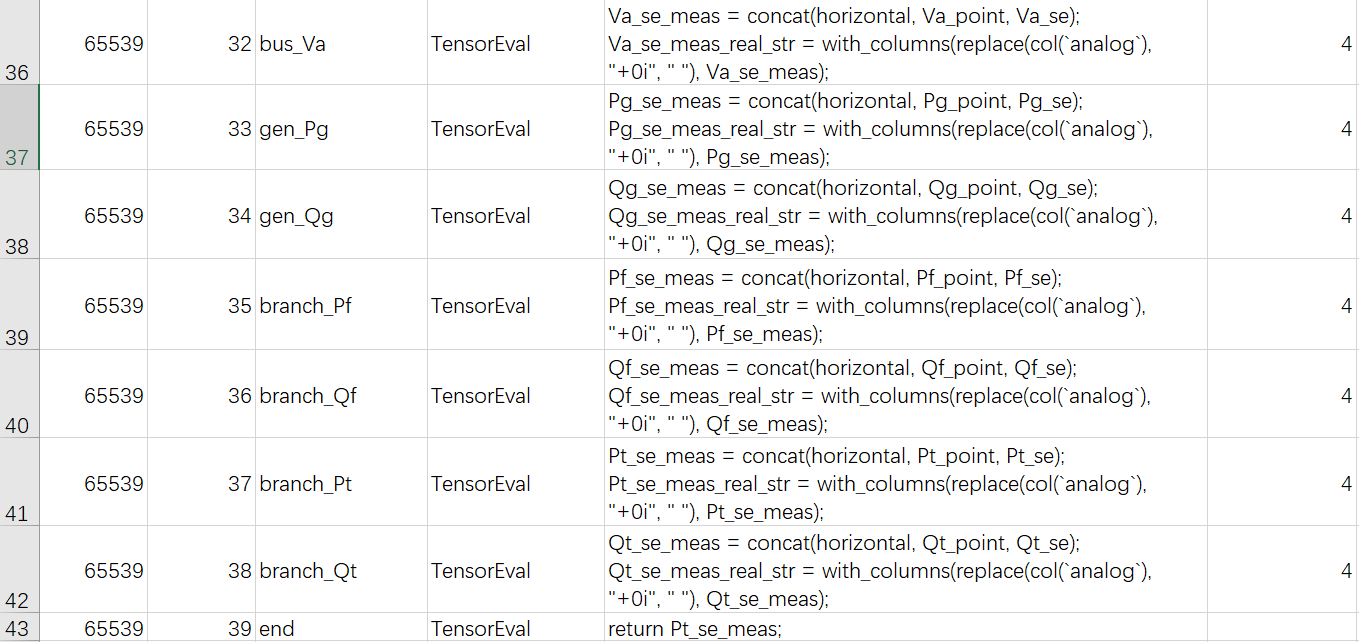
其中WriteFile类型的边用于将DataFrame数据写入量测数据源,DataFrame需包含point和analog/discrete2列,动作逻辑为:如果参数为meas://1, 表示用DataFrame更新数据源id为1的量测值,DataFrame包含point的列表示测点号,如果有discrete的列表示更新离散量,如果有analog的列表示更新模拟量,注意discrete或analog列不能同时出现。
上图在边5;31中选取point列,在边28;31选取计算结果列并将列名重命名为analog。在节点31中将从边获取的2个DataFrame拼接为1个DataFrame,此外,由于写入测点的值需为实数,通过字符串替换replace函数将计算值中的+0i虚数部分替换为空格,保留实部。
将状态估计其他结果写入se数据源的配置方法类似,如下图所示。

4. 状态估计结果查看
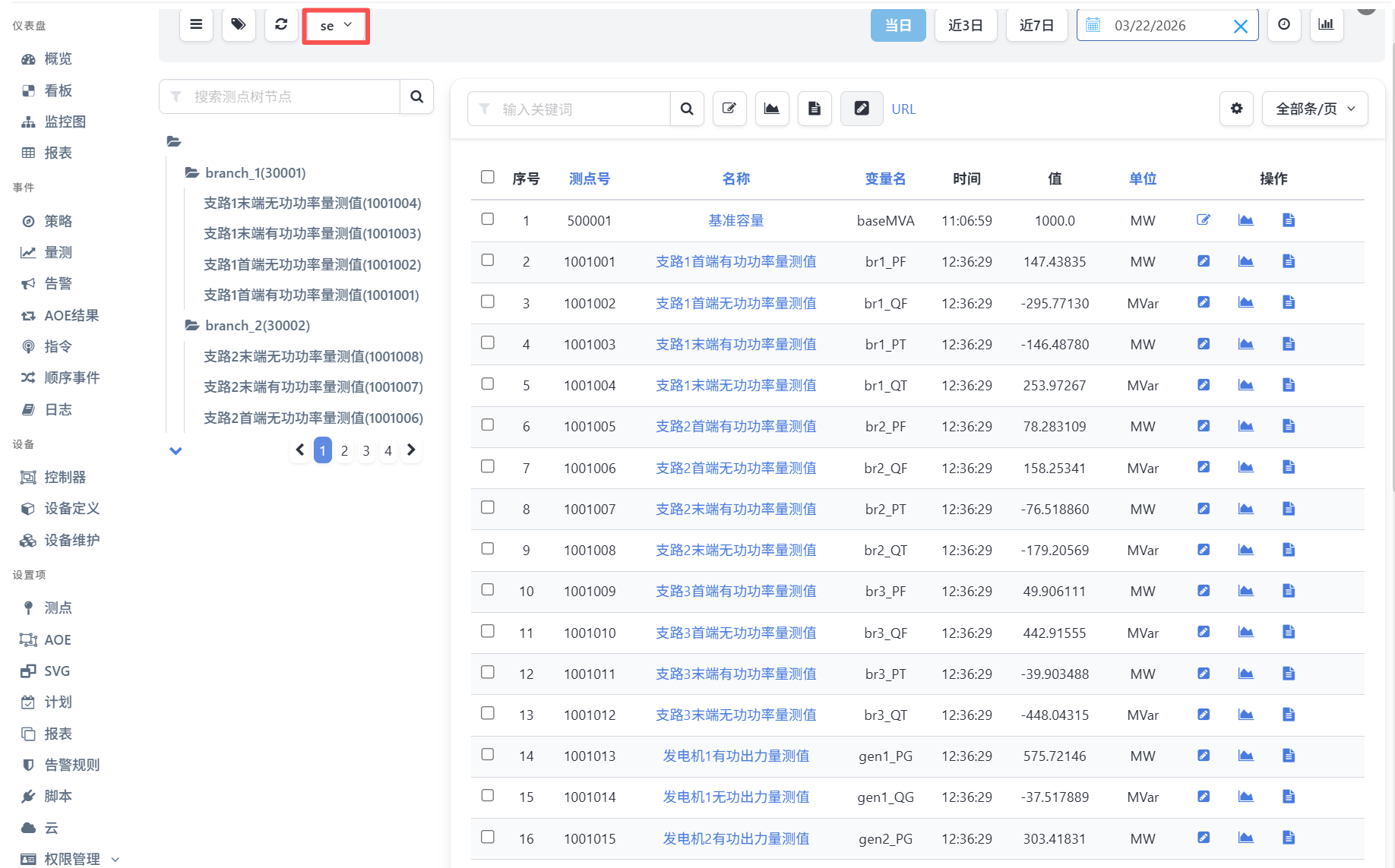
运行状态估计的DataFrame流,在事件-量测页面选择se数据源,可看到测点中写入的计算结果,如下图所示:
以下附件中提供了上述状态估计DataFrame流的配置文件,以及matpower状态估计3节点系统案例对应的的测点、设备、量测配置文件,可参考使用。
最优潮流
5.1 一致性算法
1、案例概况
本案例介绍在多个mems之间实现一致性算法,分布式计算平均值,包括mems通信配置、一致性算法配置、不同mems的DataFrame流数据交互配置。
分布式计算平均值指网络中每个节点仅与邻居通信,通过迭代使所有节点的状态值收敛到初始值的平均值。一致性算法的节点更新规则为每个节点将其值更新为自身与邻居值的加权平均,例如:
x_i(t+1) = x_i(t) + ε Σ(x_j(t) - x_i(t))
其中x_i(t)为节点i在第t次更新后的值,ε为步长。
当通信图是连通图,且步长选择合适时,所有x_i会渐近收敛到初始值的算术平均。这是异步、去中心化的计算,但通常需要多轮迭代才能达到足够精度。
2、mems通信配置
