5.1 一致性算法
1、案例概况
本案例介绍在多个mems之间实现一致性算法,分布式计算平均值,包括mems通信配置、一致性算法配置、不同mems的DataFrame流数据交互配置。
分布式计算平均值指网络中每个节点仅与邻居通信,通过迭代使所有节点的状态值收敛到初始值的平均值。一致性算法的节点更新规则为每个节点将其值更新为自身与邻居值的加权平均,例如:
x_i(t+1) = x_i(t) + ε Σ(x_j(t) - x_i(t))
其中x_i(t)为节点i在第t次更新后的值,ε为步长。
当通信图是连通图,且步长选择合适时,所有x_i会渐近收敛到初始值的算术平均。这是异步、去中心化的计算,但通常需要多轮迭代才能达到足够精度。
2、mems通信配置
为建立2个mems之间的通信,需要在其中1个mems中配置另一个mems的监听接口。假设2个mems的beeId分别为node1和node2,后续描述使用node1和node2指代2个mems。在node1界面设置项-云-云端2 请求响应URL中配置node2的北向接口,如下图所示:
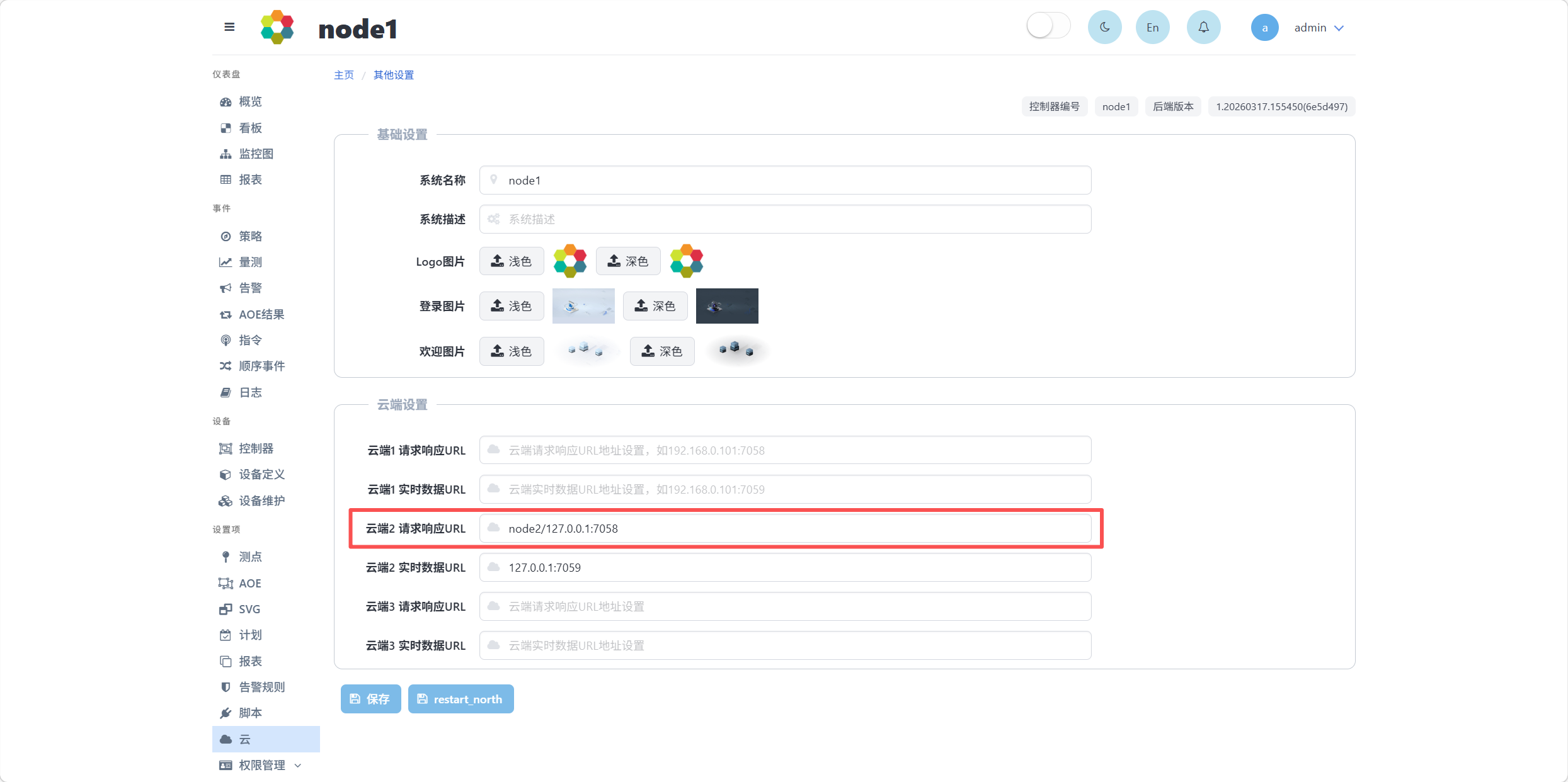
其中,node2为另一个mems的beeId,127.0.0.1:7058为北向接口的IP和端口。
3、一致性算法配置
(1)接收其他mems的DataFrame数据配置
在一致性算法中,每个节点在收到所有相邻节点的数据后需要进行更新计算,因此DataFrame流计算需由其他mems的数据驱动,接收其他mems数据的配置如下图所示:

该DataFrame流的触发条件为DataSource,表示数据源驱动。节点1类型为SOURCE_OTHER,参数为0,表示接收其他mems的数据。这里注意如果是接收自身其他DataFrame流的数据则参数设为其他DataFrame流的id。
若mems有多个相邻节点,则触发条件参数需要填写该DataFrame流中接收其他mems数据的所有节点编号,并用;分割,例如:本mems中节点1和节点2接收其他mems的数据,则该DataFrame流的触发条件参数填写1;2。
(2)获取本地当前值
本案例将一致性算法需要更新的值存储在测点中,因此在每次更新时需要从测点获取本地当前值,如下图所示:

(3)计算更新量和新值
根据本地值和从其他mems收到的值计算更新量和新值,节点和边配置如下图所示:


上图中将ε设为了0.05。
(4)将新值写入本地测点
将更新后的新值写入本地测点,节点和边配置如下图所示:


(5)判断计算是否收敛
基于更新量判断计算是否收敛,若未收敛则将邻居发送本节点的新值,若收敛则停止向邻居发送数据,对应节点和边配置如下图所示。


通过Writefile类型的边实现向其他mems发送DataFrame,参数写法中mems://表示是写到其他mems,后面分别是其他mems的beeid、DataFrame流id和节点id。只有在边接收到非空的DataFrame,才会向其他mems发送数据。上图中node1的对应DataFrame流id为65550,数据源节点id为1。
上图中,在节点6判断若最大更新值小于阈值0.001,则计算收敛,否则计算未收敛。当计算收敛时,节点返回一个空的DataFrame给到边6;7,控制一致性算法停止迭代。
(6)一致性算法计算触发
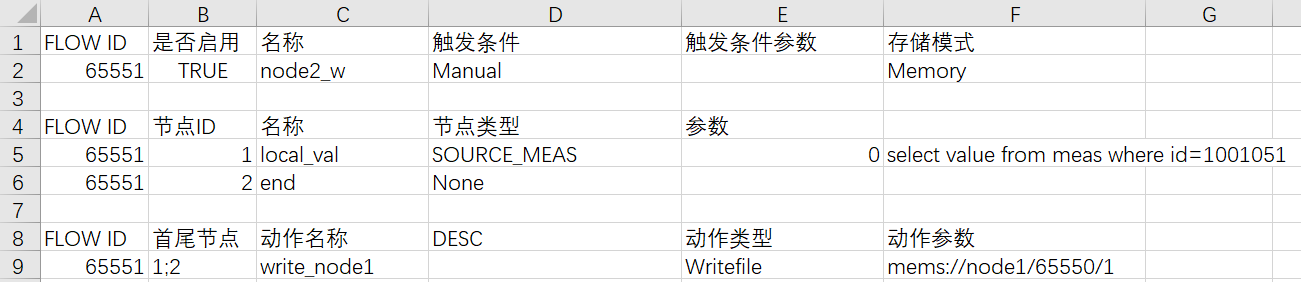
通过上述配置,在计算开始后,不同mems的数据源驱动的DataFrame流可相互触发,但首次计算需要外部条件触发。可通过配置手动触发的DataFrame流向其中部分mems写入数据,触发首次计算,如下图所示。
4. 一致性算法计算结果查看
运行各mems的一致性算法DataFrame流,在事件-量测页面可查看测点值的迭代变化过程及最终结果。
以下附件中提供了一个3节点的一致性算法DataFrame流的配置文件案例,可参考使用。
附件:一致性算法案例.zip