4.5.2 DFF节点定义
DFF节点定义部分的配置内容包括DFF ID、节点ID、名称、节点类型及其参数。
| DFF ID | 节点ID | 名称 | 节点类型 | 参数 |
|---|---|---|---|---|
| <u64> | <u64> | <String> | None Source Transform TensorEval Sql Solve NLSolve MILP NLP Wasm | < \ > <String> <String> <String> <String> <String> <String> <String> <String> <String> |
-
DFF ID:声明节点属于哪个DFF,用<u64>(64位无符号整数)表示。
-
节点ID:一个DFF配置下节点编号。
-
名称:便于理解节点内容,往往是对节点功能的简要文字解释,用<String>(表示字符串类型)表示。
-
节点类型:用约定的类型声明表示,包含如下类型:None、Source、Transform、TensorEval、Sql、Solve、NLSolve、MILP、NLP、Wasm。
-
节点类型参数:不同节点类型的参数配置要求不同,具体要求如下。
节点类型示例说明
一、None
节点类型为None时,表示在节点中不对数据进行操作,直接输出数据。
二、Source
节点类型为Source时,该节点可实现查询和获取数据作为数据源输入的操作。选择该类型后需继续选择数据源类型并填写获取方式,其中数据源类型包括:Meas、Point、File、Url、Data、Dev、Image、Sql、OtherFlow、Plan、PointsEval、MeasEval。
(1)Source_Meas(量测)
在节点类型为Source的节点中,选择DF源类型为Meas时,可以获取量测信息作为数据输入(表格配置中选择Source_Meas类型)。其中,量测信息分为历史量测信息和实时量测信息两种,具体配置方法如下:
1)获取历史量测信息
在参数1中,可采用如下语法获得量测的历史信息:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数1 | 参数2 |
|---|---|---|---|---|---|
| 65536 | 1 | 获取量测历史数据 | Source_Meas | ?id=1000001&start=1775654400000&end=1775655100000 |
节点含义:获取ID为1000001的测点在时间戳1775654400000、1775655100000之间的量测信息。返回的信息为该测点每一次值变化时的的ID、量测值和时间戳。
当需要获取多个测点的量测历史信息时,id参数可以配置多个,如:?id=1000001,1000002&start=1775654400000&end=1775655100000表示获取ID为1000001和1000002的测点在时间戳1775654400000、1775655100000之间的信息。
2)获取实时量测信息
在参数2中,可采用SQL语句的select获得量测的实时信息(参数1需为空),如下:
获取某一测点的量测信息:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数1 | 参数2 |
|---|---|---|---|---|---|