为建立2个mems之间的通信,需要在其中1个mems中配置另一个mems的监听接口。假设2个mems的beeId分别为node1和node2,后续描述使用node1和node2指代2个mems。在node1界面设置项-云-云端2 请求响应URL中配置node2的北向接口,如下图所示:
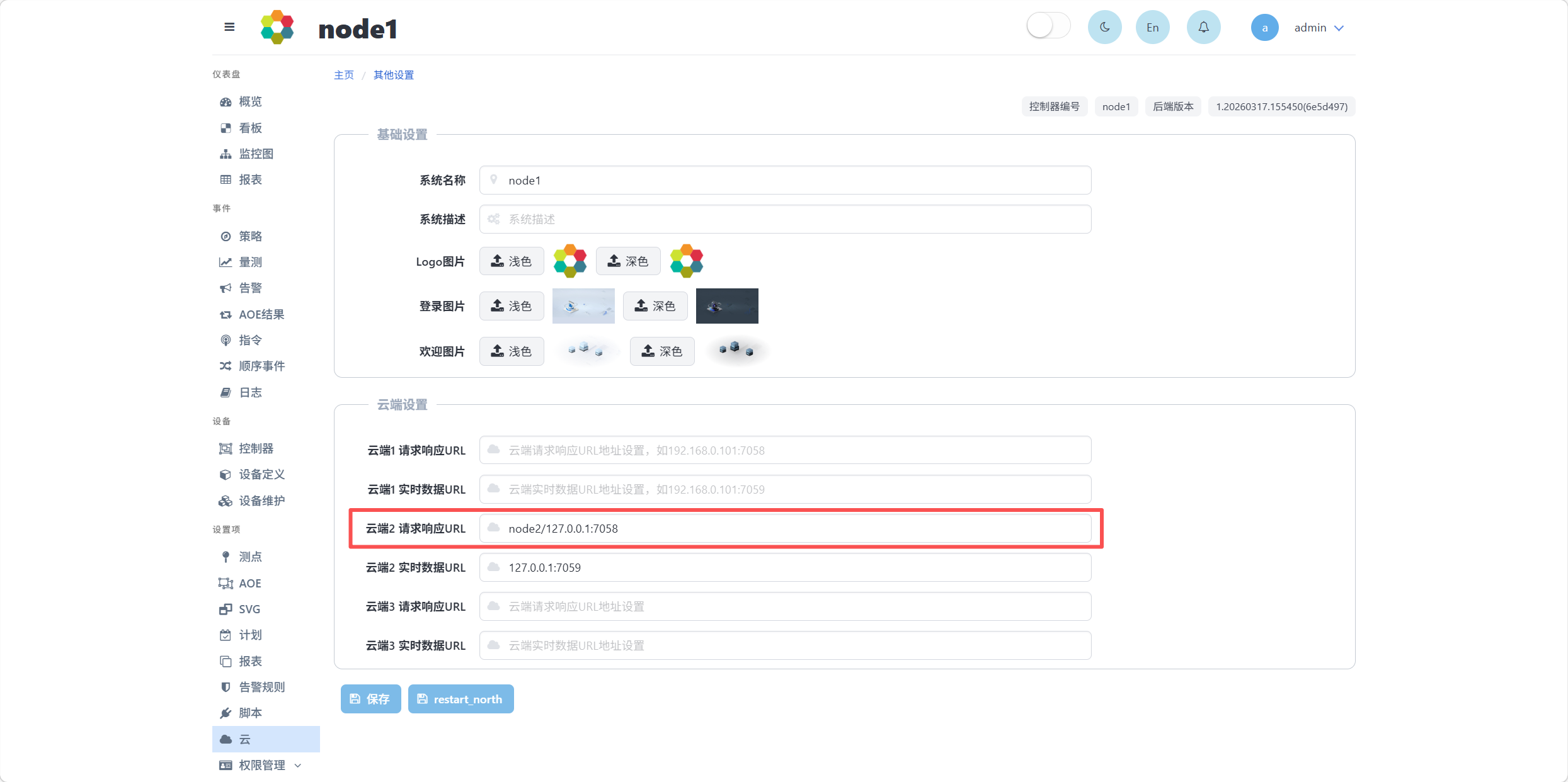
其中,node2为另一个mems的beeId,127.0.0.1:7058为北向接口的IP和端口。
3、一致性算法配置
(1)接收其他mems的DataFrame数据配置
在一致性算法中,每个节点在收到所有相邻节点的数据后需要进行更新计算,因此DataFrame流计算需由其他mems的数据驱动,接收其他mems数据的配置如下图所示:

该DataFrame流的触发条件为DataSource,表示数据源驱动。节点1类型为SOURCE_OTHER,参数为0,表示接收其他mems的数据。这里注意如果是接收自身其他DataFrame流的数据则参数设为其他DataFrame流的id。
若mems有多个相邻节点,则触发条件参数需要填写该DataFrame流中接收其他mems数据的所有节点编号,并用;分割,例如:本mems中节点1和节点2接收其他mems的数据,则该DataFrame流的触发条件参数填写1;2。
(2)获取本地当前值
本案例将一致性算法需要更新的值存储在测点中,因此在每次更新时需要从测点获取本地当前值,如下图所示:

(3)计算更新量和新值
根据本地值和从其他mems收到的值计算更新量和新值,节点和边配置如下图所示:


上图中将ε设为了0.05。
(4)将新值写入本地测点
将更新后的新值写入本地测点,节点和边配置如下图所示:


(5)判断计算是否收敛
基于更新量判断计算是否收敛,若未收敛则将邻居发送本节点的新值,若收敛则停止向邻居发送数据,对应节点和边配置如下图所示。


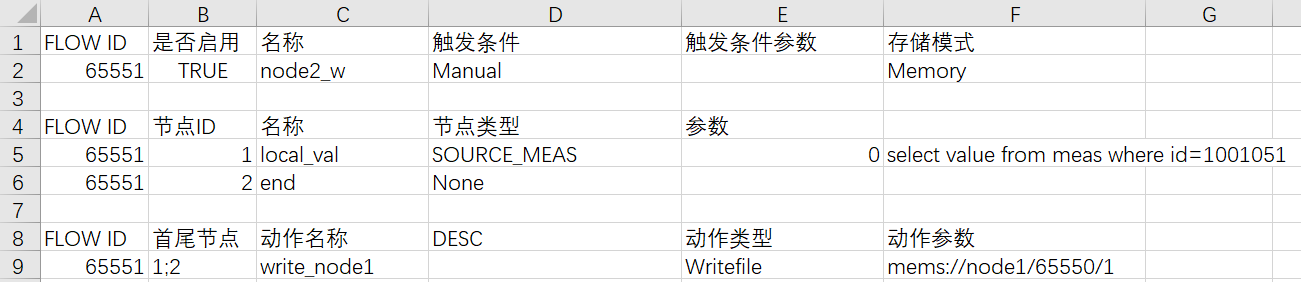
通过Writefile类型的边实现向其他mems发送DataFrame,参数写法中mems://表示是写到其他mems,后面分别是其他mems的beeid、DataFrame流id和节点id。只有在边接收到非空的DataFrame,才会向其他mems发送数据。上图中node1的对应DataFrame流id为65550,数据源节点id为1。
