数据结构与算法
绪论
2017年春
课程说明
- 本课程是计算机和电力信息技术相关的基础性课程
- 本课程代码主要用c实现,同时也有少量c++的代码供同学们学习
- 要求按时完成实验报告,平时成绩占总成绩的40%。
学习数据结构最有效的方法是:多动手
本次课的内容
我们会阐述课程目的和目标,并简要复习本书所需要的数学知识,我们将要学习到:
- 数据结构的内容
- 为什么要学习数据结构
- 算法及其分析方法
应用实例——学生成绩表管理
学生的成绩表数据如下:
| 学号 | 姓名 | 数学分析 | 普通物理 | 高等代数 | 平均成绩 |
|---|---|---|---|---|---|
| 880001 | 丁一 | 90 | 85 | 95 | 90 |
| 880002 | 马二 | 80 | 85 | 90 | 85 |
| 880003 | 张三 | 95 | 91 | 99 | 95 |
| 880004 | 李四 | 70 | 84 | 86 | 80 |
| 880005 | 王五 | 91 | 84 | 92 | 89 |
我们把上表称为一个数据结构(线性表),表中的每一行是一个结点(或记录),它由学号、姓名、各科成绩及平均成绩等数据项组成。
学生成绩表管理与数据结构
学生成绩表的存储结构则是指用计算机语言如何表示结点之间的这种关系,即表中的结点是顺序邻接地存储在一片连续的单元之中,还是用指针将这些结点链接在一起?
对这张表怎样进行查找、删除、插入,这就是数据的运算问题。
选择问题
接下来的问题是:如何快速根据成绩确定第\(k\)名是谁?
我们将之称为选择问题(selection problem)。大多数学习过程序设计课程的学生写一个解决这种问题的程序不会有什么困难:“显而易见”的解决方法就有很多。
该问题的一种解法就是将这\(n\)个数读进一个数组中,再通过某种简单的算法,比如冒泡排序法,以递减顺序将数组排序,然后返回位置\(k\)上的元素。