| 65536 | 1 | 获取量测实时信息 | Source_Meas | select * from meas where id = 1000001 |
节点含义:获取ID为1000001的测点的ID、量测值和时间戳(*表示全部信息)。假如此时1000001测点量测值为999,则返回1*3的DataFrame:
| id | value | timestamp |
|---|---|---|
| 1000001 | 999 | 17708606400008 |
注:
*表示量测的全部信息,若仅需返回量测的单个信息或几个信息时,只需将*替换为相应的参数即可,如下:select id,value from meas where id = 1000001表示获取ID为1000001的测点的id和实时量测值;select timestamp from meas where id = 1000001表示获取ID为1000001的测点的时间戳。
获取多个测点的量测信息:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数1 | 参数2 |
|---|---|---|---|---|---|
| 65536 | 1 | 获取量测实时信息 | Source_Meas | select * from meas where id = 1000001 or id = 1000002 |
节点含义:获取ID为1000001和1000002的测点的ID、量测值和时间戳。假如此时1000001测点量测值为999,1000001测点量测值为888,则返回2*3的DataFrame:
| id | value | timestamp |
|---|---|---|
| 1000001 | 999 | 17708606409640 |
| 1000002 | 888 | 17708606407318 |
注:
-
若需查询量测的测点数量较多,可采用如下语法:
select * from meas where id between 1000001 and 1001000,表示返回ID在1000001至1001000之间的所有测点的量测信息。 -
此外,若要求获取的信息按某一顺序排列,可采用
order by xxx asc实现,如:select * from meas where id between 1000001 and 1001000 order by id asc,表示返回ID在1000001至1001000之间的所有测点的量测信息,并按测点ID进行排列。
(2)Source_Point(测点)
在节点类型为Source的节点中,选择DF源类型为Point时,可以获取测点的配置信息作为数据输入(表格配置中选择Source_Point类型)。采用SQL语句获得测点配置信息,具体配置方法如下:
获取某一测点的配置信息:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数 |
|---|---|---|---|---|
| 65536 | 1 | 获取测点配置信息 | Source_Point | select * from points where id = 1000001 |
节点含义:获取ID为1000001的测点全部配置信息(*表示全部信息)。返回1*13的DataFrame(下表测点的具体配置信息为举例):