上图中,在节点6判断若最大更新值小于阈值0.001,则计算收敛,否则计算未收敛。当计算收敛时,节点返回一个空的DataFrame给到边6;7,控制一致性算法停止迭代。
(6)一致性算法计算触发
通过上述配置,在计算开始后,不同mems的数据源驱动的DataFrame流可相互触发,但首次计算需要外部条件触发。可通过配置手动触发的DataFrame流向其中部分mems写入数据,触发首次计算,如下图所示。
4. 一致性算法计算结果查看
运行各mems的一致性算法DataFrame流,在事件-量测页面可查看测点值的迭代变化过程及最终结果。
以下附件中提供了一个3节点的一致性算法DataFrame流的配置文件案例,可参考使用。
附件:一致性算法案例.zip
5.5 台区电表运行误差估计
1、案例概况
本案例介绍利用mems实现台区电表运行误差估计算法,包括电表数据获取、误差估计、结果输出。
低压台区电能表运行误差可以根据运行大数据进行估计。根据低压台区树形拓扑结构,以台区所有电能表组成集群,由能量守恒关系可以得到:
台区总表供电量=所有分表用电量之和+台区可变损耗+台区固定损耗
台区可变损耗近似与台区总用电量成正比,同时台区总表精度等级远高于用户表,可合理假设台区总表计量足够准确,计量误差为0,则上述关系可用公式表示如下:
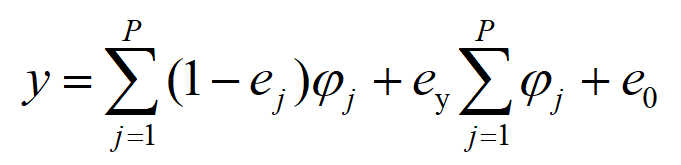
式中:y为台区总表供电量;P为台区用户表数量;φj为第j个用户表的用电量;ej为第j个用户表的运行误差;ey为台区可变损耗与用电量的比例系数;e0为台区固定损耗。
将上式中运行误差变量和常量分离可得:
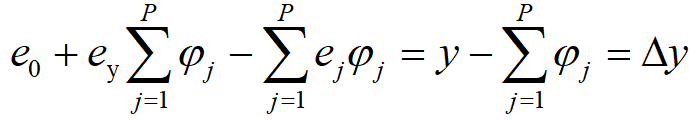
令:
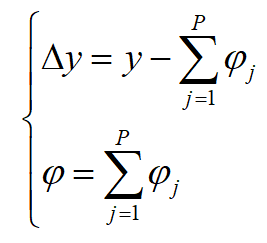
代入上式,并将上式两侧均除以y进行归一化可得:
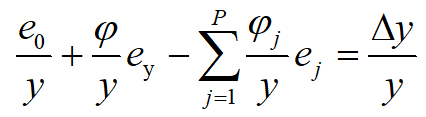
通过采集P+2个数量以上时段的台区电表有效运行数据,可对上式进行求解,对电能表运行误差进行估计。将多个时段得到的式子写成矩阵形式如下:
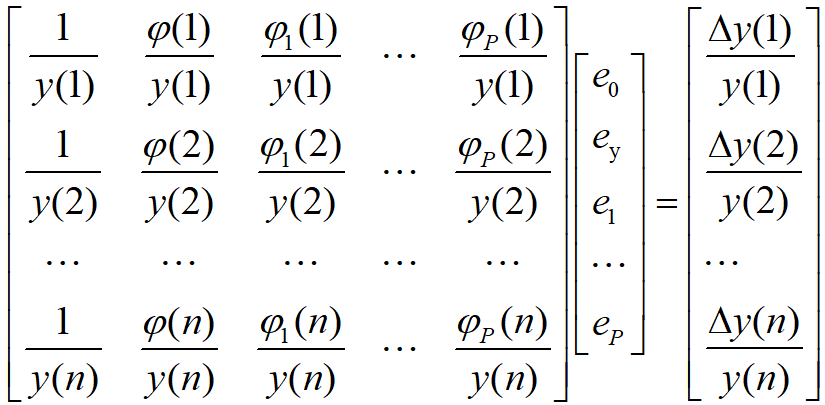
式中:(i)表示时段i的数据。
2、DataFrame流配置方法
规定电表运行数据输入文件格式为:

台区电能表运行误差估计的DataFrame流配置文件如下所示:
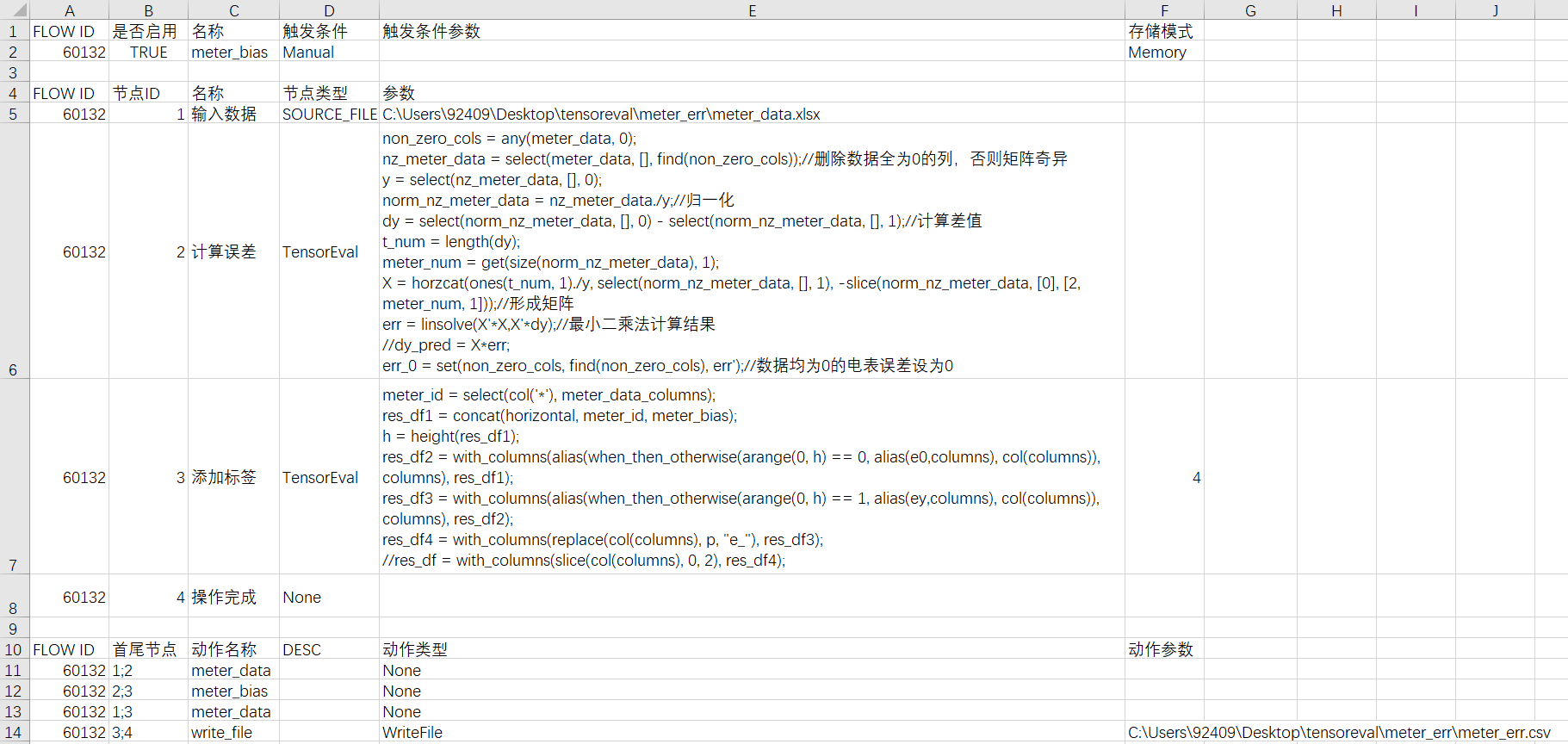
在DFF中配置了4个节点和4条边,其中节点1类型为SOURCE_FILE,作用是从文件中读取电能表数据,形成一个DataFrame,边1;2和1;3分别将该DataFrame传到节点2和节点3。
在节点2中进行电能表运行误差估计计算,该节点类型为TensorEval。其中:
- non_zero_cols = any(meter_data, 0);作用为检测矩阵第0维(即各列)是否存在非零元素,返回值为一个向量,若列中存在非零元素对应元素为1,否则为0;
- nz_meter_data = select(meter_data, [], find(non_zero_cols));作用为获取存在非零元素的列,避免计算矩阵奇异,find(non_zero_cols)可获取存在非零元素的列编号,select函数可获取给定编号的各列数据;
- y = select(nz_meter_data, [], 0);作用为获取台区总表供电量数据;
- norm_nz_meter_data = nz_meter_data./y;作用为对数据进行归一化;
- dy = select(norm_nz_meter_data, [], 0) - select(norm_nz_meter_data, [], 1);作用为计算 ;
- t_num = length(dy);作用为获取时段数量;
- meter_num = get(size(norm_nz_meter_data), 1);作用为获取电表数量;
- X = horzcat(ones(t_num, 1)./y, select(norm_nz_meter_data, [], 1), -slice(norm_nz_meter_data, [0], [2, meter_num, 1]));作用为形成前文推导得到的矩阵,其中horzcat作用是对矩阵进行水平拼接;
