5.6 负荷预测
1、案例概况
本案例介绍利用MEMS实现负荷预测,包括从scada数据源获取负荷功率量测数据、Onnx神经网络计算、预测结果写入scada数据源。
负荷预测是基于历史用电数据与相关影响因素,对电力系统未来特定时段的负荷需求进行科学估计的技术。本案例中,MEMS首先通过数据源节点接入过去一天共96个采样点的历史负荷数据,然后在计算链路中调用已训练好的Onnx模型节点执行推理,最后输出未来一天96个点的负荷预测功率。
2、测点配置
负荷预测案例中,需要配置量测信息:历史数据测点(100001-100096)用于记录过去一天共96个采样点的,以及预测测点(200001-200096)用于保存计算后的未来一天96个点的负荷预测功率。
注:本案例中采用从量测值的方式获取历史负荷数据,若有其他需求可采用其他数据输入方式,如读表格等。
3、负荷预测配置
在设置项-报表配置实现负荷预测计算的DataFrame流,包括获取历史负荷功率数据、onnx计算、预测结果输出等,以下说明具体配置步骤。
(1)获取历史负荷功率数据
报表配置文件中,在节点1中获取历史负荷功率数据(即value量测值),如下所示:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数1 | 参数2 |
|---|---|---|---|---|---|
| 50001 | 1 | input_value | Source_Meas | select value from meas where id between 100001 and 100096 order by id asc |
节点1类型为Source_Meas,表示获取量测表信息。参数2中的sql语句含义:获取量测表中测点ID为100001至100096的测点的量测值,并按ID大小进行排序。
(2)onnx计算
1)数据预处理
获取历史负荷功率数据后,在边1(节点1→节点2)中对数据进行预处理,以匹配onnx文件的输入数据格式,如下所示:
| DFF ID | 首尾节点 | 边名称 | 描述 | 边类型 | 参数 |
|---|---|---|---|---|---|
| 50001 | 1;2 | 预处理 | Eval | Select(alias(cast(col(value),f32),value_1_1_96)); |