| id | name | alias | is_discrete | is_computing | data_uni | upper_limit | lower_limit | is_realtime | is_soe | is_remote | timestamp | value |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1000001 | 测点1 | point1 | false | false | MW | 999999 | 0 | true | false | false | 17708606407318 | 0.12 |
注:
*表示测点的全部信息,若仅需返回单个信息或几个信息时,只需将*替换为相应的参数即可,如下:select id,alias,value from meas where id = 1000001表示获取ID为1000001的测点的id、别名和默认值配置信息;select id,is_discrete from meas where id = 1000001表示获取ID为1000001的测点的id、是否离散配置信息。
获取多个测点的配置信息:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数 |
|---|---|---|---|---|
| 65536 | 1 | 获取测点配置信息 | Source_Point | select * from points where id = 1000001 or id = 1000002 |
节点含义:获取ID为1000001和1000002的测点的全部配置信息。返回2*13的DataFrame。
注:
-
若需查询测点数量较多,可采用如下语法:
select * from points where id between 1000001 and 1000010,表示返回ID在1000001至1000010之间的所有测点的配置信息。 -
此外,若要求获取的信息按某一顺序排列,可采用
order by xxx asc实现,如:select * from points where id between 1000001 and 1000010 order by id asc,表示返回ID在1000001至1000010之间的所有测点的配置信息,并按测点ID进行排列。
(3)Source_File(文件)
在节点类型为Source的节点中,选择DF源类型为File时,可以读取文件作为数据输入(表格配置中选择Source_File类型)。具体配置方法为在参数中编辑文件路径,举例如下:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数1 | 参数2 |
|---|---|---|---|---|---|
| 65536 | 1 | 读取文件数据 | Source_File | C:\Users\Desktop\data.xlsx |
节点含义:读取桌面上文件data.xlsx的表格数据。
注:
-
支持xlsx、csv等文件格式的数据读取。
-
文件读入后,表格的表头将作为DataFrame的变量名。
-
当未指定路径,只声明了文件名时,将在
mems.exe所在文件夹中寻找所声明的文件,若不存在将报错。