- err = linsolve(X’*X,X’*dy);作用是利用最小二乘法计算误差估计结果;
- err_0 = set(non_zero_cols, find(non_zero_cols), err’);作用是将数据均为0的电表误差设为0。
- 在节点3中为计算结果添加标签,该节点类型为TensorEval,同时在第6列填入4,表示支持Polars操作。其中:
- meter_id = select(col(‘*’), meter_data_columns);作用为获取输入文件数据中的列标签(包含电表编号信息);
- res_df1 = concat(horizontal, meter_id, meter_bias);作用为将列标签与电表运行误差计算结果进行水平拼接;
- h = height(res_df1);作用为获取计算结果中的数值数量;
- res_df2 = with_columns(alias(when_then_otherwise(arange(0, h) == 0, alias(e0,columns), col(columns)), columns), res_df1);作用为将第1个标签替换为e0;
- res_df3 = with_columns(alias(when_then_otherwise(arange(0, h) == 1, alias(ey,columns), col(columns)), columns), res_df2);作用为将第2个标签替换为ey;
- res_df4 = with_columns(replace(col(columns), p, “e_”), res_df3);作用为将标签中的字符“p“替换为“e_“;
- 边3;4类型为WriteFile,作用为将结果输出到文件。
5. 电表误差估计结果查看
输入电表数据文件示例如下所示:
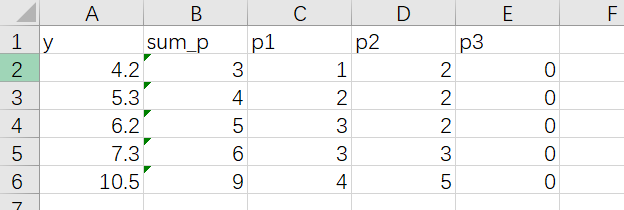
运行电表误差估计的DataFrame流,输出数据如下所示:
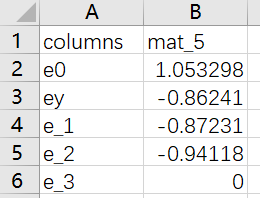
以下附件中提供了上述台区电表运行误差估计DataFrame流的配置文件及测试案例,可参考使用。
5.6 负荷预测
1、案例概况