边1类型为Eval,表示将名为value的数据进行强制类型转换为f32类型,并改名为value_1_1_96。
2)Onnx计算
数据预处理后,在边2(节点2→节点3)中执行神经网络计算动作,如下所示:
| DFF ID | 首尾节点 | 边名称 | 描述 | 边类型 | 参数 |
|---|---|---|---|---|---|
| 50001 | 2;3 | 负荷预测 | Onnx | http://127.0.0.1:80/forecast/model_96_96.onnx |
边2类型为Onnx,将节点2输入的数据作为神经网络的输入,经过model.onnx后输出数据至节点3。注意,需在mems的www文件下创建forecast文件夹,并将model_96_96.onnx放入其中。
(3)预测结果写入scada数据源
Onnx计算后的输出数据是名为mat_1_1_96的1*1*96大小的DataFrame,而写入scada数据源的DataFrame需包含“point”和“analog”两列信息,因此需要数据处理,具体如下:
1)获取目标测点ID
测点配置中,已配置ID为200001-200096的测点用于保存计算后的未来一天96个点的负荷预测功率,用Source_Meas节点类型获取其ID,如下所示:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数1 | 参数2 |
|---|---|---|---|---|---|
| 50001 | 4 | input_poindID | Source_Meas | select id from meas where id between 200001 and 200096 order by id asc |
节点4类型为Source_Meas,表示获取量测表信息。参数2中的sql语句含义:获取量测表中测点ID为200001至200096的测点的ID,并按ID大小进行排序。
然后,通过类型为Eval的边3(节点4→节点5)对获取的张量改名,如下所示:
| DFF ID | 首尾节点 | 边名称 | 描述 | 边类型 | 参数 |