稍好一点的算法可以先把前\(k\)个元素读入数组并(以递减的顺序)对其进行排序。接着,将剩下的元素再逐个读入。当新元素被读到时,如果它小于数组中的第\(k\)个元素则忽略,否则就将其放到数组中正确的位置上,同时将数组中的一个元素挤出数组。当算法终止时,位于第\(k\)个位置上的元素作为答案返回。
这两种算法编码都很简单,此时我们自然要问:哪个算法更好?还是两个算法都足够好?遗憾的是,虽然我们提出的两个算法都能计算出结果,但是它们不能被认为是好的算法,想在合理的时间内完成大量输入数据的处理,用这两种算法是不切实际的。
应用实例——人机对弈
对弈问题中,计算机的操作对象是对弈过程中可能出现的棋盘状态——成为格局,格局之间的关系是由对弈规则决定的。例如下图中井字棋的一个格局,从该格局可以派生5个格局,这种格局之间的关系可以用树的数据结构来描述。
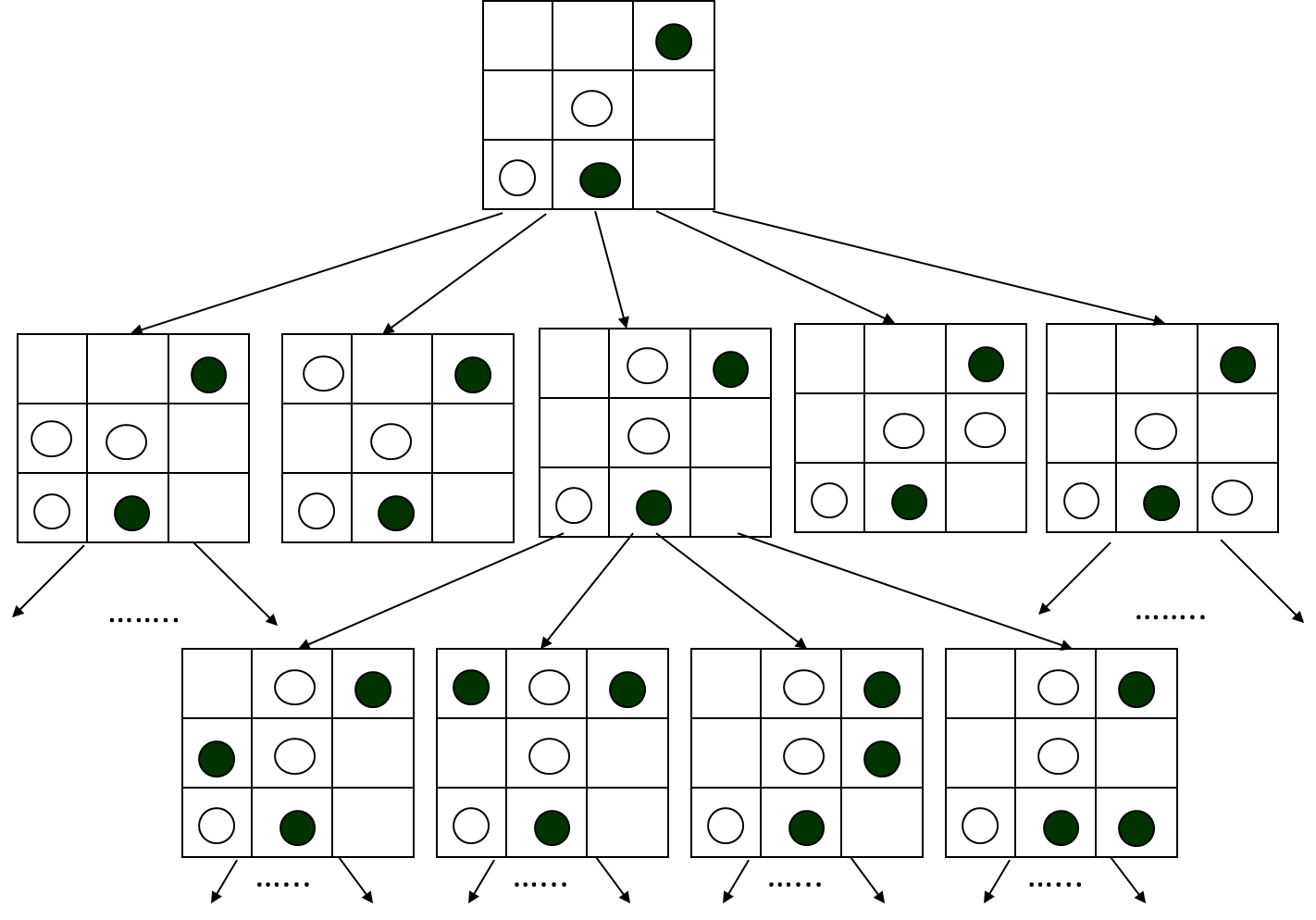
问题:是否存在一种下法保证不会输?如何设计一个智能对弈机器人?
应用实例——铺设城市煤气管道
对于煤气管道的铺设问题,即假设要把\(n\)个地区联成一个煤气管道网络,则需要铺设\(n-1\)条线路。任意两地间可铺设一条线路,\(n\)个城市间最多可能铺设\(n(n-1)/2\)条线路,各条线路的造价一般是不同的。
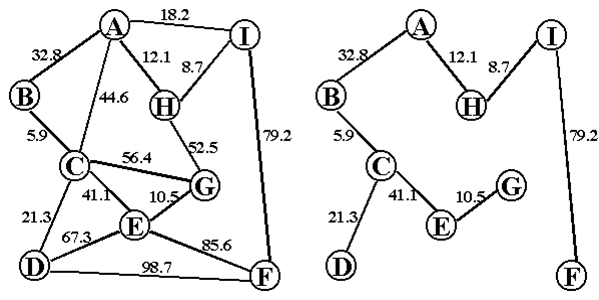
一个很实际的问题:如何在这些可能的线路中选择n-1条使该网络的建造费用最少。
应用实例——电力网络
供电路径
配电网一般具有网状结构,配电网的辐射状结构是配电网重构中的一个重要约束条件,基于路径可以对该条件进行充分和清晰的描述。如何搜索得到配电网中所有供电路径?
电力网络存储
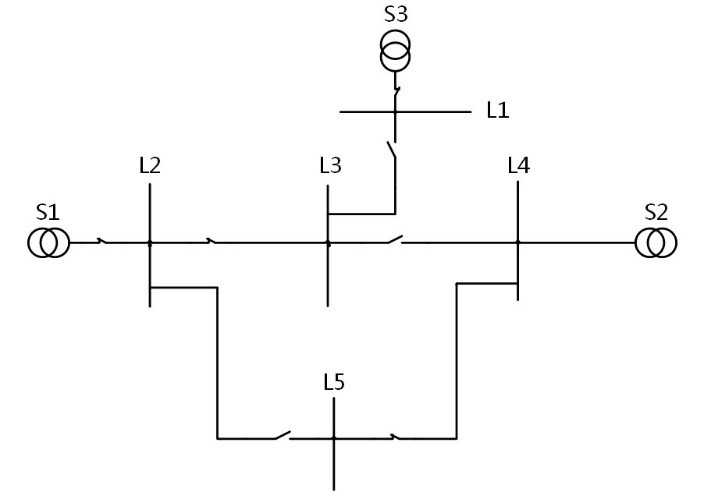
电力网络是一个高度稀疏的网络,如何描述设备之间的拓扑关系及其存储的方法?