本案例介绍利用MEMS实现负荷预测,包括从scada数据源获取负荷功率量测数据、Onnx神经网络计算、预测结果写入scada数据源。
负荷预测是基于历史用电数据与相关影响因素,对电力系统未来特定时段的负荷需求进行科学估计的技术。本案例中,MEMS首先通过数据源节点接入过去一天共96个采样点的历史负荷数据,然后在计算链路中调用已训练好的Onnx模型节点执行推理,最后输出未来一天96个点的负荷预测功率。
2、测点配置
负荷预测案例中,需要配置量测信息:历史数据测点(100001-100096)用于记录过去一天共96个采样点的,以及预测测点(200001-200096)用于保存计算后的未来一天96个点的负荷预测功率。
注:本案例中采用从量测值的方式获取历史负荷数据,若有其他需求可采用其他数据输入方式,如读表格等。
3、负荷预测配置
在设置项-报表配置实现负荷预测计算的DataFrame流,包括获取历史负荷功率数据、onnx计算、预测结果输出等,以下说明具体配置步骤。
(1)获取历史负荷功率数据
报表配置文件中,在节点1中获取历史负荷功率数据(即value量测值),如下所示:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数1 | 参数2 |
|---|---|---|---|---|---|
| 50001 | 1 | input_value | Source_Meas | select value from meas where id between 100001 and 100096 order by id asc |
节点1类型为Source_Meas,表示获取量测表信息。参数2中的sql语句含义:获取量测表中测点ID为100001至100096的测点的量测值,并按ID大小进行排序。
(2)onnx计算
1)数据预处理
获取历史负荷功率数据后,在边1(节点1→节点2)中对数据进行预处理,以匹配onnx文件的输入数据格式,如下所示:
| DFF ID | 首尾节点 | 边名称 | 描述 | 边类型 | 参数 |
|---|---|---|---|---|---|
| 50001 | 1;2 | 预处理 | Eval | Select(alias(cast(col(value),f32),value_1_1_96)); |