|---|---|---|---|---|---|
| 50001 | 4;5 | output_pointID | Eval | select(alias(col(`id`), `point`)); |
2)Onnx预测结果数据处理
| DFF ID | 首尾节点 | 边名称 | 描述 | 边类型 | 参数 |
|---|---|---|---|---|---|
| 50001 | 3;5 | prediction_value | Eval | select(alias(col(`mat_1_1_96`), `analog`)); |
边4(节点3→节点5)类型为Eval,表示将名为mat_1_1_96的张量改名为analog。
3)数据拼接
| DFF ID | 节点ID | 名称 | 节点类型 | 参数1 | 参数2 |
|---|---|---|---|---|---|
| 50001 | 5 | 准备输出预测结果 | TensorEval | prediction_meas = concat(horizontal, output_pointID,prediction_value); | 4 |
节点5类型为TensorEval,通过concat函数将output_pointID、prediction_value两个张量拼接为一个张量。
4)数据写入scada数据源
| DFF ID | 首尾节点 | 边名称 | 描述 | 边类型 | 参数 |
|---|---|---|---|---|---|
| 50001 | 5;6 | 结果写入scada数据源 | WriteFile | meas://0 |
边5(节点5→节点6)类型为WriteFile,表示将结果写入scada数据源的指点测点中。
4、预测结果查看
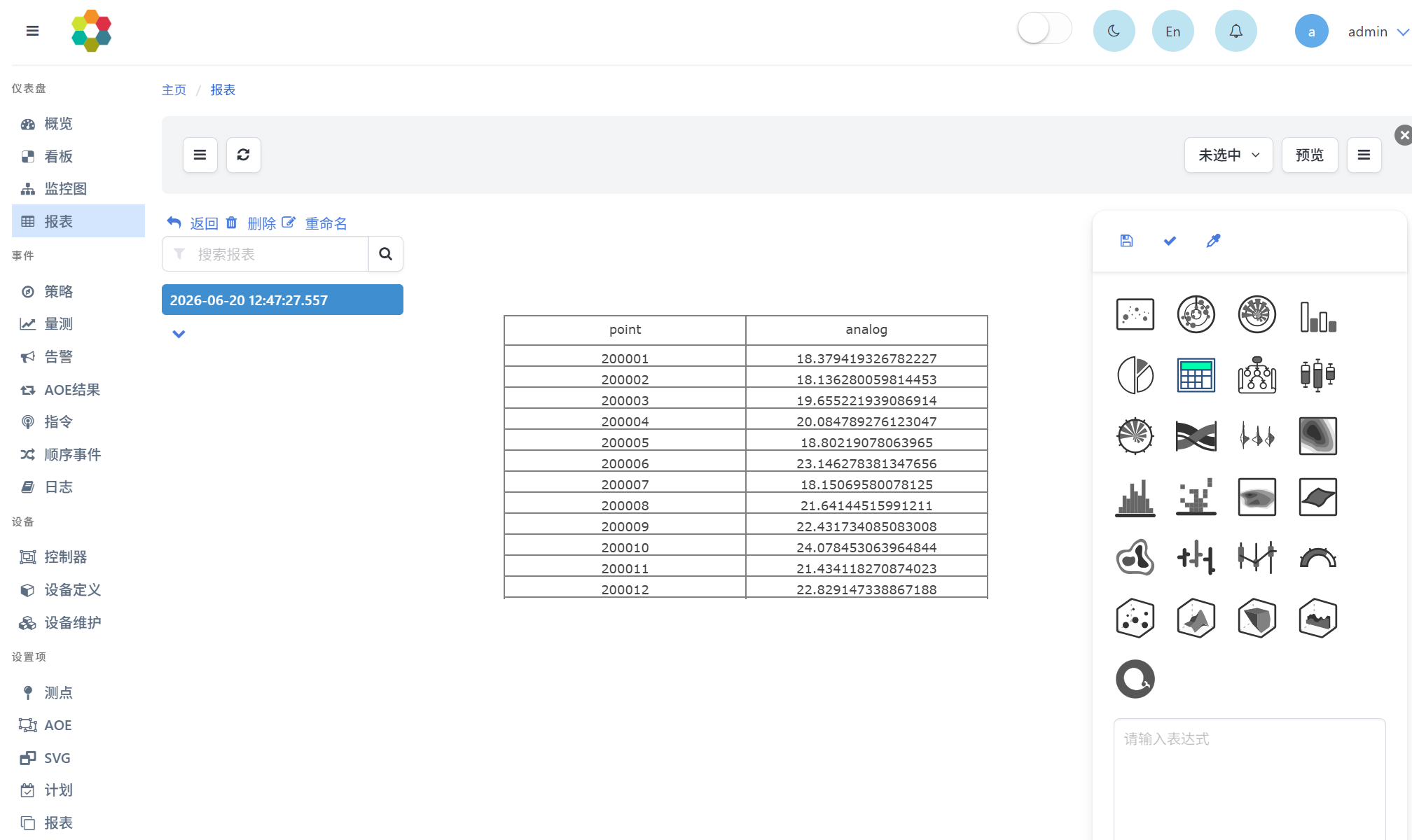
运行负荷预测的DataFrame流,在仪表盘-报表页面可查询计算结果,选择表格展示形式,如下图所示:
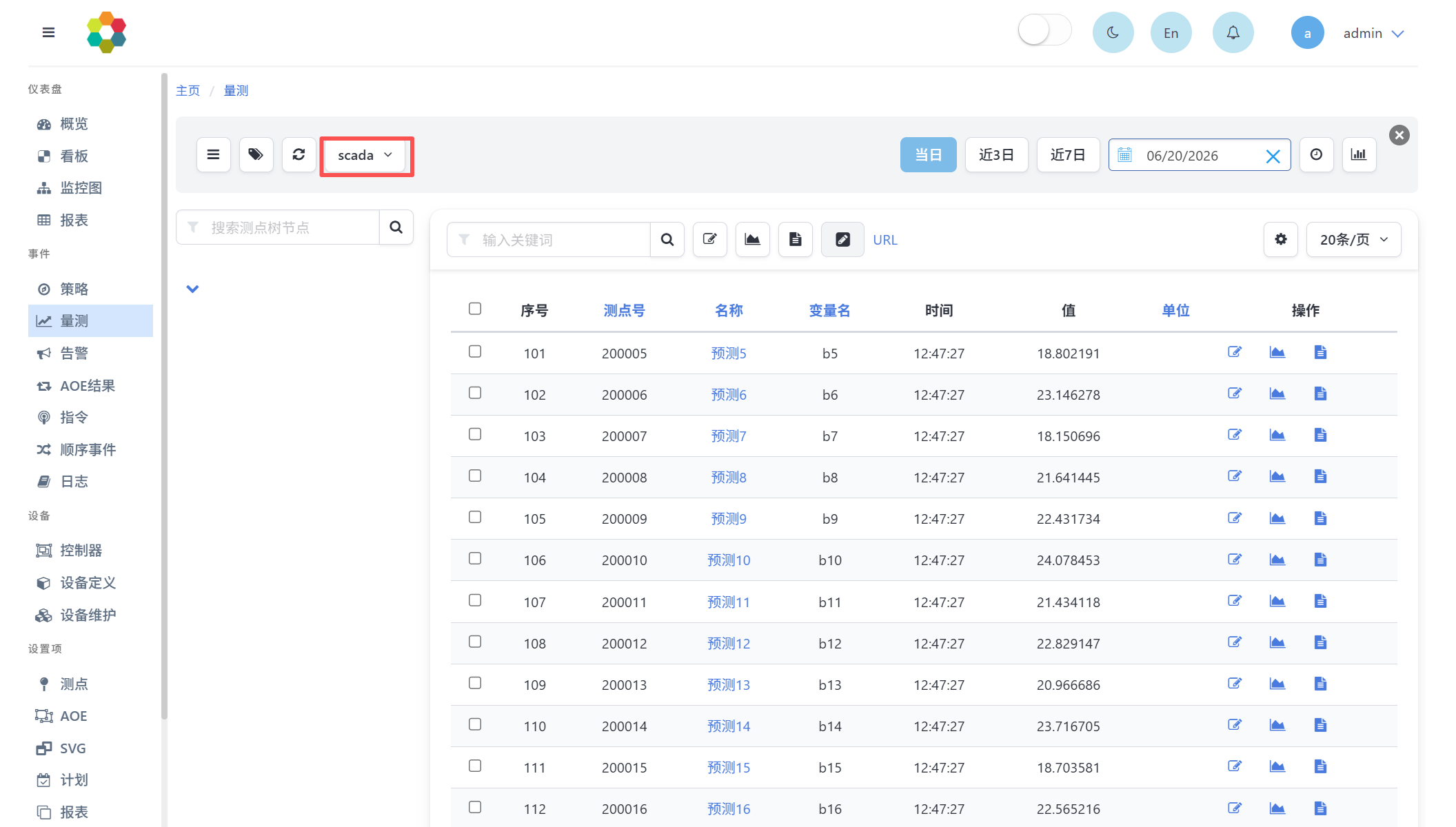
也可在事件-量测页面中选择scada数据源。可查询测点量测值,如下图所示:
以下附件中提供了上述负荷预测的DataFrame流的配置文件,可参考使用。
附件:负荷预测案例.zip