数据结构的定义
我们可以将数据结构定义为:
按某种逻辑关系组织起来的一批数据,应用计算机语言,按一定的存储表示方式把它们存储在计算机的存储器中,并在这些数据上定义了一个运算的集合。
数据结构一般包括以下三个方面的内容:
- 数据元素之间的逻辑关系,也称为数据的逻辑结构(Logical Structure)。
- 数据元素及其关系在计算机存储器内的表示,称为数据的存储结构(Storage Structure)。
- 数据的运算,即对数据施加的操作。
学习数据结构的意义
用计算机处理求解任何问题都离不开程序设计,而程序设计的实质是数据表示和数据处理。
数据结构课程主要讨论数据表示和数据处理的基本概念、基本思想和基本方法。学习数据结构可以了解计算机处理对象的特性,将实际问题中所涉及的处理对象在计算机中表示出来并对它们进行处理。
数据表示的核心任务是数据结构设计和算法设计
数据结构和算法讲授的是编程的思想,要是你对编程思想不理解,哪怕你会一千种语言,也写不出好的程序。
想学习编程吗,那就从学习数据结构开始!
本课程培养的能力:技术能力
本课程并不教编程的语法,而是提供解决解决问题的思路,这些思路是众多科学家智慧的结晶,适用于所有编程语言。
当你在编程时遇到运行效率上的瓶颈,亦或是接到一个任务,需要评估这个“东西”能否实现时,这些前人的方案就可以供你参考。例如:
很多涉及后入先出的问题,例如函数递归就是个栈模型、Android的屏幕跳转就用到栈,很多类似的东西,学了栈之后,你就会第一时间想到:我会用栈实现这个功能。
多个网络下载任务,该怎么去调度它们去获得网络资源呢?再例如操作系统的进程(or线程)调度,该怎么去分配资源(像CPU)给多个任务呢?肯定不能全部一起拥有的,资源只有一个,那就要排队!对于先入先出要排队的问题,学了队列之后,你会想到要用队列,那么怎么排队呢?对于那些优先级高的线程怎么办?这时,你就会想到优先队列。
本课程培养的能力:抽象能力
学习数据结构和算法能够指导你如何将数据组织起来。
例如你想把家谱管理起来,就需要对家谱数据进行抽象,将数据分解成树状结构的节点,但是计算机无法理解你的抽象,它不知道这个人的爸爸是他,兄弟是他,计算机中只有0和1,这个节点和那个节点的关系,二者如何互相得到,这是程序员要做的,也是数据结构要教的。因此,了解数据结构,对选择程序结构,选择方案,提出解决方法都有很大帮助。
学习数据结构能够帮助我们提高解决问题的能力。
学习数据结构,也是学习如何将物理世界里的信息变成计算机世界里的数据,并且是高效存储、快速检索的数据,是一个树立计算思维的过程,计算思维是运用计算机科学的基础概念去求解问题、设计系统和理解人类的行为。当我们必须求解一个特定的问题时,首先会问:解决这个问题有多么困难?怎样才是最佳的解决方法?数据结构就是准确地回答这些问题的理论基础。
算法和算法分析
算法的定义:解决某一特定问题的具体步骤的描述,是指令的有限序列。
算法与数据结构的关系紧密,在算法设计时先要确定相应的数据结构,而在讨论某一种数据结构时也必然会涉及实现一定功能的算法。可以从算法特性、算法描述、算法性能分析与度量等三个方面对算法进行考量。
算法的特征
- 有穷性:每一条指令的执行次数必须是有限的。
- 确定性:每条指令的含义都必须明确,无二义性。
- 可行性:每条指令的执行时间都是有限的。
- 输入性:具有零个或多个输入的外界量。
- 输出性:至少产生一个输出。
对算法的要求
- 正确:算法的执行结果应当满足预先规定的功能和性能要求。
- 可读:一个算法应当思路清晰、层次分明、简单明了、易读易懂。
- 健壮:当输入不合法数据时,应能作适当处理,不至引起严重后果。
- 高效:有效使用存储空间和有较高的时间效率。
如何描述算法
- 使用自然语言;
- 使用程序流程图、N-S图等算法描述工具;
- 直接使用某种程序设计语言;
- 使用一种称为伪码语言的描述方法
如何评价算法
评价一个算法的好坏一般从4个方面进行:
- 正确性:是指算法是否正确;
- 运行时间:执行算法所耗费的时间;
- 占用空间:执行算法所耗费的存储空间;