边1类型为Eval,表示将名为value的数据进行强制类型转换为f32类型,并改名为value_1_1_96。
2)Onnx计算
数据预处理后,在边2(节点2→节点3)中执行神经网络计算动作,如下所示:
| DFF ID | 首尾节点 | 边名称 | 描述 | 边类型 | 参数 |
|---|---|---|---|---|---|
| 50001 | 2;3 | 负荷预测 | Onnx | http://127.0.0.1:80/forecast/model_96_96.onnx |
边2类型为Onnx,将节点2输入的数据作为神经网络的输入,经过model.onnx后输出数据至节点3。注意,需在mems的www文件下创建forecast文件夹,并将model_96_96.onnx放入其中。
(3)预测结果写入scada数据源
Onnx计算后的输出数据是名为mat_1_1_96的1*1*96大小的DataFrame,而写入scada数据源的DataFrame需包含“point”和“analog”两列信息,因此需要数据处理,具体如下:
1)获取目标测点ID
测点配置中,已配置ID为200001-200096的测点用于保存计算后的未来一天96个点的负荷预测功率,用Source_Meas节点类型获取其ID,如下所示:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数1 | 参数2 |
|---|---|---|---|---|---|
| 50001 | 4 | input_poindID | Source_Meas | select id from meas where id between 200001 and 200096 order by id asc |
节点4类型为Source_Meas,表示获取量测表信息。参数2中的sql语句含义:获取量测表中测点ID为200001至200096的测点的ID,并按ID大小进行排序。
然后,通过类型为Eval的边3(节点4→节点5)对获取的张量改名,如下所示:
| DFF ID | 首尾节点 | 边名称 | 描述 | 边类型 | 参数 |
|---|---|---|---|---|---|