(4)Source_Url(统一资源定位符,即网络链接)
在节点类型为Source的节点中,选择DF源类型为Url时,可以读取网络链接中的数据作为输入(表格配置中选择Source_Url类型)。具体配置方法为在参数中编辑文件路径,举例如下:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数1 | 参数2 |
|---|---|---|---|---|---|
| 65536 | 1 | 读取Url数据 | Source_Url | https://github.com/shufengdong/sparrowzz/blob/master/data/tetests/input.csv |
节点含义:读入ulr链接input.csv中的数据。
(5)Source_Data(数据)
在节点类型为Source的节点中,选择DF源类型为Data时,可以导入文件作为数据输入。具体配置方法为在DFF配置页面的节点编辑窗口中点击文件导入按钮,然后选择相应文件,如下图所示:
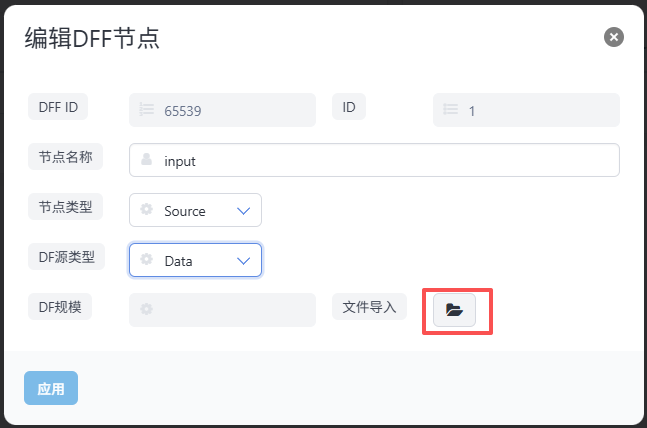
注:
-
Source_Data与Source_File的区别:Source_Data是将文件内容内嵌到报表中(适合静态数据);Source_File是运行时动态读取文件(适合经常变化的数据)。 -
Source_Data会在加载时将文件内容一次性读取并内嵌到报表对象中,适合数据不经常变化的场景;如果数据需要动态更新,应使用Source_File。
(6)Source_Dev(设备)
在节点类型为Source的节点中,选择DF源类型为Dev时,可以读取设备信息作为数据输入(表格配置中选择Source_Dev类型)。具体配置方法可采用SQL语句的select获得设备信息,举例如下:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数1 | 参数2 |
|---|---|---|---|---|---|
| 65536 | 1 | 读取文件数据 | Source_Dev | select `101`,`102`,`103`,`104`,`105`, from Bus order by `101` |
节点含义:读取设备类型为Bus的所有设备的`101`,`102`,`103`,`104`,`105`属性值(每个属性形成一列),并且按`101`属性值进行排序。
注:
- 若需获取某设备的全部属性,可用
*实现,如下:select * from Bus表示获取Bus设备的全部属性值。
三、Transform
节点类型为Transform时,该节点可对节点中的数据进行变换后输出。在节点中可通过变换公式对数据进行变换操作,支持排序、两个表格数据拼接等各类变化操作。举例如下:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数 |
|---|---|---|---|---|
| 65536 | 2 | bus_meas | Transform | join(bus_points,points,[“point”],[“id”],inner) |
节点含义:将bus_points表和points表进行内连接。
四、TensorEval