- 简单性:是指算法的易读性等。
我们可以从一个算法的时间复杂度与空间复杂度来评价算法的优劣。
时间复杂度的概念
一个算法所耗费的时间,应该是该算法中每条语句的执行时间之和,而每条语句的执行时间是该语句的执行次数(也称为频度)与该语句执行一次所需时间的乘积。
当算法转换为程序之后,每条语句执行一次所需的时间取决于机器的指令性能、速度以及编译所产生的代码质量,这是很难确定的。我们假设执行每条语句所需的时间均是单位时间,则:一个算法的时间耗费就是该算法中所有语句的频度之和。
计算时间复杂度
例:求两个\(n\)阶方阵的乘积\(C=A×B\),其算法如下:
#define n 自然数
MATRIXMLT(A, B, C)
float A[ ][n], B[ ][n], C[ ][n];
{
int i,j,k;
for(i=0; i<n; i++) (1)
for(j=0; j<n; j++) { (2)
C[i][j] = 0; (3)
for(k=0; k<n; k++) (4)
C[i][j] = C[i][j] + A[i][k]*B[k][j]; (5)
}
}/* MATRIXMLT */其中(1),(2),(3),(4),(5)的算法复杂度分别为\(n+1\),\(n(n+1)\),\(n^2\),\(n^2(n+1)\),\(n^3\)。
该算法中所有语句的频度之和(即算法的时间耗费)为: \[ T(n)= n+1+n(n+1)+n^2+n^2(n+1)+n^3 = 2n^3 +3n^2+2n+1 \] 我们将算法求解问题的输入量(或初始数据量)称为问题的规模(Size,大小),并用一个整数表示。例如,矩阵乘积问题的规模是矩阵的阶数n。
渐进时间复杂度
算法的时间复杂度(也称时间复杂性):是该算法的时间耗费,它是该算法所求解问题规模n的函数。当问题的规模n趋向无穷大时,我们把时间复杂度\(T(n)\)的数量级(阶)称为算法的渐近时间复杂度。
在算法分析时,往往对算法的时间复杂度和渐近时间复杂度不予区分,而经常是将渐近时间复杂度\(T(n)=O(f(n))\)简称为时间复杂度,其中的\(f(n)\)一般是算法中频度最大的语句频度。
例子:计算MATRIXMIL的渐进时间复杂度
\[ T(n)= 2n^3 +3n^2+2n+1 \] \[ \lim_{n\to \infty} T(n)/n^3 = \lim_{n \to \infty} (2n^3 +3n^2+2n+1)/n^3 = 2 \]
上式表明,当\(n\)充分大时,\(T(n)\)和\(n^3\)的数量级相同,可记作\(T(n)=O(n^3)\)。我们称\(T(n)=O(n^3)\)是算法MATRIXMLT的渐近时间复杂度。
常见时间复杂度
按相应的数量级(阶)递增排列:
- 常数阶\(O(1)\)
- 对数阶\(O({log}^n_2)\)
- 线性阶\(O(n)\)
- 线性对数阶\(O(n{log}^n_2)\)
- 平方阶\(O(n^2)\)
- 立方阶\(O(n^3)\)
- \(k\)次方阶\(O(n^k)\)
- 指数阶\(O(2^n)\)
空间复杂度
一个程序的空间复杂度(Space complexity)是指程序运行从开始到结束所需的最大存储量。
程序运行所需的存储空间包括以下两部分:
- 固定部分
这部分空间与所处理数据的大小和个数无关,或者称与问题的实例的特征无关。主要包括程序代码、常量、简单变量、定长成分的结构变量所占的空间。
- 可变部分
这部分空间大小与算法在某次执行中处理的特定数据的大小和规模有关。例如100个数据元素的排序算法与1000个数据元素的排序算法所需的存储空间显然是不同的。
算法设计中的哲学问题
当然我们希望选用一个所占存储空间小、运行时间短、其它性能也好的算法。然而,实际上很难做到十全十美。原因是上述要求通常相互抵触。
要节约算法的执行时间往往要以牺牲更多的空间为代价;而为了节省空间又可能要以更多的时间作代价。因此我们只能根据具体情况有所侧重。
本章作业
- 请复习《C语言》的基础知识,特别是有关“递归”、“指针”和“结构体”方面的内容