| 50001 | 4;5 | output_pointID | Eval | select(alias(col(`id`), `point`)); |
2)Onnx预测结果数据处理
| DFF ID | 首尾节点 | 边名称 | 描述 | 边类型 | 参数 |
|---|---|---|---|---|---|
| 50001 | 3;5 | prediction_value | Eval | select(alias(col(`mat_1_1_96`), `analog`)); |
边4(节点3→节点5)类型为Eval,表示将名为mat_1_1_96的张量改名为analog。
3)数据拼接
| DFF ID | 节点ID | 名称 | 节点类型 | 参数1 | 参数2 |
|---|---|---|---|---|---|
| 50001 | 5 | 准备输出预测结果 | TensorEval | prediction_meas = concat(horizontal, output_pointID,prediction_value); | 4 |
节点5类型为TensorEval,通过concat函数将output_pointID、prediction_value两个张量拼接为一个张量。
4)数据写入scada数据源
| DFF ID | 首尾节点 | 边名称 | 描述 | 边类型 | 参数 |
|---|---|---|---|---|---|
| 50001 | 5;6 | 结果写入scada数据源 | WriteFile | meas://0 |
边5(节点5→节点6)类型为WriteFile,表示将结果写入scada数据源的指点测点中。
4、预测结果查看
运行负荷预测的DataFrame流,在仪表盘-报表页面可查询计算结果,选择表格展示形式,如下图所示:
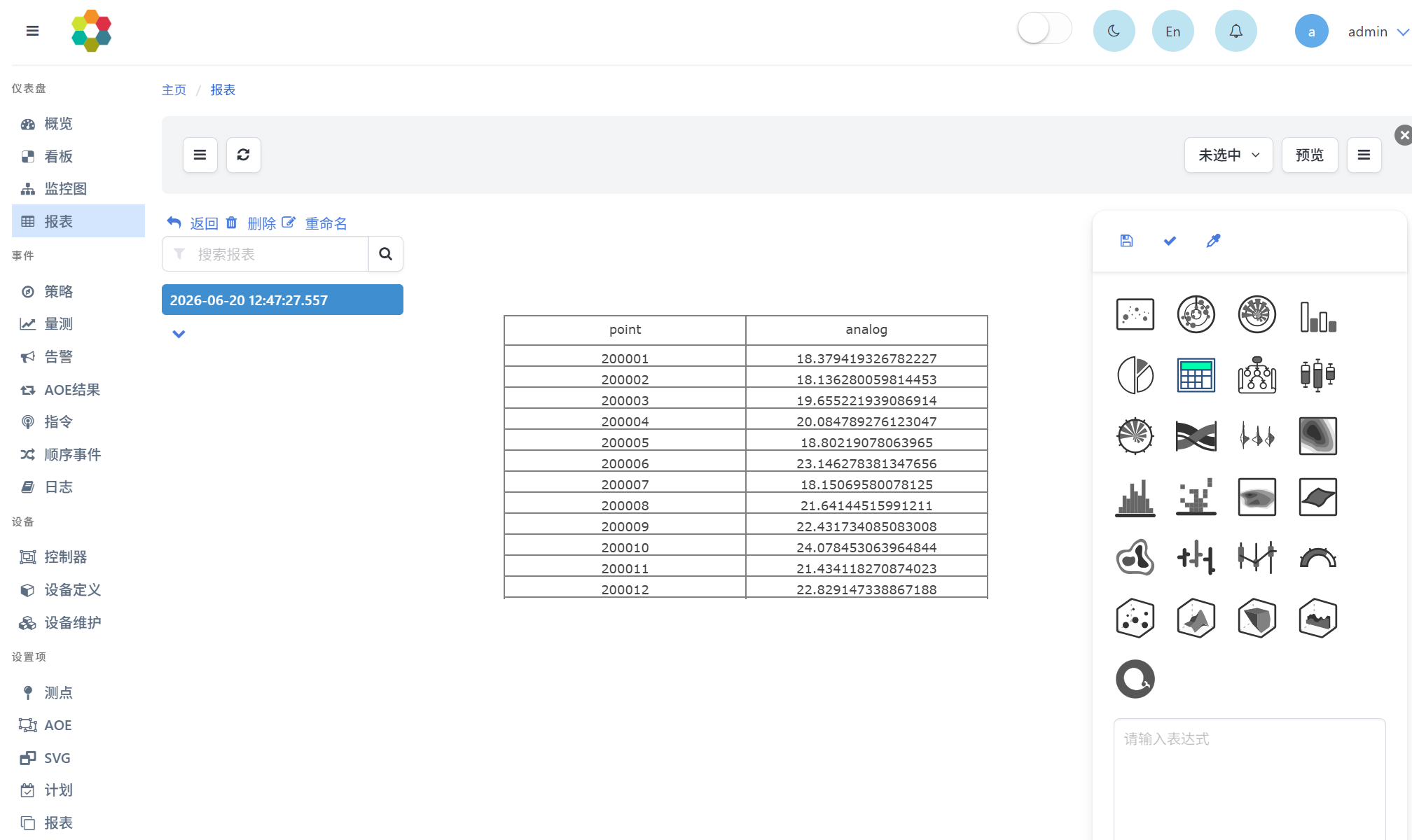
也可在事件-量测页面中选择scada数据源。可查询测点量测值,如下图所示:
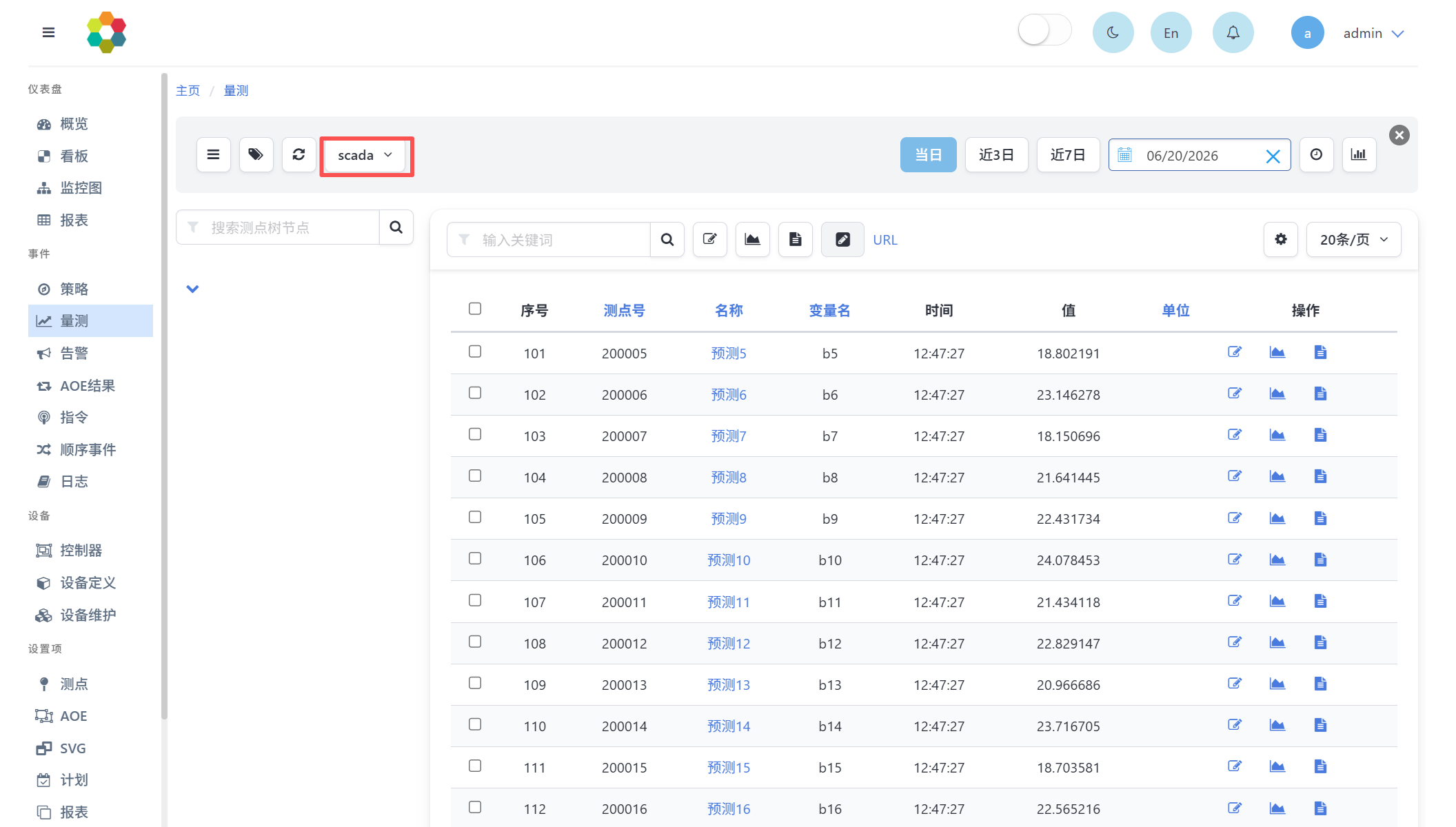
以下附件中提供了上述负荷预测的DataFrame流的配置文件,可参考使用。
附件:负荷预测案例.zip