节点类型为TensorEval时,该节点可用于编写脚本以实现复杂的张量运算,支持张量加、减、乘、幂、求逆、初等函数运算、复数运算、生成矩阵等各类张量运算。举例如下:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数1 | 参数2 |
|---|---|---|---|---|---|
| 65536 | 2 | 数据处理 | TensorEval | a = [[1001001],[1001002]]; b = [[123],[345]]; res_df1 = horzcat(a,b); return res_df1; | 3 |
节点含义:将矩阵a和b水平拼接为矩阵res_df1,并作为该节点的张量输出。其中,参数2中的3,表示脚本支持复数和矩阵运算操作。
注:
-
TensorEval节点所支持的脚本语言为RustScript(一种结合了 Rust 和 MATLAB 语法特征的脚本语言),其语法可以参考RustScript手册。
-
TensorEval节点可以选择配置不同的脚本操作。具体有如下选项:是否Polars、是否复数、是否矩阵、自定义名称、Multi-returns(是否多个返回值)。在表格配置中,通过参数2实现不同的选项,其数字和对应含义如下表所示:
参数2 含义 空 默认,操作选项均不选择 1 脚本支持复数运算 2 脚本支持矩阵运算 3 脚本支持复数和矩阵运算 4 脚本支持Polars运算 5 脚本支持Polars和复数运算 6 脚本支持Polars和矩阵运算 7 脚本支持Polars、复数和矩阵运算 8 脚本支持多个返回值 9 脚本支持多个返回值和复数运算 10 脚本支持多个返回值和矩阵运算 11 脚本支持多个返回值和复数、矩阵运算 12 脚本支持多个返回值和Polars运算 13 脚本支持多个返回值和Polars、复数运算 14 脚本支持多个返回值和Polars、矩阵运算 15 脚本支持多个返回值和Polars、矩阵和复数运算
五、Solve
节点类型为Solve时,可在节点中进行线性方程组的求解运算。举例如下:
举例如下:
方程组
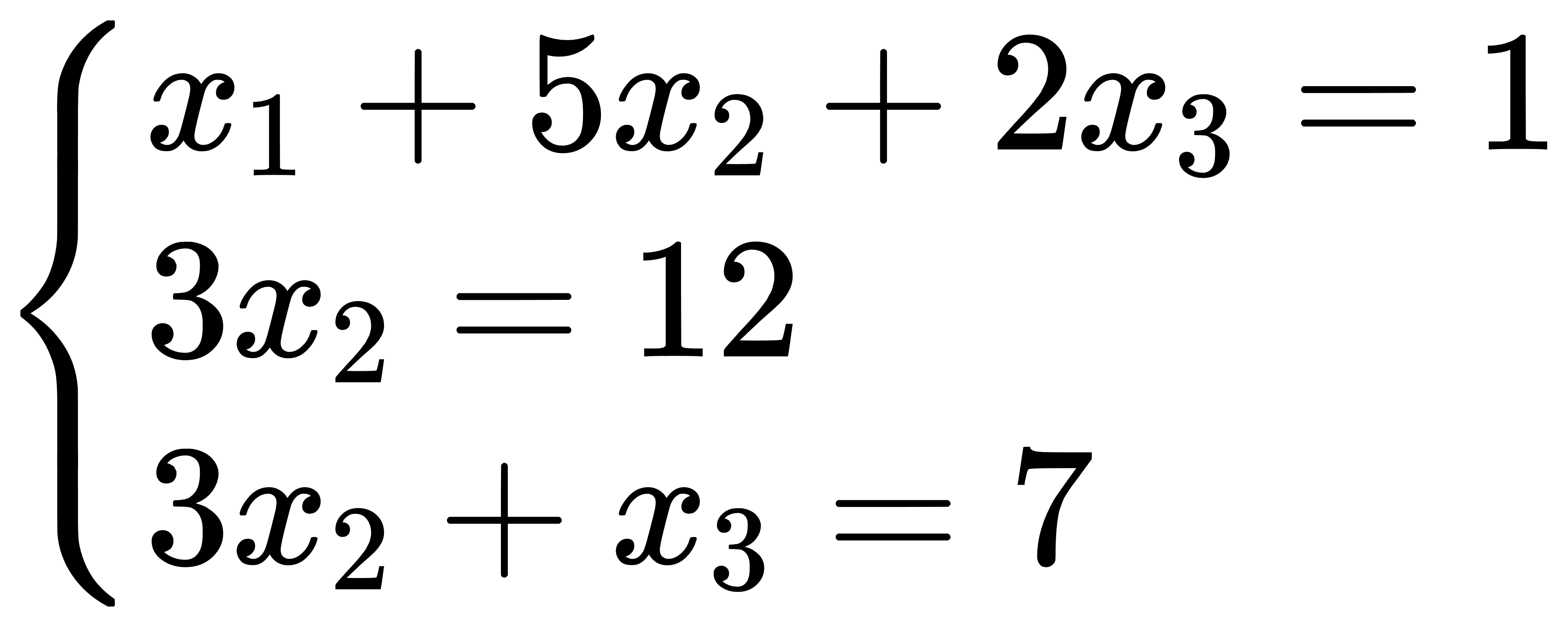
对于以上方程组的求解,DFF配置如下:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数 |
|---|---|---|---|---|
| 65536 | 1 | 系数矩阵 | Source_File | solve.csv |
| 65536 | 2 | 解方程 | Solve | function; |
| FLOW ID | 首尾节点 | 动作名称 | 动作类型 | 动作参数 |
|---|---|---|---|---|
| 65536 | 1;2 | function | None |
方程组系数矩阵(solve.csv)输入如下:
| x1 | x2 | x3 | b |
|---|---|---|---|
| 1 | 5 | 2 | 1 |
| 0 | 3 | 0 | 12 |
| 0 | 3 | 1 | 7 |
节点含义:节点1中方程组系数矩阵,并通过动作1传递到节点2;节点2中对输入的方程组进行求解。求解结果为:
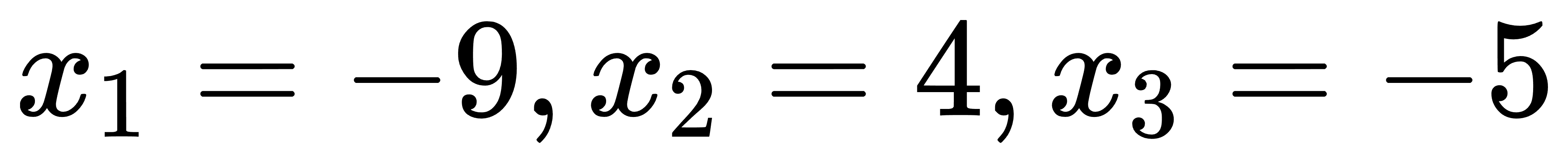
六、NLSolve
节点类型为NLSolve时,可在节点中进行非线性方程组的求解运算。举例如下:
方程组
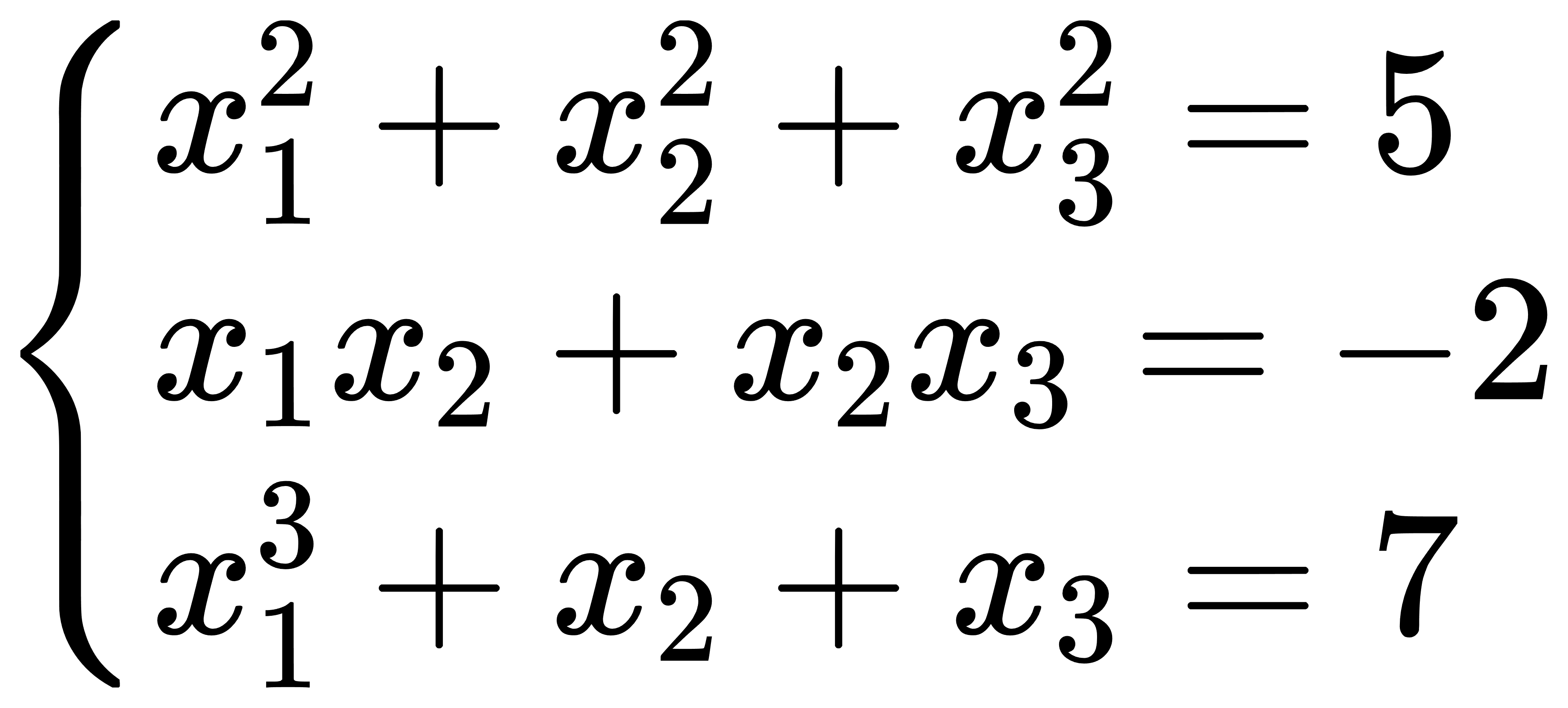
对于以上方程组的求解,DFF配置如下:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数 |
|---|---|---|---|---|
| 65536 | 1 | 方程组输入 | Source_File | NLsolve.csv |
| 65536 | 2 | 解方程 | NLSolve | function; |
| FLOW ID | 首尾节点 | 动作名称 | 动作类型 | 动作参数 |
|---|---|---|---|---|
| 65536 | 1;2 | function | None |
非线性方程组(NLsolve.csv)输入如下:
| x_name | init | equation |
|---|---|---|
| x1 | 1 | x1^2+x2^2+x3^2-5 |
| x2 | -1 | x1*x2+x2*x3+2 |
| x3 | 0 | x1^3+x2+x3-7 |
节点含义:节点1中读入非线性方程组,并通过动作1传递到节点2;节点2中对输入的非线性方程组进行求解。求解结果为:
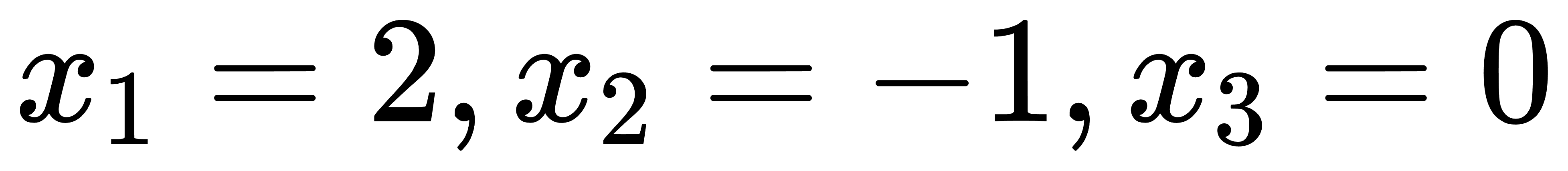
七、MILP
节点类型为MILP时,可在节点中进行混合整数线性规划运算。MILP类型节点至少有2个入边,分别包含混合整数线性规划的目标函数和约束条件数据,数据格式如下:
#1)目标函数:
x type lower upper c
其中:x表示变量名;type表示变量类型,1表示0-1二进制变量,2表示整型变量,3表示实数型变量;lower表示变量下限;upper表示变量上限;c表示变量系数
此外,默认求解最大值(max)。
#2)约束条件:
x1 …… xi b type
其中:x1-xi表示每条约束条件中变量的系数;b表示常量;type为1表示表达式≥0,为-1表示表达式≤0。
举例如下:
目标函数
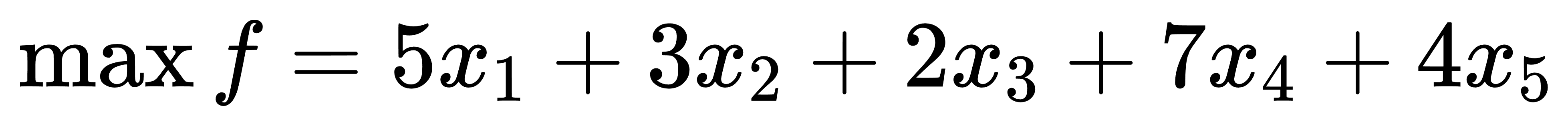
约束条件
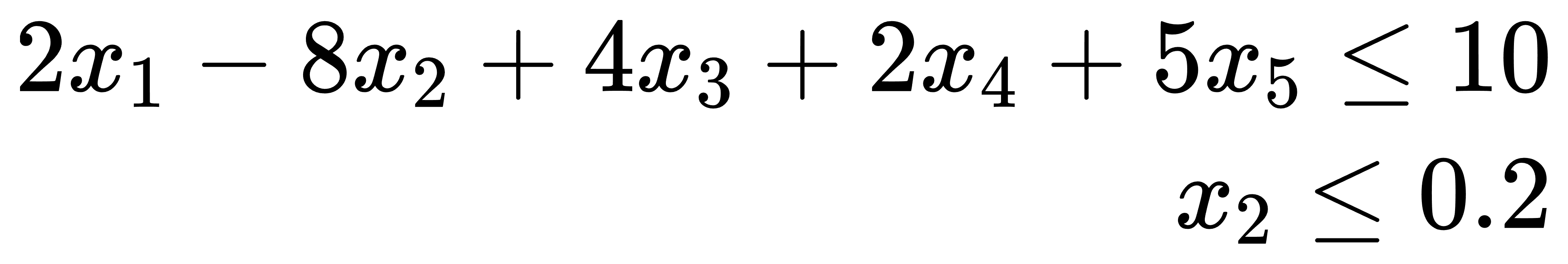
变量类型

对于以上MILP模型的求解,DFF配置如下:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数 |
|---|---|---|---|---|
| 65536 | 1 | 输入目标函数 | Source_File | milp_obj.xlsx |
| 65536 | 2 | 输入约束条件 | Source_File | milp_cons.xlsx |
| 65536 | 3 | 求解 | MILP | obj;constraint; |
| FLOW ID | 首尾节点 | 动作名称 | 动作类型 | 动作参数 |
|---|---|---|---|---|
| 65536 | 1;3 | obj | None | |
| 65536 | 2;3 | constraint | None |
目标函数矩阵(milp_obj.xlsx)输入如下:
| x | type | lower | upper | c |
|---|---|---|---|---|
| x1 | 2 | 0 | 5 | |
| x2 | 3 | 0 | 3 | |
| x3 | 2 | 0 | 2 | |
| x4 | 2 | 0 | 7 | |
| x5 | 2 | 0 | 4 |
约束条件矩阵(milp_cons.xlsx)输入如下:
| x1 | x2 | x3 | x4 | x5 | b | type |
|---|---|---|---|---|---|---|
| 2 | -8 | 4 | 2 | 5 | 10 | -1 |
| 0 | 1 | 0 | 0 | 0 | 0.2 | -1 |
节点含义:节点1中读入目标函数矩阵,并通过动作1传递到节点3;节点2中读入约束条件矩阵,并通过动作2传递到节点3;节点3对输入的MILP矩阵进行求解。求解结果为:
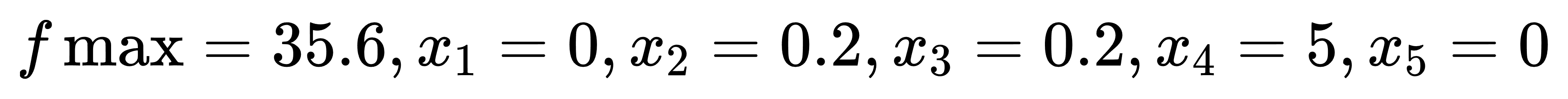
八、NLP
节点类型为NLP时,可在节点中进行非线性规划运算。NLP类型节点至少有2个入边,分别包含非线性规划的变量和表达式数据,数据格式如下:
#1)变量:
x_name lower upper init
其中:x_name表示变量名;lower表示变量下限;upper表示变量上限;init表示变量计算初始值(可为空)。
#2)表达式(目标函数和约束条件):
equations lower upper
其中:equations表示表达式;lower表示表达式的下限(可为空);upper表示表达式的上限(可为空)。
第一行为目标函数(默认计算最小值,无需填写上下限),第二行起表示约束条件。
举例如下:
目标函数
约束条件
变量类型
对于以上NLP模型的求解,DFF配置如下:
| DFF ID | 节点ID | 名称 | 节点类型 | 参数 |
|---|---|---|---|---|
| 65536 | 1 | 输入变量 | Source_File | nlp_x.xlsx |
| 65536 | 2 | 输入目标函数和约束条件 | Source_File | nlp_obj_cons.xlsx |
| 65536 | 3 | 求解 | NLP | nlp_x;nlp_obj_cons; |
| FLOW ID | 首尾节点 | 动作名称 | 动作类型 | 动作参数 |
|---|---|---|---|---|
| 65536 | 1;3 | nlp_x | None | |
| 65536 | 2;3 | nlp_obj_cons | None |
目标函数(nlp_x.xlsx)输入如下:
| x | type | lower | init |
|---|---|---|---|
| x1 | 1 | 5 | |
| x2 | 1 | 5 | |
| x3 | 1 | 5 | |
| x4 | 1 | 5 |
目标函数和约束条件(nlp_obj_cons.xlsx)输入如下:
| equations | lower | upper |
|---|---|---|
| x1 * x4 * (x1 + x2 + x3) + x3 | ||
| x1 * x2 * x3 * x4 | 25 | 2e19 |
| x1^2 + x2^2 + x3^2 + x4^2 | 40 | 40 |
节点含义:节点1中读入NLP的变量配置,并通过动作1传递到节点3;节点2中读入NLP的目标函数和约束条件,并通过动作2传递到节点3;节点3对输入的NLP矩阵进行求解。求解结果为: